



1.聚集索引
InnoDB 的存储引擎是聚集索引组织表,即行数据是按照主键顺序存放在物理磁盘上。而聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的即为整张表的记录数据。聚集索引的叶子节点称为数据页,默认一个block是16kB。
聚集索引可以由一列或多列组成,它的选择规则是这样的:
- 首先选择显式定义的主键索引做为聚集索引;
- 如果没有,则选择第一个不允许NULL的唯一索引;
- 还是没有的话,就采用InnoDB引擎内置的ROWID作为聚集索引;

2.主键设计
在设计表结构时,表一定要显式定义主键,自增主键,或者联合主键,或全局ID。并且索引设置为NOT NULL,如果允许NULL,那么在索引的每条记录上,都要多用一个标记去记录这个列是否是NULL,占用多余的存储空间。
自增主键一般是int或bigint型。
全局ID跟自增ID特性基本相同,但是它的值是从另外的服务获取的数字增长类型,不要UUID。只在有分库(一般有全局统计需求),或其它可能需要全局唯一性的情况下才使用。在做数据迁移或拆库时,可以无缝切换,因为新旧数据id不用担心重复。定义全局ID时,注意字段范围要满足要求,小心溢出。
主键的设计原则:
- 采用一个没有业务用途的自增属性列作为主键;
- 主键字段值总是不更新,只有新增或者删除两种操作;
- 不选择会动态更新的类型,比如当前时间戳等。
这么做的好处有几点:
- 新增数据时,由于主键值是顺序增长的,innodb page发生分裂的概率降低了;
- 业务数据有变更时,不修改主键值,物理存储位置发生变化的概率降低了,innodb page中产生碎片的概率也降低了。
3. 辅助索引
辅助索引又叫非主键索引,辅助索引的叶子节点=键值+书签。书签就是相应行数据的主键索引值。于检索数据时,总是先获取到书签值(主键值),再返回查询,因此辅助索引也被称之为二级索引。
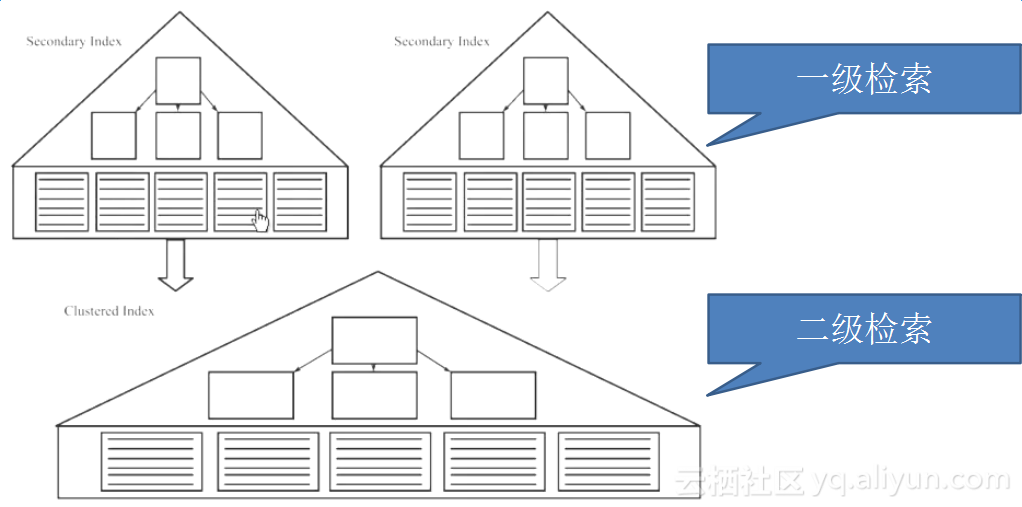
注意:辅助索引里还可以再分为唯一索引,非唯一索引。对于唯一索引,查询时只是需要多一次从辅助索引到主键索引的转换过程。而对于普通索引的查找检索到结果后,还需要至少再多检索一次才能确认是否还有更多符合条件的结果。
使用辅助索引排序
这是写sql的基础的优化手段,利用二级索引的有序性,避免filesort。考虑索引 KEY a_b_c (a, b, c) :
ORDER may get resolved using Index
– ORDER BY a
– ORDER BY a,b
– ORDER BY a, b, c
– ORDER BY a DESC, b DESC, c DESC
WHERE and ORDER both resolved using index:
– WHERE a = const ORDER BY b, c
– WHERE a = const AND b = const ORDER BY c
– WHERE a = const ORDER BY b, c
– WHERE a = const AND b > const ORDER BY b, c
ORDER will not get resolved uisng index (file sort)
– ORDER BY a ASC, b DESC, c DESC /* mixed sort direction */
– WHERE g = const ORDER BY b, c /* a prefix is missing */
– WHERE a = const ORDER BY c /* b is missing */
– WHERE a = const ORDER BY a, d /* d is not part of index */
4.联合索引
MySQL中的索引可以以一定顺序引用多个列,这种索引叫做联合索引,一般的,一个联合索引是一个有序元组,其中各个元素均为数据表的一列。mysql使用联合索引时,从左向右匹配,遇到断开或者范围查询时,无法用到后续的索引列。
比如:从下表可以看到:这里创建了4个索引,其中前3个是主要索引,最后一个是辅助索引
SHOW INDEX FROM employees.titles;
+--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Null | Index_type |
+--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
| titles | 0 | PRIMARY | 1 | emp_no | A | NULL | | BTREE |
| titles | 0 | PRIMARY | 2 | title | A | NULL | | BTREE |
| titles | 0 | PRIMARY | 3 | from_date | A | 443308 | | BTREE |
| titles | 1 | emp_no | 1 | emp_no | A | 443308 | | BTREE |
+--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
这里可以看到,此次查询使用了主要索引,key_len为 4 ,用到的是第一个索引
EXPLAIN SELECT * FROM employees.titles WHERE emp_no=10001;
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
索引从中间断开,则索引从此断开。比如索引 index_num (a, b, c),相当于创建了(a)、(a, b)、(a, b, c) 三个索引。下面这种情况就只用到索引1,索引3用不上
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26';
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
可以使用精确条件( = / in) 填补中间的索引2,或者使用辅助索引
EXPLAIN SELECT * FROM employees.titles
WHERE emp_no='10001'
AND title IN ('Senior Engineer', 'Staff', 'Engineer', 'Senior Staff', 'Assistant Engineer', 'Technique Leader', 'Manager')
AND from_date='1986-06-26';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 7 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
5.覆盖索引 covering index
覆盖索引 主要从辅助索引的设计进行考虑。它指一个查询语句的执行只需要从辅助索引中就可以得到查询记录,而不需要查询聚集索引中的记录。
1> 无 where 条件的查询优化
直接在查询字段上建立索引,这里是在 firstname 上建立了索引。
explain select sql_no_cache count(firstname) from tb2\G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | tb2
type | index
possible_keys | <null>
key | firstname_lastname4
key_len | 61
ref | <null>
rows | 14
Extra | Using index
从执行计划,我们看到,Using index表示使用到了索引,Possible_keys为null,说明没有使用二次检索。直接从辅助索引中获取数据,减少了读取的数据块的数量。这种查询要求查询的字段数足够少,方便一一对这些字段建立索引。
2> 有 where 条件的查询优化 / 二次检索优化
这里只对其中的 firstname 建立了索引,而未对 lastname 建立索引。
explain select lastname from tb2 where firstname="li"\G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | tb2
type | ref
possible_keys | firstname
key | firstname
key_len | 42
ref | const
rows | 1
Extra | Using index condition
从执行计划中,我们可以看到 Using index condition而不是Using index,这说明,使用的检索方式为二级检索,即检索出所有 firstname="li" 的书签值,再回表查询。
我们可以进一步对where 中的 firstname 与返回字段 lastname 建立联合索引,实现索引覆盖,避免二次检索。
alter table tb2 add index (firstname, lastname);
explain select lastname from tb2 where firstname="li"\G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | tb2
type | ref
possible_keys | firstname,firstname_2
key | firstname_2
key_len | 42
ref | const
rows | 1
Extra | Using where; Using index
3> 分页查询优化
通常比较常规的优化手段就是查询改写,这里主要介绍一下新的思路,就是通过索引覆盖来优化。比如下面这个查询
查询消耗:
mysql> select tid,return_date from t1 order by inventory_id limit 50000,10;
+-------+---------------------+
| tid | return_date |
+-------+---------------------+
| 50001 | 2005-06-17 23:04:36 |
| 50002 | 2005-06-23 03:16:12 |
| 50003 | 2005-06-20 22:41:03 |
| 50004 | 2005-06-23 04:39:28 |
| 50005 | 2005-06-24 04:41:20 |
| 50006 | 2005-06-22 22:54:10 |
| 50007 | 2005-06-18 07:21:51 |
| 50008 | 2005-06-25 21:51:16 |
| 50009 | 2005-06-21 03:44:32 |
| 50010 | 2005-06-19 00:00:34 |
+-------+---------------------+
10 rows in set (0.75 sec)
查看执行计划:
mysql> explain select tid,return_date from t1 order by inventory_id limit 50000,10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1023675
1 row in set (0.00 sec)
分析与优化:全表扫描,加上额外的排序,相信产生的性能消耗是不低的。考虑创建一个索引,包含排序列以及返回列,由于tid是主键字段,因此该复合索引也包含了tid的字段值。
mysql> alter table t1 add index liu(inventory_id,return_date);
Query OK, 0 rows affected (3.11 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> analyze table t1\G
*************************** 1. row ***************************
Table: sakila.t1
Op: analyze
Msg_type: status
Msg_text: OK
1 row in set (0.04 sec)
查看消耗:添加复合索引后,速度提升0.7s!
mysql> select tid,return_date from t1 order by inventory_id limit 50000,10;
+-------+---------------------+
| tid | return_date |
+-------+---------------------+
| 50001 | 2005-06-17 23:04:36 |
| 50002 | 2005-06-23 03:16:12 |
| 50003 | 2005-06-20 22:41:03 |
| 50004 | 2005-06-23 04:39:28 |
| 50005 | 2005-06-24 04:41:20 |
| 50006 | 2005-06-22 22:54:10 |
| 50007 | 2005-06-18 07:21:51 |
| 50008 | 2005-06-25 21:51:16 |
| 50009 | 2005-06-21 03:44:32 |
| 50010 | 2005-06-19 00:00:34 |
+-------+---------------------+
10 rows in set (0.03 sec)
查看(改进后的)执行计划:使用了复合索引,不需要回表
mysql> explain select tid,return_date from t1 order by inventory_id limit 50000,10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: index
possible_keys: NULL
key: liu
key_len: 9
ref: NULL
rows: 50010
1 row in set (0.00 sec)
上面的是针对返回字段不多的情况,如果字段很多,需要使用 inner join 建立索引的表
查询改写的思想是通过索引消除排序,然后与 原表 inner join。
select a.tid,a.return_date from t1 a
inner join
(select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid; -- 主键是递增的,并且附带在了每个二级索引后面
我们需要为inventory_id列创建索引,并删除之前的覆盖索引
mysql> alter table t1 add index idx_inid(inventory_id),drop index liu;
查询消耗,这种优化手段较前者时间消耗多了大约140ms。
mysql> select a.tid,a.return_date from t1 a inner join (select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid;
+--------+---------------------+
| tid | return_date |
+--------+---------------------+
| 800001 | 2005-08-24 13:09:34 |
| 800002 | 2005-08-27 11:41:03 |
| 800003 | 2005-08-22 18:10:22 |
| 800004 | 2005-08-22 16:47:23 |
| 800005 | 2005-08-26 20:32:02 |
| 800006 | 2005-08-21 14:55:42 |
| 800007 | 2005-08-28 14:45:55 |
| 800008 | 2005-08-29 12:37:32 |
| 800009 | 2005-08-24 10:38:06 |
| 800010 | 2005-08-23 12:10:57 |
+--------+---------------------+
http://imysql.com/2015/11/11/mysql-faq-primary-key-vs-secondary-key.shtml
https://yq.aliyun.com/articles/62419

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









