






 本文介绍如何在Scrapy爬虫中结合Selenium来解决动态网页数据抓取的问题,通过自定义中间件实现随机更换User-Agent和代理IP,同时在中间件中引入Selenium以执行JavaScript获取数据。
本文介绍如何在Scrapy爬虫中结合Selenium来解决动态网页数据抓取的问题,通过自定义中间件实现随机更换User-Agent和代理IP,同时在中间件中引入Selenium以执行JavaScript获取数据。
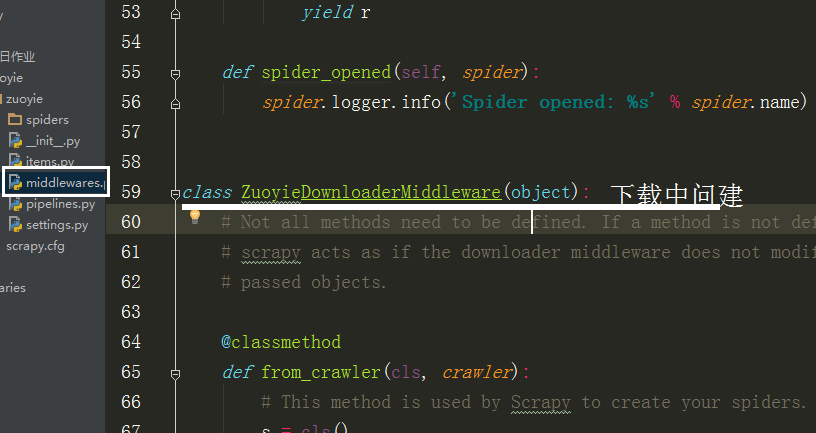


因为每次请求得到的响应不一定是正常的,

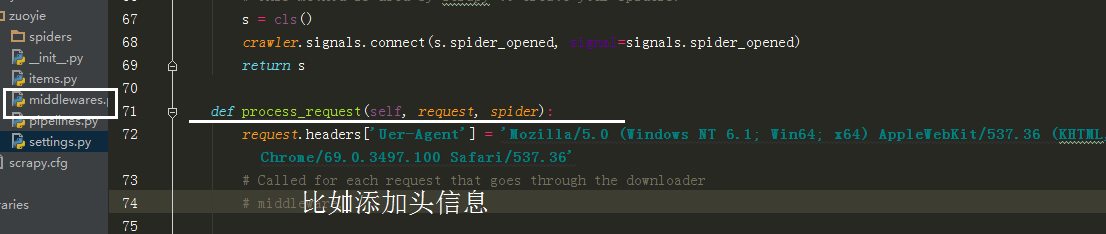
也可以在中间建中与个类的方法,自动更换头自信,代理Ip,
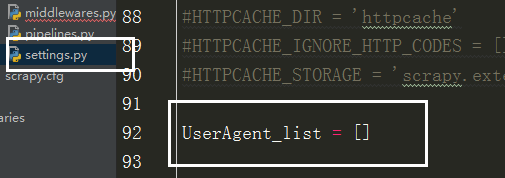
在设置文件中添加头信息列表,
在中间建中导入刚刚的列表,和随机函数
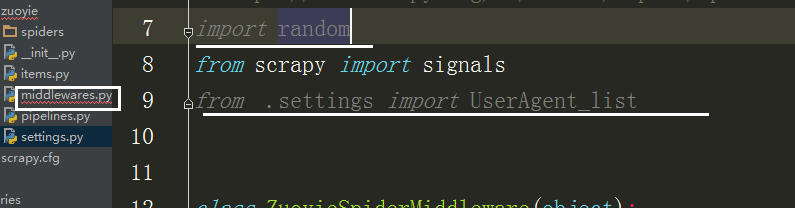
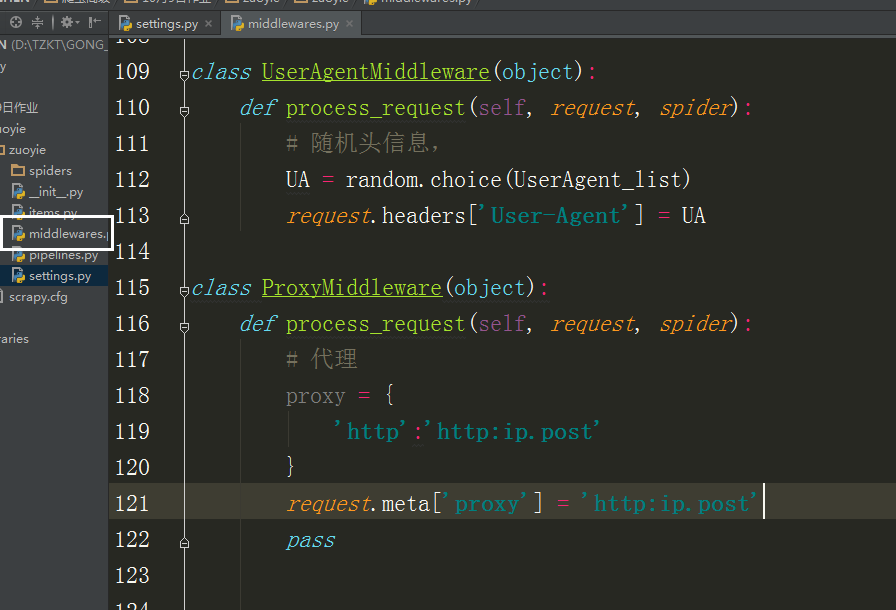
class UserAgentMiddleware(object):
def process_request(self, request, spider):
# 随机头信息,
UA = random.choice(UserAgent_list)
request.headers['User-Agent'] = UA
class ProxyMiddleware(object):
def process_request(self, request, spider):
# 代理
proxy = {
'http':'http:ip.post'
}
request.meta['proxy'] = 'http:ip.post'
pass
scrapy与 selenium
以 历史空气质量数据 网站为列:
https://www.aqistudy.cn
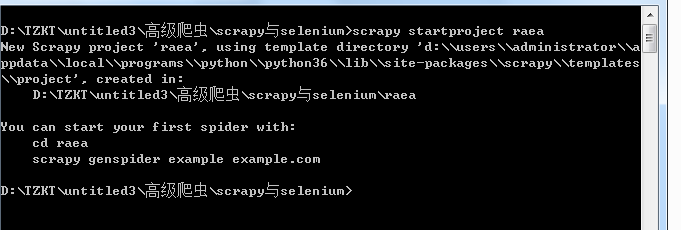
建一项目 scrapy startproject raea
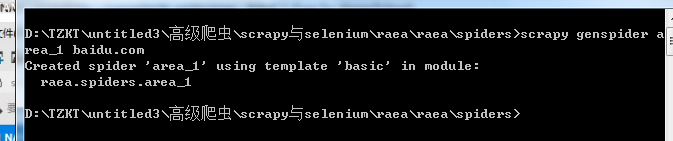
创建运行文件 scrapy genspider area_1 baidu.com
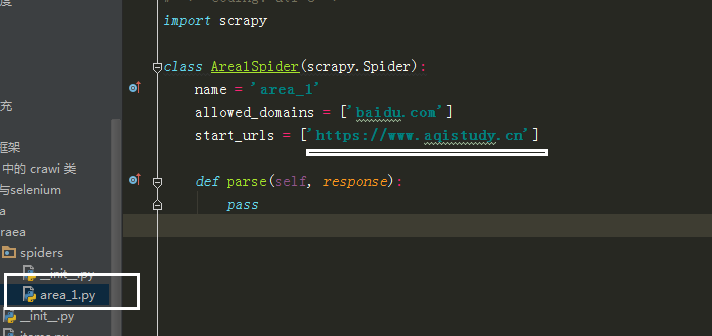
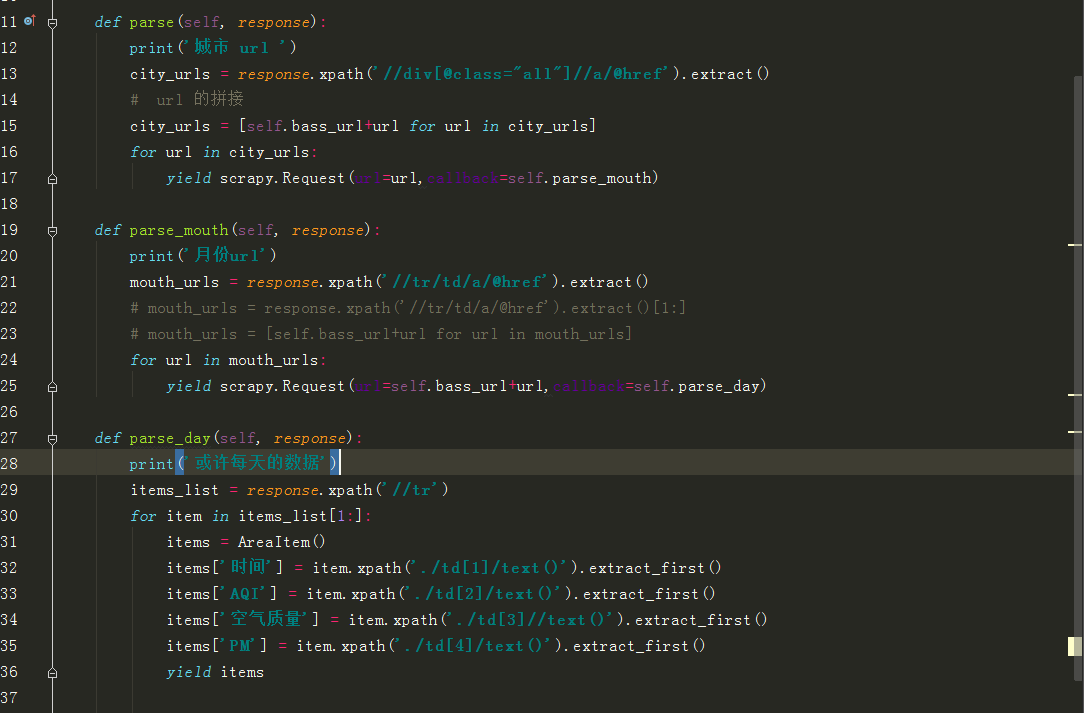
写好后无法获取数据,是因为 scrapy 无法执行 js 获取数据 ,
所以要在中间建 中自己写个类,
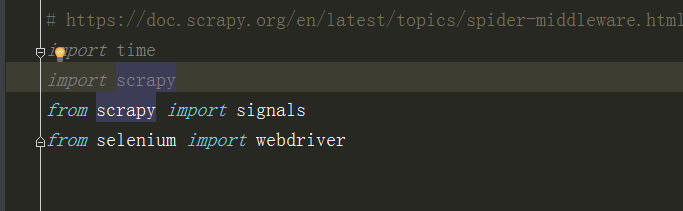
在 middlewares 中导入selenium
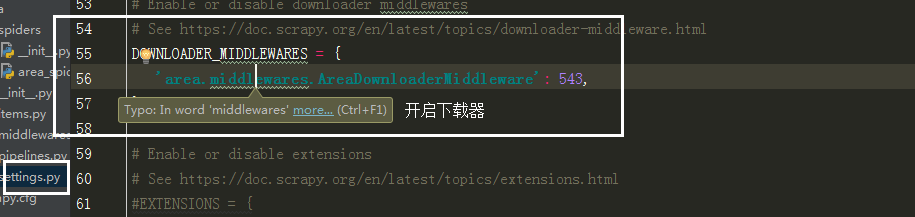
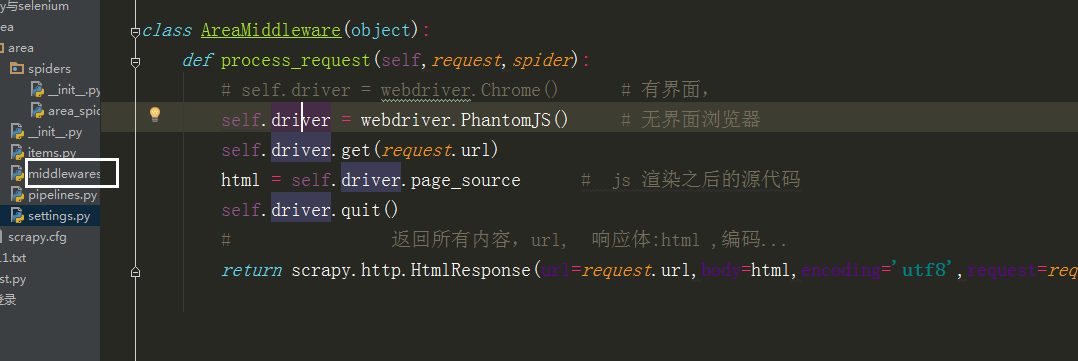
里边的类名改成自己写的那个类方法



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









