



 本文介绍了RabbitMQ的基本概念,包括其作为消息中间件的角色、工作原理及架构组成。此外,还详细解释了四种主要的交换机类型:fanout、direct、topic和headers的工作方式。
本文介绍了RabbitMQ的基本概念,包括其作为消息中间件的角色、工作原理及架构组成。此外,还详细解释了四种主要的交换机类型:fanout、direct、topic和headers的工作方式。
一:何为RabbitMQ?
作为Windows忠实用户,不得不提微软自带的MSMQ,Windows自带的一个服务,message是存放在文件系统的,这是最原始的消息队列了。
然而如今的分布式以及消息处理,必须要满足【集群,消息确认,内存化,高可用以及镜像】,这些就是最新的消息队列,如 ActiveMQ,ZereMQ,RabbitMQ等。
二:RabbitMQ的本质
1.RabbitMQ是用Erlang语言写的
2.遵循[AMQP]协议,一种高级队列协议
也就是,RabbitMQ是遵循AMQP协议并用erlang代码实现的消息系统
三:整体架构
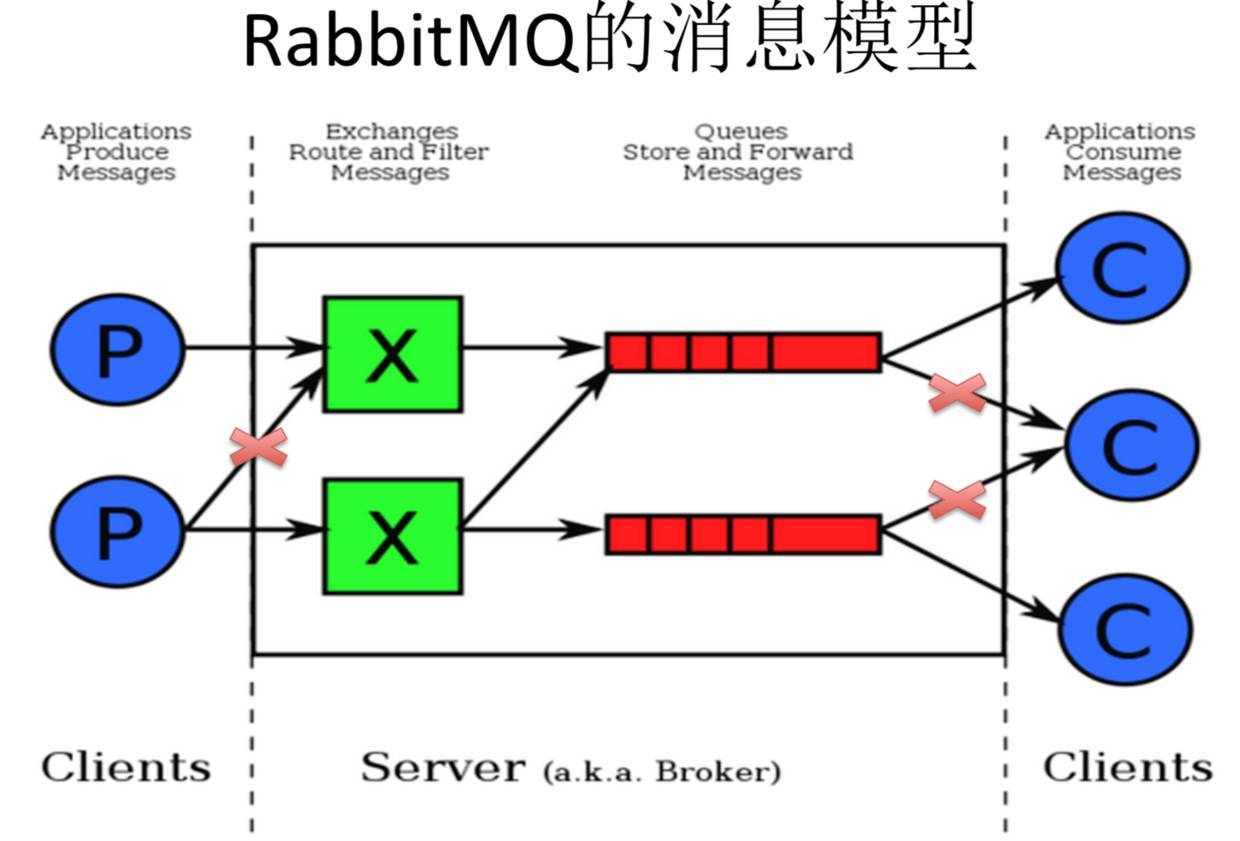
几个基本概念还是需要了解的:
RabbitMQ Server
也叫Broker Server,它不是运送食物的卡车,而是一种传输服务。原话是RabbitMQ isn't a food truck, it's a delivery service. 它的角色就是维护一条从Producer到Consumer的路线,保证数据能够按照指定的 方式进行传输。虽然这个保证也不是100%的保证,但是对于普通的应用来说这已经足够了。当然对于商业系统来说,可以再做一层数据一致性的guard,就可以彻底保证系统的一致性了。
Client P
也叫Producer,数据的发送方。Create messages and publish (send) them to a Broker Server (RabbitMQ)。一个Message有两个部分:payload(有效载荷)和label(标签)。payload顾名思义就是传输的 数据。label是exchange的名字或者说是一个tag,它描述了payload,而且RabbitMQ也是通过这个label来决定把这个Message发给哪个Consumer。AMQP仅仅描述了label,而RabbitMQ决定了如何使 用这个label的规则。
Client C
也叫Consumer,数据的接收方。Consumers attach to a Broker Server (RabbitMQ) and subscribe to a queue。把queue比作是一个有名字的邮箱。当有Message到达某个邮箱后,RabbitMQ把它发送给它的 某个订阅者即Consumer。当然可能会把同一个Message发送给很多的Consumer。在这个Message中,只有payload,label已经被删掉了。对于Consumer来说,它是不知道谁发送的这个信息的,就是 协议本身不支持。当然了,如果Producer发送的payload包含了Producer的信息就另当别论了。
对于一个数据从Producer到Consumer的正确传递,还有三个概念需要明确:exchanges, queues and bindings。
-
Exchanges are where producers publish their messages.
-
Queues are where the messages end up and are received by consumers.
-
Bindings are how the messages get routed from the exchange to particular queues.
还有几个概念是上述图中没有标明的,那就是Connection(连接)和Channel(通道,频道)。
Connection
就是一个TCP的连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可 以看到,程序的起始处就是建立这个TCP连接。
Channel
虚拟连接。它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是 程序起始建立TCP连接,第二步就是建立这个Channel。
那么,为什么使用Channel,而不是直接使用TCP连接?
对于OS来说,建立和关闭TCP连接是有代价的,频繁的建立关闭TCP连接对于系统的性能有很 大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建 立Channel是没有上述代价的。对于Producer或者Consumer来说,可 以并发的使用多个 Channel进行Publish或者Receive。有实验表明,1s的数据可以Publish10K的数据包。当然对于不同 的硬件环境,不同的数据包大小这个数据肯定不一样,但是我只想说明,对于普通的Consumer或者 Producer来说,这已经足够了。如果不够用, 你考虑的应该是如何细化SPLIT你的设计。
四:四种交换机:
RabbitMQ常用的Exchange Type有fanout、direct、topic、headers这四种(AMQP规范里还提到两种Exchange Type,分别为system与自定义,这里不予以描述),下面分别进行介绍。
1.fanout
fanout类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中。

上图中,生产者(P)发送到Exchange(X)的所有消息都会路由到图中的两个Queue,并最终被两个消费者(C1与C2)消费。
2.direct
direct类型的Exchange路由规则也很简单,它会把消息路由到那些Binding key与Routing key完全匹配的Queue中。

以上图的配置为例,我们以routingKey="error"发送消息到Exchange,则消息会路由到Queue1(amqp.gen-S9b…,这是由RabbitMQ自动生成的Queue名称)和Queue2(amqp.gen-Agl…);如果我们以 Routing Key="info"或routingKey="warning"来发送消息,则消息只会路由到Queue2。如果我们以其他Routing Key发送消息,则消息不会路由到这两个Queue中。
3.topic
前面讲到direct类型的Exchange路由规则是完全匹配Binding Key与Routing Key,但这种严格的匹配方式在很多情况下不能满足实际业务需求。topic类型的Exchange在匹配规则上进行了扩展,它与direct类 型的Exchage相似,也是将消息路由到Binding Key与Routing Key相匹配的Queue中,但这里的匹配规则有些不同,它约定:
Routing Key为一个句点号“.”分隔的字符串(我们将被句点号". "分隔开的每一段独立的字符串称为一个单词),如"stock.usd.nyse"、"nyse.vmw"、"quick.orange.rabbit"。Binding Key与Routing Key一样也 是 句点号“. ”分隔的字符串。
Binding Key中可以存在两种特殊字符"*"与"#",用于做模糊匹配,其中"*"用于匹配一个单词,"#"用于匹配多个单词(可以是零个)。

以上图中的配置为例,routingKey=”quick.orange.rabbit”的消息会同时路由到Q1与Q2,routingKey=”lazy.orange.fox”的消息会路由到Q1,routingKey=”lazy.brown.fox”的消息会路由到Q2, routingKey=”lazy.pink.rabbit”的消息会路由到Q2(只会投递给Q2一次,虽然这个routingKey与Q2的两个bindingKey都匹配);routingKey=”quick.brown.fox”、routingKey=”orange”、 routingKey=”quick.orange.male.rabbit”的消息将会被丢弃,因为它们没有匹配任何bindingKey。
4.headers
headers类型的Exchange不依赖于Routing Key与Binding Key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
在绑定Queue与Exchange时指定一组键值对;当消息发送到Exchange时,RabbitMQ会取到该消息的headers(也是一个键值对的形式),对比其中的键值对是否完全匹配Queue与Exchange绑定时指定的 键值对。如果完全匹配则消息会路由到该Queue,否则不会路由到该Queue。
该类型的Exchange没有用到过(不过也应该很有用武之地),所以不做介绍。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









