






实验一、词法分析实验
专业:商业软件工程 姓名:陈颖楠 学号:201506110104
一、实验目的
编制一个词法分析程序
二、实验内容和要求
输入:源程序字符串,输出:二元组(种别,单词本身),对字符串表示的源程序,从左到右进行扫描和分解,根据词法规则,识别出一个一个具有独立意义的单词符号 ,以供语法分析之用,发现词法错误,则返回出错信息。
三、 实验方法、步骤及结果测试
1. 源程序名:压缩包文件(rar或zip)中源程序名词法分析.c
可执行程序名:词法分析.exe
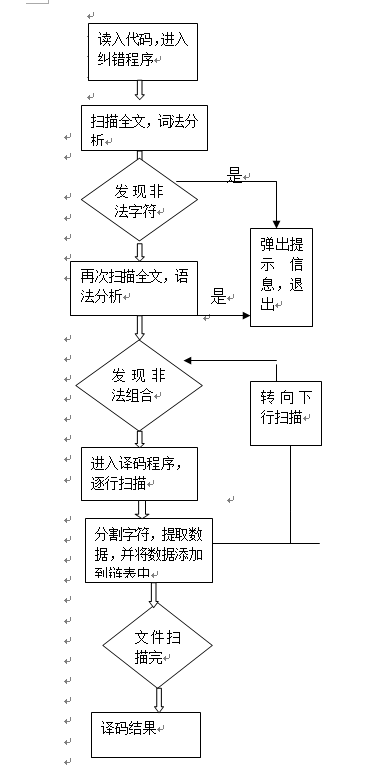
2. 原理分析及流程图
主要总体设计问题。
(包括存储结构,主要算法,关键函数的实现等)
3. 主要程序段及其解释:
实现主要功能的程序段,重要的是程序的注释解释。
char prog[80]={'\0'}, token[8]; /*存放构成单词符号的字符串*/ char ch; int syn,; /*存放单词字符的种别码*/ int n,sum,m,p; /*存放整数型单词* /*p是缓冲区prog的指针,m是token的指针*/ char *rwtab[6]={"begin","if","then","while","do","end"}; void scaner(){ m=0; sum=0; for(n=0;n<8;n++) token[n]='\0'; ch=prog[p++]; while(ch==' ') ch=prog[p++]; if(isalpha(ch)) /*ch为字母字符*/{ while(isalpha(ch)||isdigit(ch)) /*ch 为字母字符或者数字字符*/{ token[m++]=ch; ch=prog[p++];} token[m++]='\0'; ch=prog[p--]; syn=10; for(n=0;n<6;n++) if(strcmp(token,rwtab[n])==0) /*字符串的比较*/{ syn=n+1; break;}} else if(isdigit(ch)) /*ch是数字字符*/{ while(isdigit(ch)) /*ch是数字字符*/{ sum=sum*10+ch-'0'; ch=prog[p++];} ch=prog[p--]; syn=11;} else switch(ch){ case'<':m=0;token[m++]=ch;ch=prog[p++]; if(ch=='>'){ syn=21; token[m++]=ch;} else if(ch=='='){ syn=22; token[m++]=ch;} else{ syn=20; ch=prog[p--];} break; case'>':m=0;token[m++]=ch;ch=prog[p++]; if(ch=='='){ syn=24; token[m++]=ch;} else{ syn=23; ch=prog[p--];} break; case':':m=0;token[m++]=ch;ch=prog[p++]; if(ch=='='){ syn=18; token[m++]=ch;} else{ syn=17; ch=prog[p--];} break; case'+':syn=13;token[0]=ch;break; case'-':syn=14;token[0]=ch;break; case'*':syn=15;token[0]=ch;break; case'/':syn=16;token[0]=ch;break; case'=':syn=25;token[0]=ch;break; case';':syn=26;token[0]=ch;break; case'(':syn=27;token[0]=ch;break; case')':syn=28;token[0]=ch;break; case'#':syn=0;token[0]=ch;break; default:syn=-1;}} main() { p=0; printf("\n请输入需要分析的字符串,以#表示结束:"); do { ch=getchar(); prog[p++]=ch; }while(ch!='#'); p=0; do { scaner(); switch(syn) { case 11: printf("(%d,%d)\n",syn,sum);break; case -1: printf("\n 出错;\n");break; default: printf("(%d,%s)\n",syn,token); } }while(syn!=0); getch(); }
4. 运行结果及分析
一般必须配运行结果截图,结果是否符合预期及其分析。
五、实验总结
心得体会:这次实验花了很久的时间,有很多地方都要问别人和上网找,做出来之后觉得很有成就感。
实验过程的难点问题:输入字符串后要逐个提取出来然后用if语句判断字符的种别码很复杂,经常会写错。

















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









