 布隆过滤器解析
布隆过滤器解析







 本文介绍了布隆过滤器这一高效的数据结构,它通过多个哈希函数处理海量数据,以极小的空间判断元素是否存在集合中。文章探讨了布隆过滤器的工作原理、应用场景及优缺点。
本文介绍了布隆过滤器这一高效的数据结构,它通过多个哈希函数处理海量数据,以极小的空间判断元素是否存在集合中。文章探讨了布隆过滤器的工作原理、应用场景及优缺点。
第一次听说Bloom Filter 是我在跟一个师兄交流一道算法题的时候听到的一个陌生名词,当时就google了一下,很快就从吴军老师的google黑板报里得到了答案。原来它是这么一个高级的数据结构(连google都在用)。对于集合的处理,一般我们能想到的数据结构无非就是树,hash表这两个基础的数据结构。每一个数据结构都有自己的用武之地,在处理一个相对来说不算很大的集合的时候这两个数据结构足以能够应付了,并且是相当的令人满意,然而你有没有想到过数据量很大的情况,像《数学之美》中提到的例子,如果需要你很快的判断一个电子邮件的发送者是否在黑名单中(这个黑名单是很大的,上亿级别的)。这个时候如果用hash的方法去存储映射所有的黑名单成员,似乎将会变得很费力,因为数据量实在太大了。如何用最小的空间去存储最大的信息呢?用bit,对。我们可以用bit实现用最少的内存空间去表达需要的信息,在这个例子中我们需要的信息也就是存在不存在?1bit足矣!有人会问了如何去定义某一位是否为1呢?这里就不再像bitmap算法那么简单了(它似乎只能用来处理数字问题,而这里是字符串问题)。如果你对hash掌握的不错,你一定想到答案了,对,用hash将这个邮件地址映射到某一位,我们以后只需要判断某一位的情况就行了。也许你以为这样就可以了,不,绝对不是这样的,在1970年布隆本人提出的布隆过滤器可不是这个样子的,它为了提高判断的精确度(判断元素是不是在这个集合之中),他用了8个hash,至于为什么用8个,我也不太清楚.举个例子:我想把地址abc@yahoo.com 插入到到布隆过滤器中的话就会进行这样的一个过程
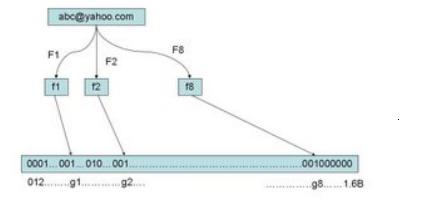
当然了每一项技术都有它自己的用武之地,存在即是合理。
总结一下它的优点所在:
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势,它的插入和查询时间都为常量级。我认为它的最大的优点就是占用的空间较小。适合处理海量数据的处理。
它的优点之后也隐藏着缺点所在:
误差率是其总明显的不足(当然了其误差率是微乎其微的,通常情况下可以忽略)。随着数据量的增大,它的误差率会随之增加,当然了,如果你需要处理的数据量不是很大,使用hash就足矣。对数据集操作比较敏感的同学也会发现了,其实布隆的删除操作时比较麻烦的。因为1个bit的值肩负着很多个元素的存在与否的表达,如果仅考虑一个元素就把它清零了,那么对其它元素的判断都会受到影响。当然了采用计数器的方法来避免这个问题,但这个过程没有这么简单,在这里就不追究了。
说到底,其实布隆过滤器就是bit-map的一个hash扩展而已,bit-map的应用是判断某一个数字元素是否在某一个集合当中。当遇到非数字的海量问题的时候,我们应该能够想的到布隆过滤器这个强大的数据结构。其实这两个(bit-map和bloomFilter)数据结构的思路是一样的。

















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









