






原先的问题:
第一次社团任务是写个图书管理系统,理所当然用到了数据库。
废话不多说直接上表:
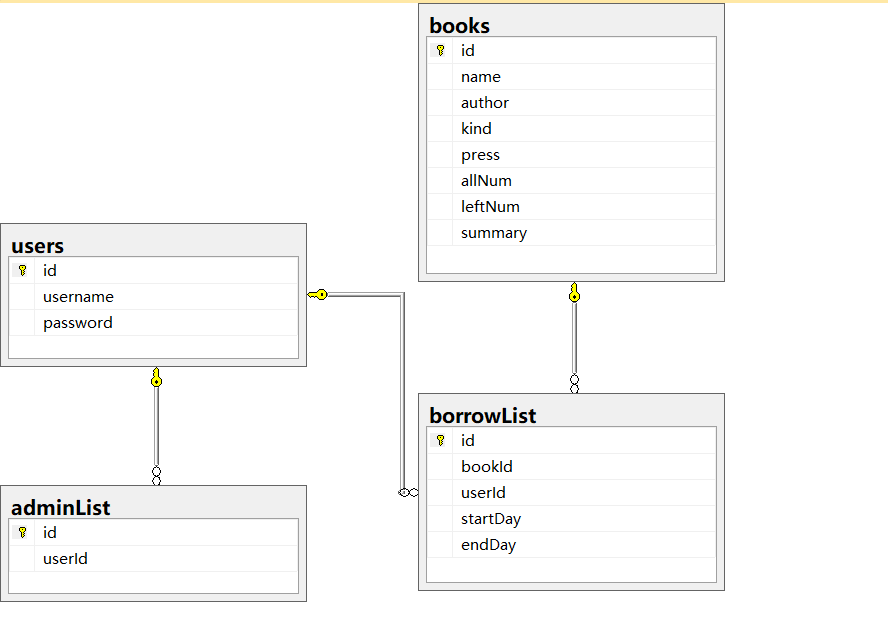
第一次做这种东西,都是边摸索边设计,于是理所当然被大牛指出了不足之处,比如adminlist其实有点多余。
提几个让人抓狂的问题:
1、当你设计好了books表,一本书可以有书名、种类、作者等属性,并且你已经添加了上百本书进去的时候,客户突然要求你加个“适合阅读人群”的属性。
2、一本书一个kind,貌似没什么问题。但是,用户可以借阅多本书,书也可以被多个用户借阅,一开始考虑时“书”与“用户”多对多的关系很容易被想到。但谁也不能保证自己没漏掉任何情况。于是到后期,突然发现书和kind也有个多对多的要求,拓展下,客户希望你把书和作者也改成多对多的关系……
(╯‵□′)╯︵┻━┻
新型建表法:
把所有的数据按照“值”,“属性”方式保存成一个个点。再表达点与点间的连线关系。
初步想法是建3张表:
表1:数据点
列名 :id(主键),数据 ,类型id
值类型:int ,maxchar (这里是因为当时还没想好),int
表2:类型
列名 :id(主键),类型
值类型:int ,maxchar
表3:连线
列名 :id(主键),点1的id ,点2的id
值类型:int ,int ,int
这种东西建好以后是什么概念呢?
比如要做用户管理,最简单的,用户只有用户名及密码。
那首先在表2里添加 “用户名”,“密码”两个类型。
然后添加用户时,相当于建立两个节点,一个节点的类型是“用户名”,一个节点的类型是“密码”,然后数据那一栏里就是...就是你们想的那样。
最后再在表3连线那里给这两个点条线,大功告成。
好了,如果客户突然抽风,要求你给用户再加个属性表示这人喜欢吃什么。
在类型表里添加“喜欢吃啥”。
建点,连线,ok。
查询时,先查出某个用户的所有连线,再根据连到的点的类型筛选你需要的点。比如一个查一个用户的所有借阅书籍可以这么查:先查与 数据为XX 类型为“用户名” 的节点连线的所有节点,然后筛选其中所有类型为“图书”的点,然后取出数据,就完成了。说起来复杂,其实写到sql语句里就一行。
改进:
好了,有个很明显的缺陷,不知道你们有没有看出来。
数表1的数据那一栏,值是maxchar,各种编程语言里可以用object啥的表示,用的时候再强制转类型,但是数据库只能苦逼地用...用什么表示都不对。于是可以这么改:
表2表3不变
表1:
列名:id ,数据所在类型的表名 ,表内id,类型id
值 :int,表名一般是char[20]以内吧,int ,int
表4~n:
列名:id ,数据 ,对应表1的id
值 :int ,杂七杂八的类型 ,int
改了下数据的索引方式,这样就方便起来了。
这种表(图?)的优缺点:
优点:
对存储数据储存方式的变更极其灵活,多对多 多对一 一对多不在话下,而且随时可以添加新的类型。
缺点:
面对大量数据(百万级千万级)就呵呵了,因为要查询用户O(n)*查询连线O(m)*查到另一个点O(n)*筛选O(1?)。(不过考虑到数据库的索引方式,如果写的好的话没准是O(logn)?)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









