



 本文介绍了使用SilkTest进行自动化测试时与Excel交互的两种方法:DataDriven测试和通过SQL及脚本的方式。对比了两种方法的特点及适用场景。
本文介绍了使用SilkTest进行自动化测试时与Excel交互的两种方法:DataDriven测试和通过SQL及脚本的方式。对比了两种方法的特点及适用场景。
这两种方式都是对 SilkTest 运用的最基础的东西,我写得也比较简单。国内这方面的资料实在太少,对初学者可能有帮助。
方式一 : Data Driven
1. 新建一个脚本文件
-File -> New -> 4TestScrpit ->Save as -> "smipletest.t"
2. 新建一个普通的testcase CheckSameString, 比较两个字符串是否相同

3. 新建一个Excel表 ,另存为"TestData.xls"
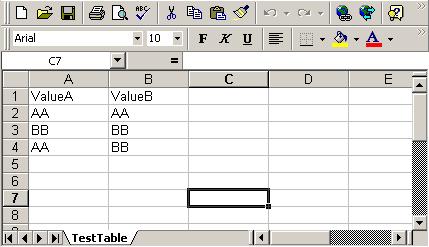
4. 将普通的testcase转成Data Driven的testcase
- Workflows-> Data Driven ->SilkTest的Toolbar改变
- 回到刚刚新建的"smipletest.t",单击“Data Driven Testcase“,选择 "CheckSimpleString"-> OK button
- Create a new file "smipletest.g.t"
- Select workbook "TestData.xls"
- Add a new Data Driven testcase "DD_CheckSimpleString"
- Find/Replace Value ("A"-> Column ValueA; "B"-> Column ValueB)
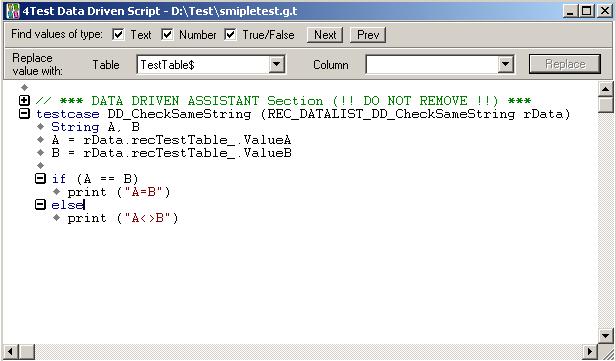
5.运行smipletest.g.t 脚本文件上的testcase DD_CheckSameString, 第1,2个会print "A=B", 第三个print "A<>B"。
方式二 : SQL和脚本
1. 在 smipletest.t 脚本文件中新增一个的 CheckSmipleString_Advanced 的 testcase。
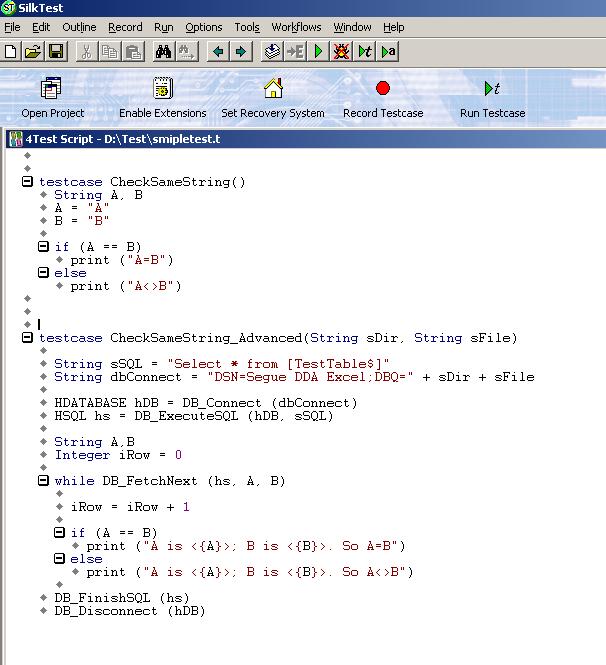
2. CheckSmipleString_Advanced定义了两个参数,所以不能直接运行testcase, 这里可以跟pln关联
3. 新增一个 Testpln 文件: New-> Testpln -> Save as "smiplepln.pln" -> 输入相应Testplan, 如图
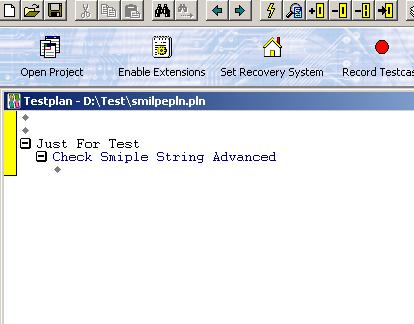
4. 鼠标放在 "Check Smiple String Advanced" 行,选择Testplan-> Detail , 出现 "Testplan Detail" 对话框-> 选择Scripts "smipletest.t", Testcases "CheckSameString_Advanced" -> OK -> OK
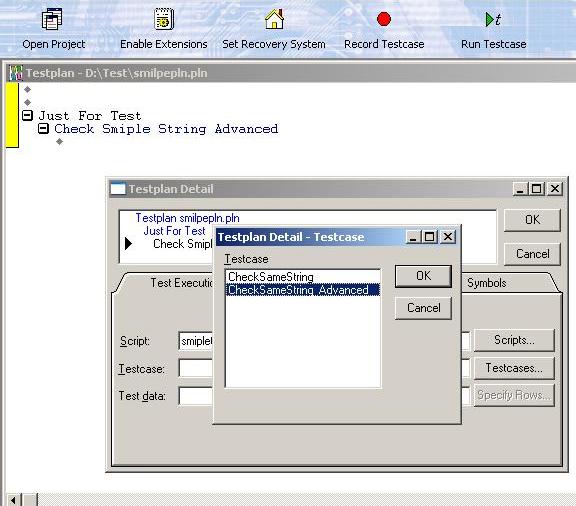
5. 最后加上两个参数值
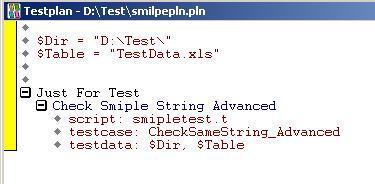
6. 这样就可以执行这个Testplan了
7. 执行结果
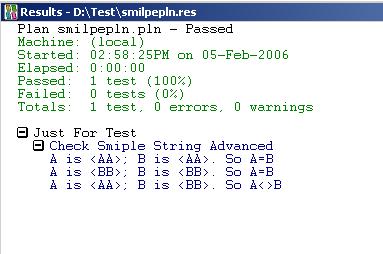
比较:
其实这两种方式非常相似。但是Data Driven的方式不能控制循环语句,不能自由的获取 Excel 中某行某列的值。但是方式二就比较自由,循环是可控制的。并且从速度上而言,个人感觉方式二要快很多。(这个简单的例子可能看不出来,但是如果是 GUI 操作的测试就比较明显了)

















 108
108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









