



点击“Python数据分析与人工智能科技”
右上角选择设置“星标公众号”
每日一语:“天行健,君子以自强不息。地势坤,君子以厚德载物。”——《易经》

继续上一次正则表达式学习~~
点击下面蓝色字体可回看往期知识点:
回顾:
在正则表达式中,需要注意的是,大家在写编程的时候,可能会注意美观,可能会多加一些空格,但是在正则表达式里面,你千万不能加空格。例如:
这是因为空格会被解析为一个正则表达式。
几个特殊的等价关系:
①、星号(*):匹配前面的子表达式零次或多次,等价于 {0,};
②、加号(+):匹配前面的子表达式一次或多次,等价于 {1,};
③、问号(?):匹配前面的子表达式零次或一次,等价于 {0,1}。
14、贪婪 和 非贪婪
值得注意的是,正则表达式默认是启用 贪婪 的模式来进行匹配的,那什么是 贪婪 呢?
简单的是说贪婪就是贪心,也就是说,只要在符合的条件下,它会尽可能多的去匹配,例如回顾前面的
就会直接匹配到3个 youyouyou。
下面给出另一个例子:
源码剖析:
特别地,在正则表达式中,<.> 表示以 < 开头,以 > 结尾,重复 . 号 1次或多次。最后匹配了字符串全部。
对于贪婪来说,它会在条件符合的情况下尽可能多的去匹配,既然是这样,我们就必须启用 非贪婪模式才可以,那么非贪婪模式怎么样启用呢?
值得关注的是,在表示重复的元字符后面再加上一个“?”问号,这时候,问号就不代表0次或1次了,而是表示启用非贪婪模式(如上述代码的最后两行)
15、反斜杠(\) + 字母 等同于 特殊字符的含义
(1)、\序号,其中序号就是数字:
①、引用序号对应的子组所匹配的字符串,此时序号的范围是 1~99,子组的序号是从 1 开始计算。
②、如果序号是以 0 开头,或者 3 位数字的长度。那么不会被用于引用对应的子组,而是用于匹配八进制数字所表示的ASCII 码值对应的字符。
上述在前期已经提到,这里将不再重复。
(2)、\A :这个符号在默认情况下和 托字符(^)是一样的,都是匹配输入字符串的开始位置。
源码剖析:
也就是说,要是前面是 \A 或者 ^ 符号,那么这个字符就必须出现在字符串的开头,才能算是匹配。
(3)、\Z:这个符号在默认情况下和 美元符号($)是一样的,都表示匹配输入字符串的结束位置。
上述都是在默认情况下进行的,但不是说完全一样的。因为在正则表达式中还有一个 编译标志的设置。
例如:如果说你设置了一个 re.MULTILINE 标志,那么托字符(^)也匹配换行符之后的位置,同时,美元符号($)也匹配换行符之前的位置。
但是呢,无论你设不设置这个标志,这个 \A 和 \Z 都只能匹配字符串的开头 和 结束 位置。
像这种匹配位置的字符,我们给它们一个名字,叫做 临框断言,言外之意就是它们不会匹配任何字符,它们只用于定位一个位置。
(4)、\b 它是匹配一个单词的边界,单词被定义为 Unidcode 的字母数字或下横线字符。举个例子:
源码剖析:
上面只找到了两个 YOU,你知道它哪一个YOU没有找到吗?(事实上是 YOU_com 中的YOU),因为下划线也被认为是单词字符,不是边界。点号(.)感叹号(!)、括号都被认为是单词边界。
(5)、\B,其实就是与 \b 相反,匹配非单词边界(如上述代码中的最后一行)。
(6)、\d:
① 对于 Unicode(str 类型)模式:匹配任何一个数字,包括 [0-9] 和其他数字字符;如果开启了 re.ASCII 标志,就只匹配 [0-9]。
② 对于 8 位(bytes 类型)模式:匹配 [0-9] 中任何一个数字。
(7)、\D:与 \d 相反,匹配任何非 Unicode 的数字;如果开启了 re.ASCII 标志,则相当于匹配 [^0-9]。
(8)、\s :
①对于 Unicode(str 类型)模式:匹配 Unicode 中的空白字符(包括 [ \t\n\r\f\v] 以及其他空白字符);如果开启了 re.ASCII 标志,就只匹配 [ \t\n\r\f\v]
② 对于 8 位(bytes 类型)模式:匹配 ASCII 中定义的空白字符,即 [ \t\n\r\f\v]
(9)、\w:① 对于 Unicode(str 类型)模式:匹配任何 Unicode 的单词字符,基本上所有语言的字符都可以匹配,当然也包括数字和下横线;如果开启了 re.ASCII 标志,就只匹配 [a-zA-Z0-9_]。
例如:
除了 空格 括号 点号 感叹号,其它的汉字、字母、下横线、数字 都是单词字符。
(10)、\W :其实就是与 \w 相反, 匹配任何非 Unicode 的单词字符,;如果开启了 re.ASCII 标志,则相当于 [^a-zA-Z0-9_]
此外,正则表达式还支持大部分 Python 字符串的转义符号:\a,\b,\f,\n,\r,\t,\u,\U,\v,\x,\
16、编译正则表达式
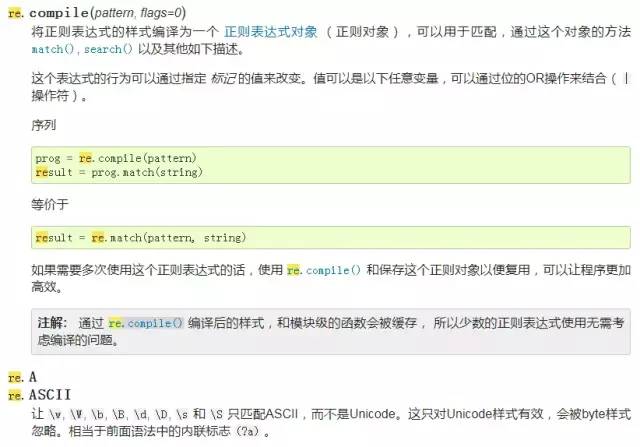
在正则表达式的编译中,若你要重复地使用某个正则表达式,那么你可以先把该正则表达式编译成模式对象。
可以打开Python3.7.4解释器的文档(在Help中的doc或F1), 然后搜索e.compile() 就在正则表达式中(Compiling Regular Expressions),并且给出了例子。
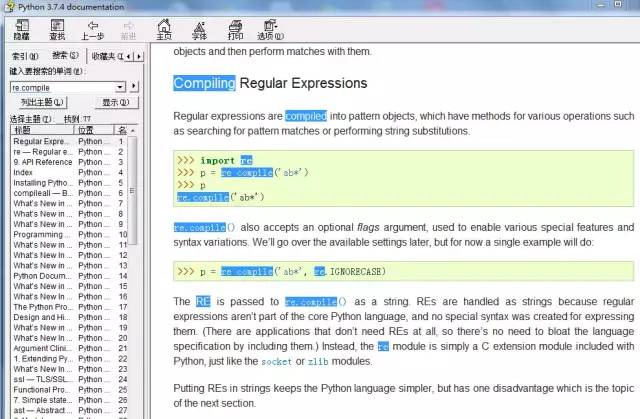
可以直接打开Python官网的中文文档:
https://docs.python.org/zh-cn/3/library/re.html?highlight=re%20complie
下面我们再试一试使用 re.compile() 方法来编译表达式
把正则表达式 [A-Z] 进行编译,赋值给 一个变量 x,这个变量 x就是一个模式对象。我们可以直接使用 x 进行 search() 方法 和 findall() 方法 的使用:
每日三道题, 笔试面试不吃亏:
题目13:将一个正整数分解质因数。例如:输入90,打印出90=2*3*3*5。
分解质因数:
每个合数都可以写成几个质数相乘的形式,其中每个质数都是这个合数的因数,把一个合数用质因数相乘的形式表示出来,叫做分解质因数。如30=2×3×5 。分解质因数只针对合数。
程序分析:
对n进行分解质因数,应先找到一个最小的质数k,然后按下述步骤完成:
(1)如果这个质数恰等于n,则说明分解质因数的过程已经结束,打印出即可。
(2)如果n<>k,但n能被k整除,则应打印出k的值,并用n除以k的商,作为新的正整数n,重复执行第一步(1)。
(3)如果n不能被k整除,则用k+1作为k的值,重复执行第一步。
或
或
执行结果:

题目14:利用条件运算符的嵌套来完成此题:
学习成绩>=90分的同学用A表示,
60-89分之间的用B表示,
60分以下的用C表示。
程序分析:
程序分析:(a>b)?a:b这是条件运算符的基本例子。
或
或
执行结果:

题目15:输出指定格式的日期。
程序分析:使用 datetime 模块。
或
扫码关注我,一起交流学习
可点击左下方更多“阅读原文”

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









