



 本文介绍如何通过自定义机器人将Zabbix告警信息整合到钉钉群聊中,包括创建钉钉机器人、配置Zabbix告警脚本及设置监控界面等步骤。
本文介绍如何通过自定义机器人将Zabbix告警信息整合到钉钉群聊中,包括创建钉钉机器人、配置Zabbix告警脚本及设置监控界面等步骤。
群机器人是钉钉群的高级扩展功能,群机器人可以将第三方服务的信息聚合到群聊中,实现自动化的信息同步。例如:通过聚合GitHub,GitLab等源码管理服务,实现源码更新同步;通过聚合Trello,JIRA等项目协调服务,实现项目信息同步。不仅如此,群机器人支持Webhook协议的自定义接入,支持更多可能性. 比如我们可将Zabbix运维报警提醒通过自定义机器人聚合到钉钉群中,以实现钉钉告警。下面记录下Zabbix通过钉钉告警的设置过程:
一. 钉钉机器人创建
登录钉钉客户端,创建一个群,把需要收到报警信息的人员都拉到这个群内.然后点击群右上角的"群机器人"->"添加机器人"->"自定义",记录该机器人的webhook值!
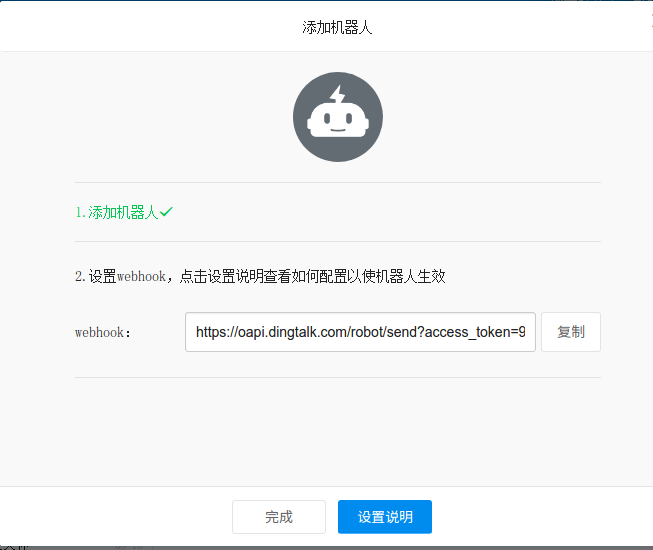
二. Zabbix设置
[root@zabbix01 ~]# cat /usr/local/zabbix/etc/zabbix_server.conf|grep AlertScriptsPath
AlertScriptsPath=/usr/local/zabbix/monitor_scripts
登录到/usr/local/zabbix/monitor_scripts下编写dingding.py脚本(脚本中包含钉钉机器人的webhook值):
[root@zabbix01 ~]# cd /usr/local/zabbix/monitor_scripts/
[root@zabbix01 monitor_scripts]# cat dingding.py
#!/usr/bin/env python
#coding:utf-8
#zabbix钉钉报警
import requests,json,sys,os,datetime
webhook="https://oapi.dingtalk.com/robot/send?**********************************************"
user=sys.argv[1]
text=sys.argv[3]
data={
"msgtype": "text",
"text": {
"content": text
},
"at": {
"atMobiles": [
user
],
"isAtAll": False
}
}
headers = {'Content-Type': 'application/json'}
x=requests.post(url=webhook,data=json.dumps(data),headers=headers)
if os.path.exists("/usr/local/zabbix/logs/dingding.log"):
f=open("/usr/local/zabbix/logs/dingding.log","a+")
else:
f=open("/usr/local/zabbix/logs/dingding.log","w+")
f.write("\n"+"--"*30)
if x.json()["errcode"] == 0:
f.write("\n"+str(datetime.datetime.now())+" "+str(user)+" "+"发送成功"+"\n"+str(text))
f.close()
else:
f.write("\n"+str(datetime.datetime.now()) + " " + str(user) + " " + "发送失败" + "\n" + str(text))
f.close()
创建上面脚本中的日志路径:
[root@zabbix01 monitor_scripts]# touch /usr/local/zabbix/logs/dingding.log
[root@zabbix01 monitor_scripts]# chown zabbix.zabbix dingding.py
[root@zabbix01 monitor_scripts]# chmod 755 dingding.py
[root@zabbix01 monitor_scripts]# chown zabbix.zabbix /usr/local/zabbix/logs/dingding.log
手动测试脚本发信是否正常:
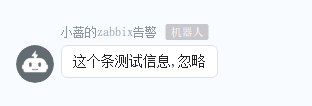
这个条文档记录的测试信息,忽略
[root@zabbix01 monitor_scripts]# ./dingding.py test 13611027803 "这个条测试信息,忽略"
===========================================================
注意:该脚本要求至少python2.6.6版本,且具有requests模块.
否则会报错:
Traceback (most recent call last):
File "./dingding.py", line 4, in <module>
import requests,json,sys,os,datetime
ImportError: No module named requests
解决办法:
[root@zabbix01 monitor_scripts]# yum install python-pip
[root@zabbix01 monitor_scripts]# pip -v
[root@zabbix01 monitor_scripts]# pip install requests
===========================================================
钉钉上收到的测试信息如下:
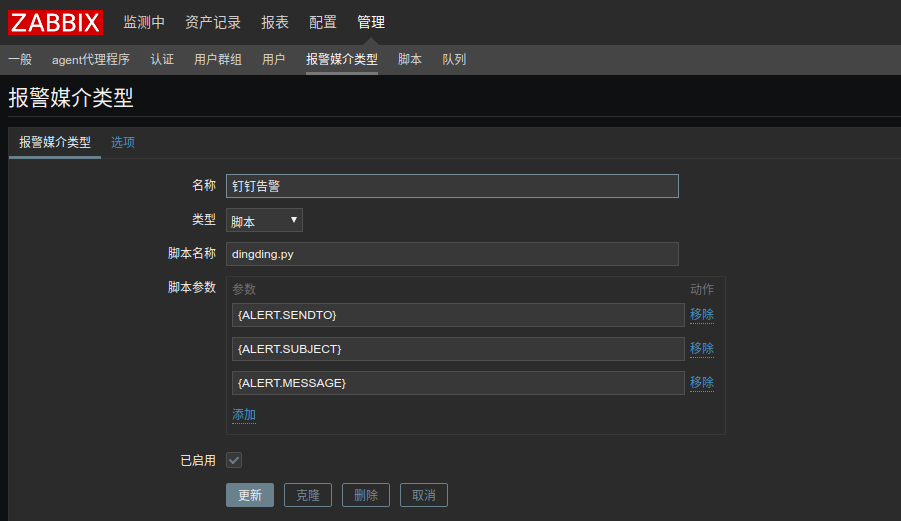
三. Zabbix监控界面设置
1) 创建报警媒介. 三个参数分别是:ALERT.SENDTO ALERT.SUBJECT ALERT.MESSAGE
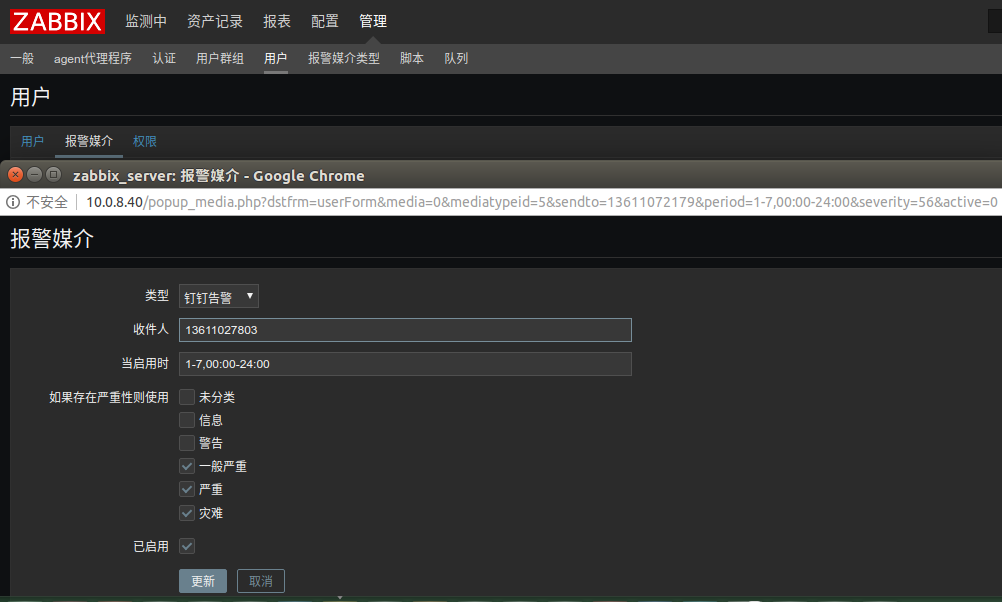
2) 用户添加报警媒介
收件人是钉钉上的手机号码.这里使用Admin管理员用户,在Admin用户的"报警媒介"里添加收件人信息
特别注意:这里只需要添加钉钉群里的任何一个成员的手机号码即可,即添加一个收件人,这样在机器人群里成员都能看到告警信息.
如果添加多个收件人,则机器人群里就会发送多个告警信息,一个收件人发一条信息.
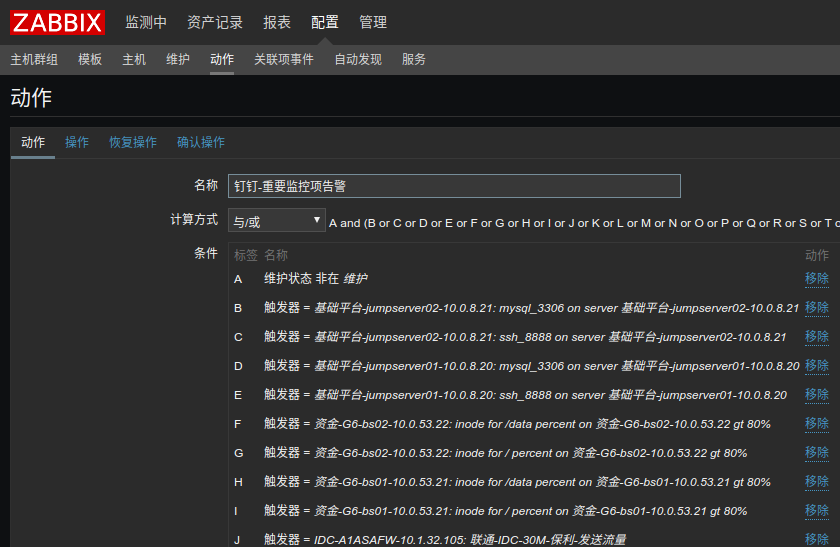
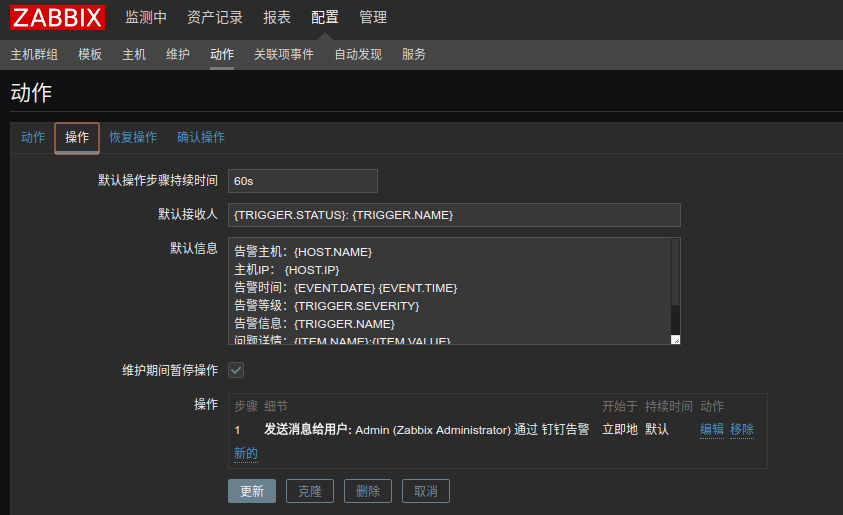
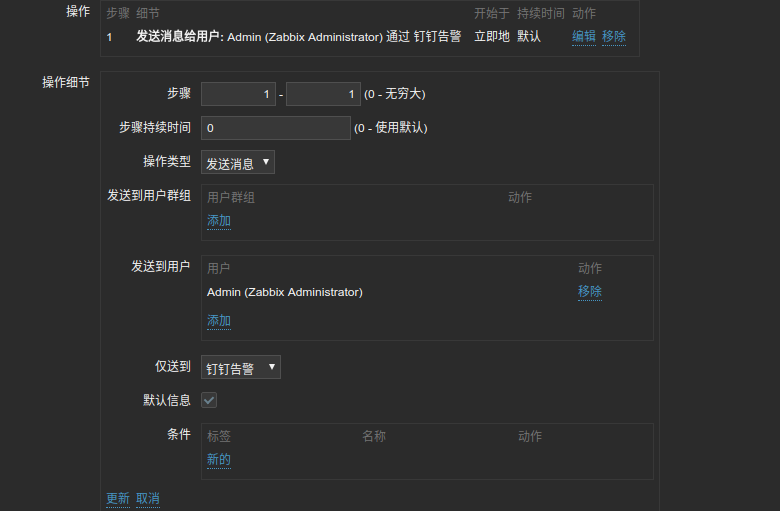
3) 添加动作
动作里的报警信息和恢复信息都发送给Admin用户.
操作
默认接收人:{TRIGGER.STATUS}: {TRIGGER.NAME}
默认信息:
告警主机:{HOST.NAME}
主机IP: {HOST.IP}
告警时间:{EVENT.DATE} {EVENT.TIME}
告警等级:{TRIGGER.SEVERITY}
告警信息:{TRIGGER.NAME}
问题详情:{ITEM.NAME}:{ITEM.VALUE}
当前状态: {TRIGGER.STATUS}:{ITEM.VALUE1}
事件ID: {EVENT.ID}
恢复操作(确认操作也是一样):
默认接收人:{TRIGGER.STATUS}: {TRIGGER.NAME}
默认信息:
告警主机:{HOST.NAME}
主机IP: {HOST.IP}
告警时间:{EVENT.DATE} {EVENT.TIME}
告警等级:{TRIGGER.SEVERITY}
告警信息:{TRIGGER.NAME}
问题详情:{ITEM.NAME}:{ITEM.VALUE}
当前状态: {TRIGGER.STATUS}:{ITEM.VALUE1}
事件ID: {EVENT.ID}
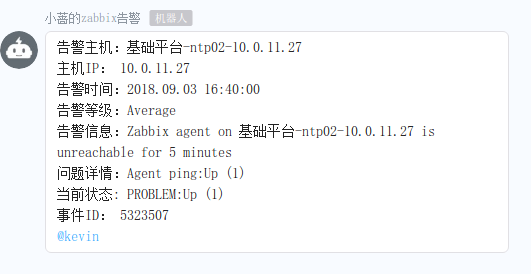
然后进行测试,比如关闭一台被监控机器的10050端口,过一会儿,查看下钉钉上的报警信息,如下:

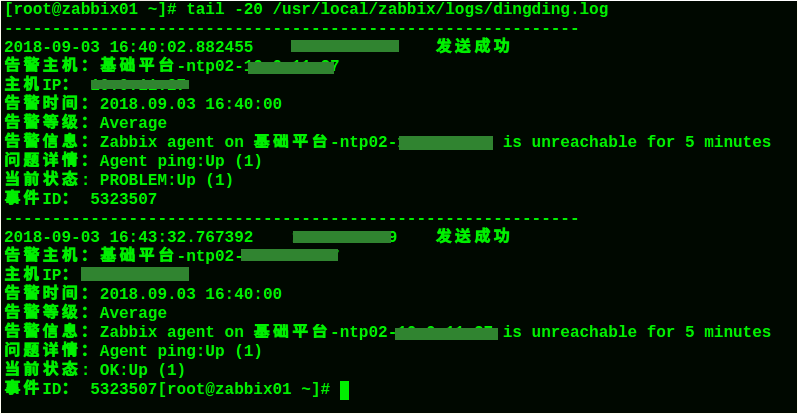
还可以查看dingding.log日志,看看告警信息发送情况:

















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









