



 团队讨论并确定使用基于遗传算法的信息抽取方法。下一步将重点整合和处理领域字典,包括中英文对照工作,并制定了每位成员的具体任务。
团队讨论并确定使用基于遗传算法的信息抽取方法。下一步将重点整合和处理领域字典,包括中英文对照工作,并制定了每位成员的具体任务。
TeamSHIT
今天团队讨论了抽取的算法,根据之前的论文阅读情况和讨论,我们选择了基于遗传的一个算法。遗传算法一个核心是构建一部领域的字典。这部字典已经基本获取了,所以下一阶段的核心任务是字典的整合和处理,譬如要根据中文获取英文,因为字典是中文形式给出的。
| 组员 | 今天任务 | 明天任务 |
| 胡仁君 |
任务292 继续小组论文学习交流会 任务367 确定信息抽取的主要算法 |
任务341 Pipeline信息抽取
|
| 彭笑东 |
任务289 学习信息抽取基本算法 任务367 确定信息抽取的主要算法
|
任务374 翻译语料库 制定翻译的方案 |
| 李斌 |
任务373 翻译语料库 整合语料库 |
任务373 翻译语料库 整合语料 |
| 隋宇豪 |
任务287 相关数据库的定义和实现 建表 |
任务375 创建语料字典的数据库 |
燃尽图和燃速图
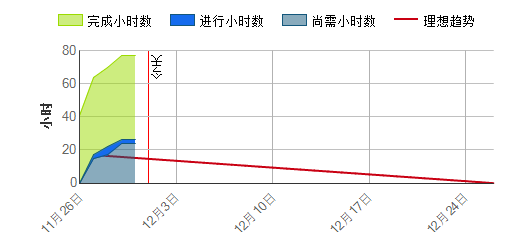
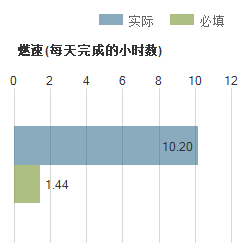

















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









