



2.1 程序与用户交互
在python3中
#input:无论用输入何种类型,都会存成字符串类型 name=input('please input your name: ') #name='18' print(id(name),type(name),name)
在python2中
#raw_input与python3的input是一样的 name=raw_input('please input your name: ') print(id(name),type(name),name) #python2中input,用户必须输入值,输入的值是什么类型,就存成什么类型 name=input('please input your name: ') print(id(name),type(name),name)
2.2 变量
2.2.1 如何定义变量?
python中的变量:
- 不需要提前声明,变量的赋值操作既是变量的声明也是变量的定义过程。
- 每个变量在内存中创建,都包括变量的标识、名称和数据这些信息。
- 每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
name='egon'
password='egon123' password='egon@123' level=1 level=2 print='123' print('asdfasdf')
2.2.2 变量名的命名规则?
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 关键字不能声明为变量名
- 标识符区分大小写。如:n和N不是一个标识符。
- 以下划线开头的标识符是有特殊意义的。(*****不建议命名开头和结尾带下划线的变量*****)
- 以单下划线开头的表示不能直接访问的类属性,如:_foo
- 以双下划线开头的表示类的私有成员,如:__foo
- 以双下划线开头和结尾的表示特殊方法专用标识符,如:__init()__代表类的构造函数。
定义的方式
#驼峰式 AgeOfOldboy=53 #下划线 age_of_oldboy=53 age_of_oldboy=54
2.2.3 变量的三要素(重点)
定义一个变量,会有三个特征:id,type,value
name='egon'
变量值:用来表示状态
用变量名取变量值
print(name)
变量值的类型:表示不同的状态应该用不同类型的值去表示(数字:年龄,字符串:名字)
print(type(name))
变量值的id号:
print(id(name))
较短字符串的id号一样:
name1='egon' name1,type(name1),id(name1) # ('egon', <class 'str'>, 35494968) name2='egon' name2,type(name2),id(name2) #('egon', <class 'str'>, 35494968)
稍长的字符串id号不一样:
info1='info egon:18' info2='info egon:18' info1,type(info1),id(info1) # ('info egon:18', <class 'str'>, 35513136) info2,type(info2),id(info2) # ('info egon:18', <class 'str'>, 35513200)
较短数字的id号一样:
x=1 y=1 id(x) #1626261168 id(y) #1626261168
稍长数字的id号不一样:
x=1234567890123 y=1234567890123 id(x) #30057584 id(y) #34827152
2.3 常量
全部大写只是表明是个常量,没有绝对的常量
>>> AGE_OF_OLDBOY=54
2.4 引用计数+垃圾回收机制(了解)
- 增加引用计数
- 对象被创建并将其引用赋值给变量,引用计数加1(例a=1)
- 同一个对象的引用又赋值给其它变量,引用计数加1(例b=a)
- 对象作为参数被函数调用,引用计数加1(例int(a)
- 对象成为容器对象中的一个元素,引用计数加1(例list_test=['alex','z',a])
- 减少引用计数
- a作为被函数调用的参数,在函数运行结束后,包括a在内的所有局部变量均会被销毁,引用计数减1
- 变量被赋值给另外一个对象,原对象引用计数减1(例b=2,1这一内存对象的引用只剩a)
- 使用del删除对象的引用,引用计数减1(例del a)
- a作为容器list_test中的一个元素,被清除,引用计数减少(例list_test.remove(a))
- 容器本身被销毁(例del list_test)
x='aaa' #'aaa'这个值的引用计数为1 y=x #'aaa'这个值的引用计数为2 x=1 x=2 # 1会被垃圾回收机制处理 z=3 del z # 自己处理变量 z,一般不用自己处理垃圾 Python 会自己处理
2.5 基本数据类型
http://www.cnblogs.com/snailgirl/p/8030106.html
2.6 格式化输出
%d只能接受int类型,而%s既可以接收数字又可以接收字符串
name=input('name>>: ') age=input('age>>: ') print('my name is [%s] my age is <%s>' %(name,age)) print('my name is %s' %'egon') print('my name is %s' %11111111111111) print('my age is %d' %10) print('my age is %d' %'xxxx') #%d只能接收数字,而%s既可以接收数字又可以接收字符串 name=input('name>>: ') age=input('age>>: ') sex=input('sex>>: ') job=input('job>>: ') msg=''' ------------ info of %s ----------- Name : %s Age : %s Sex : %s Job : %s ------------- end ----------------- ''' %(name,name,age,sex,job) print(msg)
2.7 基本运算符
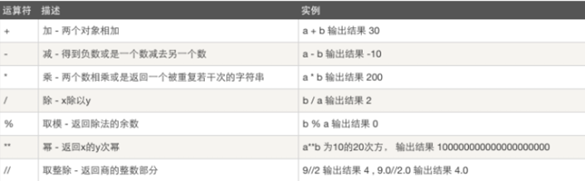
2.7.1 算术
print(10%3) print(2**3) print(10/3) print(10//3)
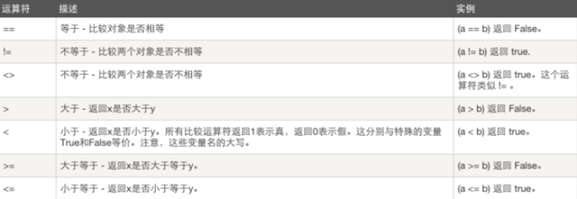
2.7.2 比较
print(10 > 3) print(10 < 3) print(10 == 3) print(10 != 3)
2.7.3 赋值
a=2
b=a
链式赋值
a=b=c=2
print(id(a),id(b),id(c))
交叉赋值
#python中的用法 m=1 n=2 m,n=n,m print(m,n)
# low用法 temp=m m=n n=temp print(m,n)
解压
#第一种: l=[1,2,3,4] a,b,c,d=l print(a) print(b) print(c) print(d) #第二种: a=l[0] _=l[1] _=l[2] d=l[3] a,_,_,d=l print(a,d) #第三种: a,*_,d=l print(a) print(d)
赋值运算符
level=1 level+=1 #level=level+1 level-=1 #level=level-1 print(level)
2.7.4 逻辑and or not
print(1 > 2 or 1 > 3 or 3 > 1 or 4 < 3) print(not 4 > 2

2.7.5 ==与is
判断值是否相等:==
判断id是否相等:is
x=1234567890123 y=1234567890123 id(x) #结果:30057584 id(y) #结果:34827152 x is y #False x == y #True
2.8 集合 set
多个值,值不可变类型,无序,可变类型
作用:关系运算,去重
定义集合:{}内用逗号分割每个元素都必须是不可变类型,元素不能重复,无序
s={1,'a',[1,2]} #TypeError: unhashable type: 'list'
s={1,2,3,1} #s=set({1,2,3,1})
print(s,type(s))
优先掌握的操作:
pythons=['egon','axx','ysb','wxx']
linuxs=['egon','oldboy','oldgirl','smallboy','smallgirl']
1、长度len
s={1,2,3,1} #s=set({1,2,3,1})
print(len(s))
2、成员运算in和not in
names={'egon','alex'}
print('egon' in names)
3、&交集:同时报名两门课程的学生
print(pythons & linuxs) print(pythons.intersection(linuxs))
4、|合集:老男孩所有的学生
print(pythons | linuxs) print(pythons.union(linuxs))
5、^对称差集:没有同时报名两门课程
print(pythons ^ linuxs) print(pythons.symmetric_difference(linuxs))
6.1 -差集:只报名python课程的学生
print(pythons - linuxs) print(pythons.difference(linuxs))
6.2 -差集:只报名linux课程的学生
print(linuxs-pythons)
7、父集:>,>=,子集:<,<=
s1={1,2,3}
s2={1,2,}
print(s1 >= s2)
print(s1.issuperset(s2)) #s1是s2的父集
print(s2.issubset(s1))
linuxs={'egon','oldboy','oldgirl','smallboy','smallgirl'}
for student in linuxs:
print(student)
了解的知识点:


#difference_update s1={1,2,3} s2={1,2,} print(s1-s2) print(s1.difference(s2)) #差集s1-s2 s1.difference_update(s2) #s1=s1.difference(s2) print(s1) #删除pop,discard,remove s2={1,2,3,4,5,'a'} print(s2.pop())#删除并且返回 set “s2”中的一个不确定的元素, 如果为空则引发 KeyError s2.discard('b')#如果在 set “s2”中存在元素 b, 则删除 s2.remove('b') #删除的元素不存在则报错 print(s2) #添加add s2.add('b') print(s2) #isdisjoint s1={1,2,3,4,5,'a'} s2={'b','c',} print(s1.isdisjoint(s2)) #两个集合没有共同部分时,返回值为True #update s2={1,2,3,4,5,'a'} s2.update({6,7,8}) #结果{1, 2, 3, 4, 5, 6, 7, 8, 'a'} print(s2) #list --> set l=['a','b',1,'a','a'] print(list(set(l)))#结果['b', 'a', 1] #str --> set print(set('hello')) #结果{'e', 'l', 'o', 'h'} #dict --> set print(set({'a':1,'b':2,'c':3})) #结果{'a', 'b', 'c'}
2.9 不可变集合(了解)
fset=frozenset({1,2,3})

















 9482
9482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









