






首先分析糗百页面:
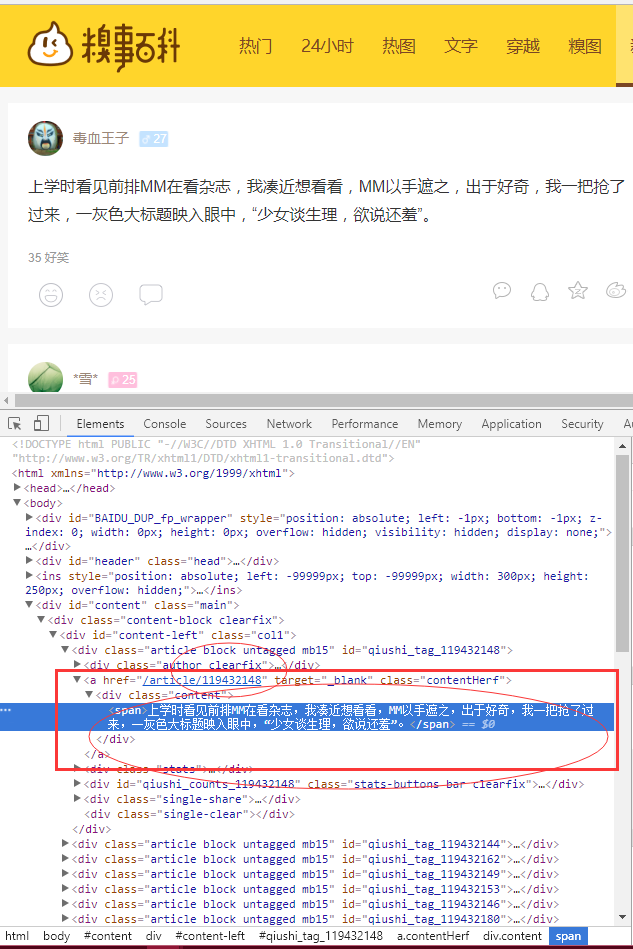
目标是获取文字内容和文章链接ID,并保存到文件。
#!/usr/bin/env/python
#coding:utf-8
if __name__ == '__main__':
from urllib import request,parse
import re
#抓取,获取源代码
url='https://www.qiushibaike.com/textnew/'
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36"
}
req=request.Request(url,headers=headers)
resp=request.urlopen(req)
html=resp.read().decode('utf-8')
if resp.getcode()!=200:
print('url open failed!')
#解析数据
pattern_id=re.compile(r'<a href="/article/(\d+)".*class=.contentHerf. >')
pattern_content=re.compile(r'<div class="content">.*?<span>(.*?)</span>',re.S)
ids=re.findall(pattern_id,html)
contents=re.findall(pattern_content,html)
data={}
for i in range(len(ids)):
pattern=r'<br/>'
content=re.sub(pattern,'\n', contents[i])
data[ids[i]]=content
#保存数据
directory='spider_qiubai/'
for key in data.keys():
f=open(directory+key+'.txt','w')
try:
f.write(data[key])
except Exception as e:
print("write file "+key+" failed! "+e)
else:
print("write file "+key+" successfully!")
finally:
f.close()
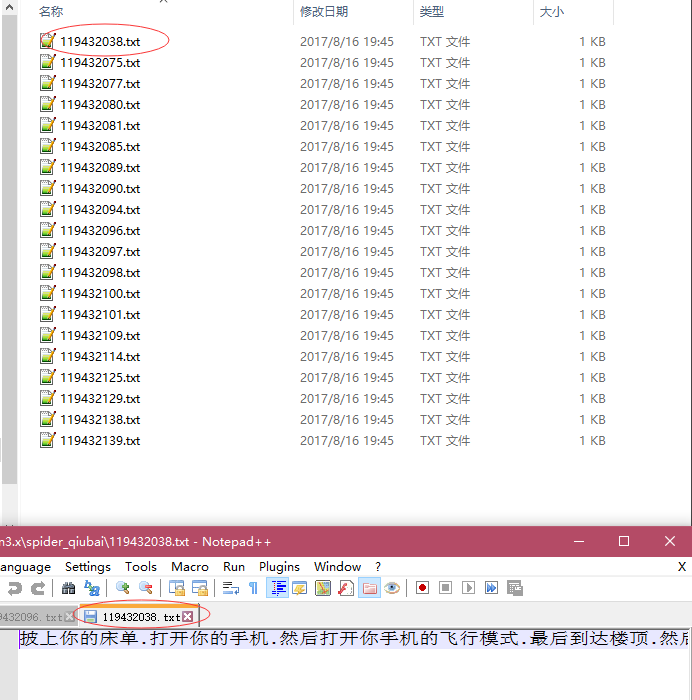
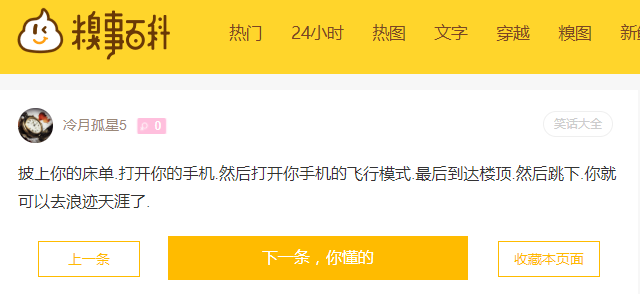
运行结果:

















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









