






 本文基于JDK1.7,介绍了Java中HashMap的使用。阐述了其底层数组加链表的数据结构,详细分析了创建集合、添加元素、获取元素、删除元素及遍历集合的步骤,还总结了put和get方法流程,最后提及扩容问题,指出扩容虽保证效率但耗时。
本文基于JDK1.7,介绍了Java中HashMap的使用。阐述了其底层数组加链表的数据结构,详细分析了创建集合、添加元素、获取元素、删除元素及遍历集合的步骤,还总结了put和get方法流程,最后提及扩容问题,指出扩容虽保证效率但耗时。
HashMap是Java开发中常用的集合,那么从我们创建一个空集合到,put添加、get获取元素经历了那些步骤呢?
说明:以下源码基于JDK1.7,32位
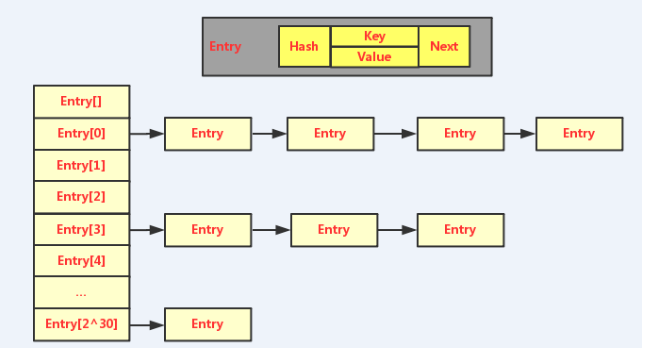
0.HashMap底层的数据结构是数组加链表的形式,存储结构如下图:
1.创建一个新的HashMap集合的构造函数:
//初始默认数组的大小
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f; //表示当map集合中存储的数据达到当前数组大小的75%则需要进行扩容
//构造函数 1
public HashMap(int initialCapacity, float loadFactor) {
//如果初始容量 小于0 则抛异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//超过了最大值,则取最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//初始因子为小于等于0,或者不存在则抛异常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
//构造函数 2
public HashMap(int initialCapacity) {
//调用构造函数 1
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//构造函数 3
public HashMap() {
//调用构造函数 1
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}分析:对于HashMap对的构造函数有三种,我们通常使用的构造函数 3 ,载荷因子表示当存储容量达到75%时需要对数组进行扩容。当选择 构造函数 2 和 构造函数 3 时,最终都会走构造函数1。
构造函数 1 :能够设置初始化数组长度,及载荷因子。
构造函数 2 :能够设置初始化数组长度,对于载荷因子默认为0.75。 会去调构造函数 1
构造函数 3 :默认初始化数组长度为16,载荷因子为0.75。 会去调构造函数 1
2.map集合添加元素,
map.put("key","value"); 。注意一个问题,map是允许存储key=null且value=null的,而hashTable则不允许,并且HashTable有synchronize修饰,故是线程安全的,hashMap是非线程安全。
//
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold); //步骤 1 首次添加时 threshold 为 16
}
if (key == null)
return putForNullKey(value); //步骤 2 如果添加的key = null,则进行单独存储
int hash = hash(key); //步骤 3 计算key的hash值
int i = indexFor(hash, table.length); //步骤 4 计算数据的存储位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) { //步骤5 遍历存储位置上的内容,如果key已存在则覆盖
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); //步骤6 如果table[i]上没有对应的key,则进行新添一个entry对象。
return null;
}步骤1:如果发现数组为空,则进行初始化数组长度为16,加载因为为0.75.
private static int roundUpToPowerOf2(int number) { //number = 16 返回 值为 16
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
/**
* 初始化数长度
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize); //计算容器大小
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity]; //新建Entry类型长度为capacity的数组
initHashSeedAsNeeded(capacity);
}步骤2:如果要存储的key=null,则需要单独调用putForNullKey(key),进行存储,默认存储的位置是table[0]位置,遍历table[0]位置上的内容。如果已经有存储了key=null的内容,则进行覆盖,并返回旧的value值,如果没有就新插入一个entry节点addEntry,并返回null。
/**
* 当key=null时,则把null存在table[0]处,已存在则覆盖。
*/
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}步骤3:计算key的hash值。
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}步骤4:计算key=value数据在table上的存储位置
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) { //length为table的长度
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}步骤5: 遍历table[i]存储位置上的内容,如果key已存在则覆盖,则返回oldValue
步骤6: 遍历table[i]存储位置上的内容,如果key不存在,则新插入entry对象。就是以链表的形式挂在table[i]上,新插入的不是挂在链表的尾部,而是头部,属于头插法。
//添加新的entry对象
void addEntry(int hash, K key, V value, int bucketIndex) {
//判断已存储的容量是否超出了负载因子,超出了则进行2倍扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); //2倍扩容
hash = (null != key) ? hash(key) : 0; //重新计算hash值
bucketIndex = indexFor(hash, table.length); //获得在新数组中的存储位置。
}
createEntry(hash, key, value, bucketIndex);
}
/**
* 创建新数组,并需要对原数据的内容进行重新计算存储位置
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}分析:对于当新插入一个数据时,会先判断存储容量是否达到了负载因子所允许的大小,如果达到了需要对原数组进行2倍扩容,并且需要重新计算数据在新数组的存储位置。进行重新计算存储位置和数据复制是很好是的。
3.map集合获取value元素,
value = map.get("key");
*/
public V get(Object key) {
if (key == null)
return getForNullKey(); //当key == null 时直接去table[0]处去获取
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
/**
* Offloaded version of get() to look up null keys. Null keys map
*/
private V getForNullKey() {
if (size == 0) {
return null;
}
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
/**
获取entry对象
*/
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}分析:对于get(key).先判断key是否为null,为null直接去table[0]位置遍历去取,取到则返回。如果不为null,则和put时的套路一样,先计算hash值,如果然后计算出bucketIndex,然后通过equal(key)遍历,遍历到则返回。
4.map.remove(key),
map集合一个key=value数据,原理:常规的链表删除操作
*/
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
/**
* Removes and returns the entry associated with the specified key
*/
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}分析:对于map集合的删除操作步骤,先通过hash方法找到数组上的位置,然后进行遍历,找到对应的key,把被删除的节点的上一个节点的指针指向被删除节点的下一个节点即可。
5.HashMap集合的遍历方式:
方式一,map.keySet()。会把所有的key装入set集合中,然后再对set集合遍历。
方式二, map.entrySet()。会把所有的entry对象放入set集合中,然后进行遍历set集合。
比较:方式二要优于方式一,因为方式一只是遍历获取到了所有key,如果要获取value,则需要重新遍历一次。方式二,直接把key,value直接获取到了,无需遍历第二次。
6.总结:
对于hashmap的put和get方法做汇总。
1.new首先初始化table数组大小为1 << 4, 即16.
2.每一次put时先判断key是否为null,如果为null,则遍历table[0]上的数据,如果已经存在key=null,则进行覆盖并返回oldValue,没有则插入到table[0]的链表头处。
3.如果put的key不为null,则先计算hash = hash(key),根据hash值结合table.length,计算出bucketIndex。即存储在table[i]处。
4.然后遍历table[i],使用equal(key),存在相同的就进行覆盖,返回oldValue。如同不存在就addEntry.链头添加。
5.addEntry时,先判断已经存储的容量是否达到了75%,达到了则进行new一个是原来2倍容量的新数组,需要对原数组存储的数据,从新计算存储位置进行复制,比较耗时。
6.对于get,则也是先计算hash(key),得出bucketIndex,即是在table上的存储位置,然后根据key.equals(key)遍历链表,找到对应的value值返回。
7.对于数据的remove,则就是链表的删除原理,使被删除数据的父节点指向被删除数据的子节点。
7.补充:hashmap的扩容问题:
** 随着HashMap中元素的数量越来越多,发生碰撞的概率就越来越大,所产生的链表长度就会越来越长,这样势必会影响HashMap的速度,为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理。该临界点在当HashMap中元素的数量等于table数组长度*加载因子。但是扩容是一个非常耗时的过程,因为它需要重新计算这些数据在新table数组中的位置并进行复制处理。‘**
reference: https://blog.youkuaiyun.com/cydbetter/article/details/80374205

















 2529
2529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









