






 本文介绍了机器学习算法调优的步骤,包括从简单算法开始,利用交叉验证集进行误差分析,以及如何在类偏斜问题中使用精确度和召回率进行评估。同时,讨论了大量数据和特征对算法性能的影响。
本文介绍了机器学习算法调优的步骤,包括从简单算法开始,利用交叉验证集进行误差分析,以及如何在类偏斜问题中使用精确度和召回率进行评估。同时,讨论了大量数据和特征对算法性能的影响。
Q1首先要做什么
本章将在随后的课程中讲误差分析,然后怎样用一个更加系统性非方法,从一堆不同的方法中,选取合适的那一个。
Q2误差分析
构建一个学习算法的推荐方法为:
(1)从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法;
(2)绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择;
(3)进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势。
在交叉验证集上做误差分析,不要在测试集在做误差分析。
Q类偏斜的误差度量
举例:恶性肿瘤的概率只有0.5%,这时如果不用神经网络全部预测为两性,其误差为0.5%,而用神经网络可能的出来的误差为1%,显然通过误差率来作为系统好坏的判别标准是不好的,在这种类偏斜的问题中,这时候需要用到精确度(precision,又称查准率)和召回率(recall,又称查全率)。
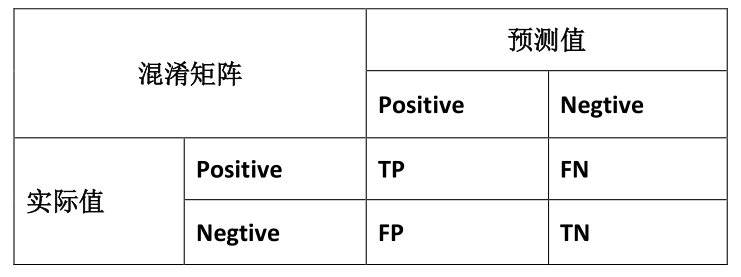
(1)精确度(precision):是从预测的视角看,真正为真与预测为真的比值即TP/(TP+FP)。
(2)召回率(recall):是从样本的视角看,被预测出来的正例与总正例的比值即TP/(TP+FN)。
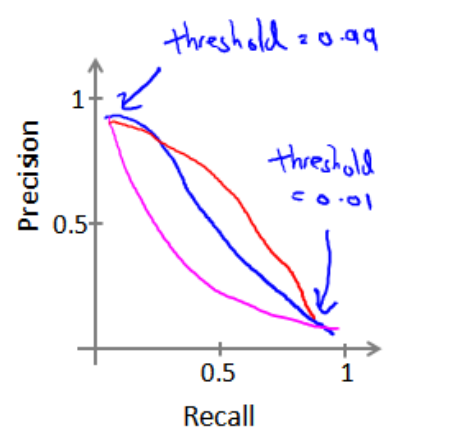
Q4查准率和查全率之间的权衡
(1)查全率与查准率的关系:
(2)为了有一个单一的指标定义了F1值:
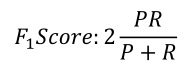
Q5机器学习的数据
有大量的数据(避免了方差),以及足够多的特征(避免了偏差),一般可以得到一个高性能的算法。

















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









