



 本文提供Heritrix1.14.4版本的详细配置步骤,包括环境搭建、常见错误解决方法及运行测试等内容。
本文提供Heritrix1.14.4版本的详细配置步骤,包括环境搭建、常见错误解决方法及运行测试等内容。
本教程,结合本人亲身实践,不仅适合于最新版本Heritrix 1.14.4,更适合其他任何版本。Heritrix具体下载地址如下:
http://sourceforge.net/projects/archive-crawler/files/archive-crawler%20%28heritrix%201.x%29/
本实例所用的为Heritrix1.14.4的源代码版本,即你只需下载一个文件即可:heritrix-1.14.4-src.zip。 之所以采用源代码版本,是因为本实例中,需要对Heritrix 进行一些扩展,以适应本实例的需求。网上教程多是下载两个文件heritrix-1.14.4.zip和heritrix-1.14.4-src.zip,即费时,又大多无效,按照网上流传配置办法很难成功。这里我已在MyEclipse里顺利配置完成并抓取到所需网页,下面开始配置流程:
1、将heritrix-1.14.4-src.zip的压缩包解压,目录中的lib和src是本实例需要的两个文件夹。 “lib”文件夹下存放的是Heritrix 运行时候所需要的第三方类库,“src”文件夹下就是Heritrix 的源代码。
2、在Eclipse 中打开菜单:File/new/Java Project,并在“Project name”中输入“Heritrix”,这样就新建了一个项目名称叫做Heritrix ,同时将源代码文件夹下的lib文件夹拖放置新建好的项目工程Heritrix 下。在Elipse里的项目工程内,找到刚刚拖进去的lib文件夹,把里面所有的.jar文件选中,右键Build Path→ Add to...,这样便完成了运行库的添加任务。
3、将位于Heritrix 源代码文件夹下的src\ Java \ 的org和st两个文件夹直接拖进Heritrixj工程的src下。如果当添加完后报错,只是因为你的太低版本的Eclipse默认的编译版本为1.4,所以要改成1.5或者1.6版本。单击菜单中的Window ,选择Preferences之后,展开左边的Java选项,单击其中的“Compiler”,将Compiler compliancelevel改成J2EE1.6或1.5。
4、将位于解压后文件夹下的src \ conf\下的所有文件和文件夹拖至Heritrix 工程的src内,在src 内找到heritrix .properties并打开。 该文件是Heritrix 的配置文件,在“heritrix .cmdline.admin= ”后边添加用户和密码,格式如:“admin:admin”,在登录Heritrix 的管理界面时需要此用户名和密码。 在配置文件中还能够指定Heritrix 管理界面的访问端口,建议可为8080端口。
错误1:Access restriction: The type FileURLConnection is not accessible due to restriction on required library C:\Program Files\Java\jdk1.6.0_20\jre\lib\rt.jar,如图 1 所示。
解决方案:这是 JRE 的访问限制导致报错,在 MyHeritrix 工程上右键单击选择“Build PathConfigure Build Path …”,然后选择 Library 选项卡,将“JRE System Library”删除然后重新导入一下即可修复。或者选择“WindowsPreferencesJavaCompilerErrors/Warnings”找到“Deprecated and restricted API”下的“Forbidden reference (access rules)”,将默认设置“Error”改为“Warning”或“Ignore”。
图 1. Access restriction 错误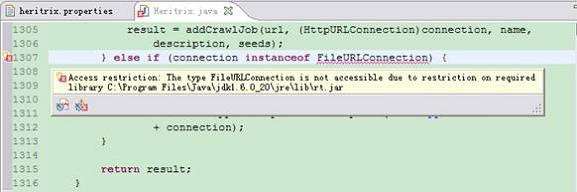
错误2:这个时候会报错NullPointerException 的错误:这个错误的原因是缺少了“tlds-alpha-by-domain.txt”文件,在 heritrix-1.14.4-src\src\resources\org\archive\util 下可以找到该文件,将其拷贝到org.archive.util包(MyHeritrix\src\org\archive\util) 中即可。
图2. NullPointerException 错误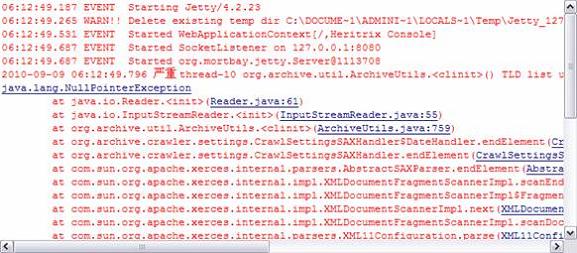
5、将Heritrix 源代码文件夹下的src下的其他文件夹,即除conf 和Java两个文件夹以外的所有文件夹,拖至Heritrix 项目工程下,
6、至此,Heritrix 已经可以运行起来了。 运行Heritrix ,选择执行org.archive.crawler包下的heritrix.java文件,以Java application方式运行。然后Heritrix 会在控制台输出一段信息,最后是版本号,这就表示Heritrix 已经运行成功了。
7、启动浏览器并在浏览器的地址栏中输入http://localhost:8080 便可看到Heritrix 的登录界面。用户名和密码处分别输入在配置文件中,输入的admin和admin,单击“Login”按钮后便能看到Heritrix 的控制台界面。
到此,Heritrix安装与配置完成。
最好的参考教程:http://www.ibm.com/developerworks/cn/opensource/os-cn-heritrix/index.html?ca=drs-#major2 (很好的错误解决方案)

















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









