






 博客围绕二叉树展开,题目是找到树中两个指定节点的最近公共祖先,给出了最近公共祖先的定义,还说明了所有节点值唯一,指定节点不同且都存在于树中,最后给出了解法的转载链接。
博客围绕二叉树展开,题目是找到树中两个指定节点的最近公共祖先,给出了最近公共祖先的定义,还说明了所有节点值唯一,指定节点不同且都存在于树中,最后给出了解法的转载链接。
题目描述:
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
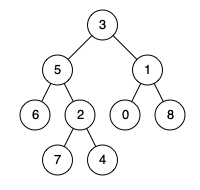
示例 1:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。示例 2:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出: 5
解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
解法:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
// method1: recusive algorithm
bool inTree(TreeNode* root, TreeNode* node){
if(root == node){
return true;
}else if(root == NULL){
return false;
}else{
return inTree(root->left, node) || inTree(root->right, node);
}
}
// method2:
bool searchTree(TreeNode* root, vector<TreeNode*>& lst, TreeNode* node){
if(root == NULL){
return false;
}else{
lst.push_back(root);
if(root == node){
return true;
}else{
if(searchTree(root->left, lst, node)){
return true;
}else if(searchTree(root->right, lst, node)){
return true;
}else{
lst.pop_back();
return false;
}
}
}
}
TreeNode* lowestCommonAncestor1(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == p || root == q){
return root;
}else{
bool found1 = inTree(root->left, p);
bool found2 = inTree(root->left, q);
if(found1 && found2){
return lowestCommonAncestor(root->left, p, q);
}else if(!found1 && !found2){
return lowestCommonAncestor(root->right, p, q);
}else{
return root;
}
}
}
TreeNode* lowestCommonAncestor2(TreeNode* root, TreeNode* p, TreeNode* q) {
vector<TreeNode*> lst1, lst2;
searchTree(root, lst1, p);
searchTree(root, lst2, q);
int sz1 = lst1.size();
int sz2 = lst2.size();
int i = 0, j = 0;
while(i < sz1 && j < sz2 && lst1[i] == lst2[j]){
i++;
j++;
}
return lst1[i-1];
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q){
return lowestCommonAncestor1(root, p, q);
}
};
















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









