



 本文详细介绍了Milvus 0.6.0版本的关键系统配置项,如`cpu_cache_capacity`和`use_blas_threshold`,以及API参数,如`index_file_size`和`nlist/nprobe`,并提供了性能测试和设置建议。通过合理设置这些参数,可以优化向量数据库的搜索性能和查询效率。
本文详细介绍了Milvus 0.6.0版本的关键系统配置项,如`cpu_cache_capacity`和`use_blas_threshold`,以及API参数,如`index_file_size`和`nlist/nprobe`,并提供了性能测试和设置建议。通过合理设置这些参数,可以优化向量数据库的搜索性能和查询效率。
在Milvus官网上有一篇《如何选择索引类型》的文章,介绍了如何根据需要选择索引类型。但是仅仅知道选择索引类型还是不够的。本文针对Milvus 0.6.0版本的几个关键系统配置项以及API参数进行详细说明与测试验证,并给予如何设置的建议。
(一)系统配置项
系统配置项是Milvus在启动服务之前进行的参数设置,需要在Milvus docker镜像启动前对server_config.yaml文件进行修改。下面我们详细说明几个影响性能的重要参数。
1. cpu_cache_capacity
cpu_cache_capacity用于限定Milvus运行过程中用于缓存向量(索引)数据的内存量,其单位为GB。设置该值时要根据数据量考虑。数据量怎样计算呢?有两种类型的数据:
1)原始向量数据,没有建立索引前,搜索是基于原始数据的暴力搜索,所需要的内存量就是原始向量的总数据量。向量的每个维度是以float来表示的,我们知道每个float类型占用4个字节,因此总数据量可以依据这个公式计算:4*向量维度*向量总条数
2)索引数据,建立好索引后,搜索就会基于索引执行,因此这时需要的内存量就是索引的数据量。不同的索引,占用空间大小是不一样的。对于IVFLAT,其数据量基本等同于原始向量的总数据量;而对于SQ8,其数据量大约是原始向量总数据量的30%左右。
因此,根据情况设置cpu_cache_capacity,使之大于搜索所需的数据量(前提是机器的内存要足够),搜索性能最佳。但不需要大太多,因为内存足够之后再增大该值并不会产生性能的变化。反之,如果设置的值小于数据量,Milvus会花费大量时间在内存数据的置换上,严重影响查询性能。
关于内存数据的置换,这里解释一下:Milvus是把向量数据分批保存在磁盘上,默认条件下每个数据文件是1GB,假设我们有10GB数据,分成10个数据文件,假设cpu_cache_capacity设置为5GB,当搜索开始时,会将文件数据一个个加载进内存等待计算,当加载完第5个文件后,缓存空间已被占满,开始加载第6个文件时,发现空间不足,于是Milvus会将第一个文件数据从内存中删除,从磁盘加载第6个文件数据,这样就保证缓存占用空间不会超过cpu_cache_capacity所设定的值。相对于索引运算来说,读磁盘是相对比较耗时的操作,因此要尽量避免内存数据的置换。
然后我们来看怎样确定合理的cpu_cache_capacity值。举例来说,假设导入了1000万条向量,每条向量的维度是256,那么每条向量占用:256*4=1024字节(1KB)。原始向量的数据总量为:1000万*1KB=10GB。如果没有建立任何索引,那么cpu_cache_capacity的值应该设置为大于10,这样所有的原始向量数据都会被加载进内存,并且不会发生置换。如果建立了索引,对于IVFLAT来说,cpu_cache_capacity的值也要设置为大于10;对于SQ8来说,其数据量大约为3GB,所以只需把cpu_cache_capacity设为4就足够。
以下是使用公开数据集sift1b的5000万条数据针对cpu_cache_capacity的一个性能测试(单位:秒),索引类型为SQ8。这个数据集有5000万条向量,向量维度是128。我们建立了SQ8索引,所以查询所需的数据量为5000万*128*4*0.3=7.5GB。我们分别将cpu_cache_capacity设为4GB,10GB,50GB,使用相同的查询参数来查询,性能对比如下表(截图有点粗糙,见谅):
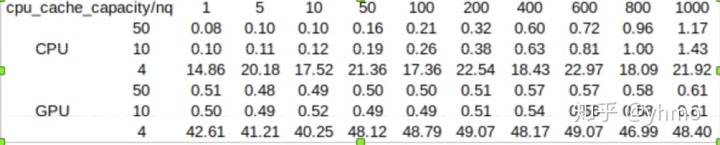
从上图可以看出,在CPU和GPU模式下,对于大于索引大小的cpu_cache_capacity的值(10G和50G),其搜索速度基本一致;而当该参数的值设置为4G时,由于内存数据被频繁置换,搜索性能降低了两个数量级。
2. use_blas_threshold
Milvus在进行搜索时,会调用faiss库的底层函数进行向量距离的计算。对于使用CPU的计算,faiss库提供了两种计算方式:
1)使用OpenBLAS计算库
2)直接使用CPU指令集
根据我们的经验,使用CPU指令集性能会好一些,但在相同的搜索条件下,有可能出现前后两次耗时相差两倍这样的情况,比如前一次0.1秒,后一次0.2秒,我们把这叫做性能抖动。用OpenBLAS库性能稍差,尤其在nq比较小的时候,性能会比CPU指令集慢(有可能慢两倍以上),但是性能不会出现抖动,相同搜索条件下的多次查询耗时基本相同。
具体要使用哪种计算方式则取决于use_blas_threshold的值以及搜索参数nq(目标向量条数),如果 nq大于等于use_blas_threshold ,使用 OpenBLAS库。如果 nq小于use_blas_threshold ,使用CPU指令集。
以下是使用公开数据集sift1b的5000万条数据针对use_blas_threshold做的一个性能测试(单位:秒),索引类型为SQ8:

从图上可以看出,在CPU模式下,如果use_blas_threshold的值设置为1100,所有测试nq都小于该值,使用了CPU指令集,其查询性能基本上是线性增长的,并且性能较好。当use_blas_threshold设为500时,则可以明显地观察到,在nq=500之前的测试结果和1100那组相近,nq大于500之后因为使用了OpenBLAS库,性能慢了数倍;
在纯GPU模式下,因为计算在GPU中进行,与CPU无关,因此use_blas_threshold的值不会对搜索性能产生影响。
3. gpu_search_threshold
在GPU模式下,实际上也可以使用CPU进行查询,具体使用那种设备是由gpu_search_threshold以及nq共同决定的。如果nq大于等于gpu_search_threshold,使用GPU进行搜索;如果nq小于gpu_search_threshold,使用CPU进行搜索。为什么在GPU模式下也提供了CPU计算的选项呢?这是由于利用GPU进行搜索时需要将数据从内存拷贝至显存,这步需要耗费一些时间。当nq较小时,显卡并行计算的优势发挥不出来,使得数据拷贝的时间占比较大,总体性能反而比CPU计算要慢。
以下是使用公开测试数据集sift1b的5000万条数据针对gpu_search_threshold的一个性能测试(单位:秒),索引类型为SQ8:

从上图可以看出,当gpu_search_threshold设置为1时,Milvus为纯GPU模式,完全利用GPU进行搜索,nq从1到1000,耗时基本相同,这是因为GPU的并行度很高,1000条向量可以同时计算,跟1条向量花费的时间差不多;当参数值为500时,可以看到nq小于500时是利用CPU进行搜索,因为nq从1到400的耗时是线性递增的,这是因为CPU没有那么多核,无法同时计算几百条向量,而nq大于等于500时利用GPU进行搜索,耗时变化很小;当参数值为1100时,完全利用CPU进行搜索,nq从1到1000的耗时都是呈线性递增的态势。
小结
cpu_cache_capacity:该值大于搜索所需的数据量大小时,搜索性能最好。设值不能超过系统内存。
use_blas_threshold:CPU模式时,nq小于该值时搜索性能更好,但性能有抖动;nq大于等于该值时搜索性能略差,但搜索耗时比较稳定。在使用GPU计算时,该值对性能没有影响。
gpu_search_threshold:与nq一起决定了是使用CPU计算还是使用GPU计算,nq较小时用CPU计算性能较好,nq较大时用GPU计算性能较好,因此综合考虑根据数据集的规模和硬件性能,使用gpu_search_threshold来确定使用哪种硬件来计算。
(二)API参数设置
API参数包括调用create_table,create_index和search时进行的参数设置,它们会对搜索性能产生影响。
1. index_file_size
在调用create_table时有一个index_file_size参数,用来指定数据存储时单个文件的大小,其单位为MB,默认值为1024。我们知道,当向量数据不断导入时,Milvus会把数据增量式地合并成文件,当某个文件达到index_file_size所设置的值之后,这个文件就不再接受新的数据,Milvus会把新的数据存成另外一个文件。这些都是原始向量数据文件,如果建立了索引,则每个原始文件会对应生成一个索引文件,对于IVFLAT索引来说,索引文件的大小基本等于对应的原始文件大小,而对于SQ8索引来说,索引文件大小大约是原始文件的30%左右。
Milvus在进行搜索时,是依次对每个索引文件进行搜索。根据我们的经验,当index_file_size从1024改为2048时,搜索性能会有30%~50%左右的提升。但要注意如果该值设的过大,有可能导致大文件无法加载进显存(甚至内存),比如显存只有2GB,该参数设为3GB,显存明显放不下。常用的index_file_size为1024MB和2048MB。
以下是使用公开测试数据集sift1b的5000万条数据针对gpu_search_threshold的一个性能测试(单位:秒),索引类型为SQ8:

如上图所示,在CPU模式和GPU模式下,index_file_size设为2048MB,其搜索性能相对于1024MB有显著提高。
2. nlist和nprobe
nlist是调用create_index时设置的参数,nprobe则是调用search时设置的参数。我们知道,IVFLAT和SQ8索引都是通过聚类算法把大量的向量划分成很多‘簇’(也可以叫‘桶’),nlist指的就是聚类时划分桶的总数。通过索引查询时,第一步先找到和目标向量最接近的若干个桶,第二步在这若干个桶里通过比较向量距离查找出最相似的k条向量。nprobe指的就是第一步若干个桶的数量。
通常来说,增大nlist会使得桶数量变多,每个桶里的向量数量减少,所需的向量距离计算量变小,因此搜索性能提升,但由于比对的向量数变少,有可能会遗漏正确的结果,因此准确率下降;增大nprobe就是搜索更多的桶数,因此计算量变大,搜索性能降低,但准确率上升。具体情况在面对不同分布的数据集时会产生一些差异,数据集的规模也会影响nlist和nprobe的选择。通常情况下,我们推荐的nlist值为4 * sqrt(n),其中n为数据的向量总数;而nprobe的值则需要综合考虑在可接受的准确率条件下兼顾效率,比较好的做法是通过多次实验确定一个合理的值。
以下是使用公开测试数据集sift1b的5000万条数据针对nlist和nprobe的一个性能测试(单位:秒),索引类型为SQ8:
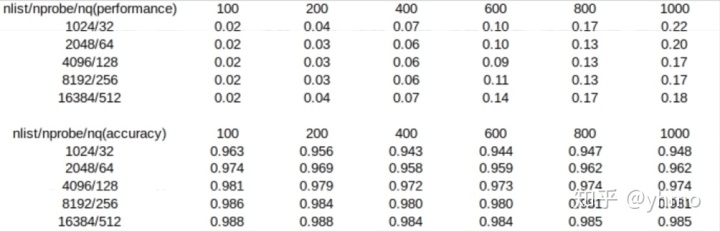
上图分别是采用不同的nlist/nprobe组合时的搜索性能和准确率对比。因CPU和GPU测试结果类似,此处仅展示GPU测试的结果。在本次测试中,对成比例增长的nlist/nprobe而言,随着他们的增大,准确率呈现上升的趋势,性能则在nlist为4096和nprobe为128时呈现最好的情况。因此在实际选择nlist和nprobe的值时,需要针对不同数据集,根据用户自己的需求,在速度和准确率两者之间进行合适的取舍。
小结
index_file_size:数据量大于该值时,参数值越大搜索性能越好。
nlist和nprobe:两者结合综合考虑,需用户在性能和准确率之间进行取舍。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









