






Redis 中 默认会开启rdb 持久化方式,aof 默认不开启,Redis 提供不同级别的持久化方式
rdb: 在指定的时间间隔对你的数据进行快照存储
aof:记录每次Redis服务写操作,当Redis重启时会重新执行这些命令来恢复数据。aof以Redis协议 将每次写的命令追加到文件的末尾
查看redis.conf文件
aof 配置
[root@data-chain redis]# grep 'appendonly' redis.conf
appendonly no
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
rdb 配置
[root@data-chain redis]# grep 'save' redis.conf
# save <seconds> <changes>
# Will save the DB if both the given number of seconds and the given
# In the example below the behaviour will be to save:
# Note: you can disable saving completely by commenting out all "save" lines.
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# save ""
save 900 1
save 300 10
save 60 10000
- rdb优点
rdb是一个非常紧凑的文件,他保存了指定时间的数据集,适合做数据备份(比如可以每一小时保存过去24小时的数据;每一天保存过去30天的数据)
rdb在在保存rdb文件时,父进程会fork出一个子进程,所有的工作都由子进程来完成,父进程不需要做任何事情,所以rdb持久化方式可以最大化Redis性能
- rdb缺点
rdb是在一定的时间段里保存数据,如果Redis服务器意外down机,这时候可能会造成数据丢失(比如 我是5分钟保存一次数据,万一服务器意外挂了,我可能就会丢失几分钟的数据)
rdb需要经常fork子进程保存数据集到磁盘上,如果redis数据巨大的话,整个过程会非常耗时
- rdb测试
默认情况下redis启用rdb方式,但是在启动redis 还是要指定默认的配置文件(redis 默认的rdb时间比较久,为方便测试 所以改下rdb得快照时间,改成【save 1 1】:表示每秒有一个key改变)
启动服务:
./redis-server ../redis.conf &
现在使用redis-cli 连接redis服务器,设置值
127.0.0.1:6379> set name zhangxs
OK
这时redis会打印出日志
[root@vm1 src]# 5897:M 14 Jul 11:31:01.938 * 1 changes in 1 seconds. Saving...
5897:M 14 Jul 11:31:01.939 * Background saving started by pid 5910
5910:C 14 Jul 11:31:01.943 * DB saved on disk
5910:C 14 Jul 11:31:01.943 * RDB: 6 MB of memory used by copy-on-write
5897:M 14 Jul 11:31:02.039 * Background saving terminated with success
然后杀掉redis进程,重启服务,之前set的值 还是存在
- aof优点
• aof会让你的redis 更加耐久,你可以使用不同的fsync策略(无fsync,每秒一次sync,每次写入sync),默认情况下redis 是每秒一次sync,这样redis性能还是非常好的,redis的主进程会尽量处理客户端的请求,一旦出现故障,你最多丢失1秒的数据。
• aof文件是一个只进行追加的日志文件,即便是因为磁盘满了或者意外down机,也可以使用redis-check-aof 进行修复命令
• 当aof文件体积过大时,redis 后台进程会自动对aof文件进行重写,重写后的文件包含重写前文件最小的命令集合,整个过程是安全的
• aof有序的保存了文件写入的命令,它使用的redis协议,这个协议的可读性很高。比如,如果我不小心执行了flshAll命令,只要你的aof文件没有被重写,你可以直接在aof文件的末尾删除flushAll命令,然后重启服务器。你的数据就会重新回到flushAll之前的数据集。
- aof缺点
在相同的数据集下,aof文件的体积要大于rdb文件
根据所使用的sync的策略,aof写入的速度可能要比rdb慢。一般情况下,每秒的sync的性能依然很高
至于使用哪种持久化方式,取决于自己的需求,一般情况下 两种都会使用, rdb 可以方便的用来做定时数据备份
- rdb的工作方式
redis会调用forks 生成一个子进程
子进程复制数据集到一个临时的rdb文件中
当子进程完成对数据集的复制后,redis会用新的rdb文件,并删除旧得rdb文件
- aof 工作方式
打开aof方式,在redis.conf中配置
appendonly yes
- aof 模式的三种选项
appendfsync always //每次有写入命令都会同步
appendfsync everysec //每秒同步一次写入命令
appendfsync no //让操作系统刷新输出缓冲区。
- Aof 工作方式
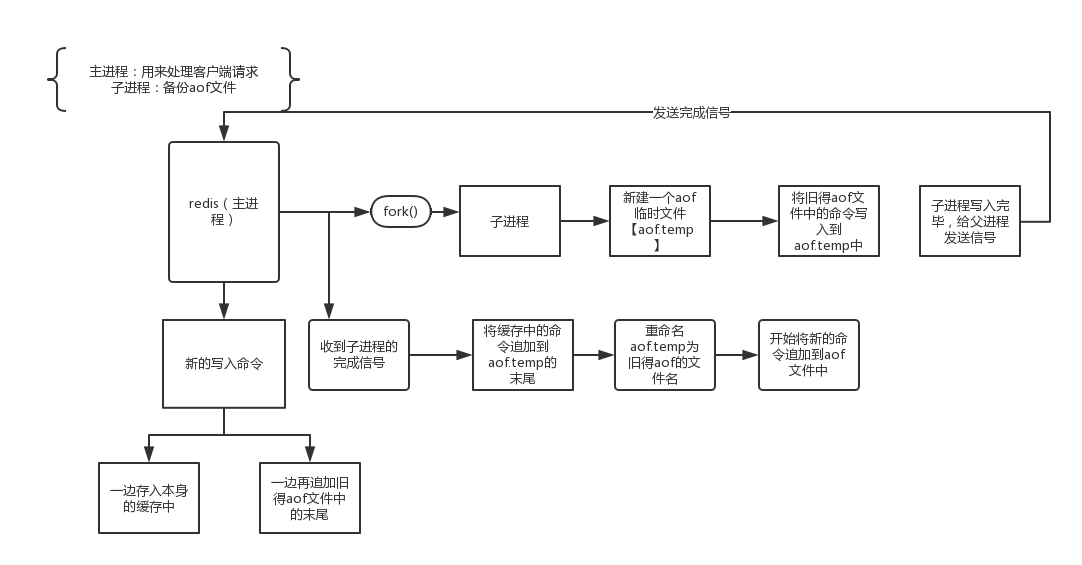
- 从rdb模式 转到aof 模式(Redis2.2之后可以在不重启的情况下,从aof到rdb,并且rdb的数据还会同步到aof 中)
测试数据(当前还在rdb 持久化模式中):
127.0.0.1:6379> set fang cuixian
OK
127.0.0.1:6379> exit
开始步骤:
• 备份最新的dump.rdb文件,并放到一个安全的地方(为了防止意外)
• 使用命令:
[root@vm1 src]# redis-cli config set appendonly yes
OK
[root@vm1 src]# redis-cli config set save ""
OK
这个是退出redis-cli客户端后的命令,如果在redis-cli内,使用 config set appendonly yes和config set save ""
执行上面两个命令后查看redis日志:
6044:M 14 Jul 12:22:49.893 * 1 changes in 1 seconds. Saving...
6044:M 14 Jul 12:22:49.895 * Background saving started by pid 6049
6049:C 14 Jul 12:22:49.900 * DB saved on disk
6049:C 14 Jul 12:22:49.901 * RDB: 6 MB of memory used by copy-on-write
6044:M 14 Jul 12:22:49.995 * Background saving terminated with success
6044:M 14 Jul 12:23:36.725 * Background append only file rewriting started by pid 6051
6044:M 14 Jul 12:23:36.767 * AOF rewrite child asks to stop sending diffs.
6051:C 14 Jul 12:23:36.767 * Parent agreed to stop sending diffs. Finalizing AOF...
6051:C 14 Jul 12:23:36.767 * Concatenating 0.00 MB of AOF diff received from parent.
6051:C 14 Jul 12:23:36.767 * SYNC append only file rewrite performed
6051:C 14 Jul 12:23:36.767 * AOF rewrite: 6 MB of memory used by copy-on-write
6044:M 14 Jul 12:23:36.843 * Background AOF rewrite terminated with success
6044:M 14 Jul 12:23:36.843 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
6044:M 14 Jul 12:23:36.843 * Background AOF rewrite finished successfully
可以看到aof同步 写入成功。
• 然后修改redis.conf文件,将appendonly 设置为yes,要不然重启服务器后 又会使用之前的配置。
关闭 rdb模式,不关也可以,两个持久化模式可以同时存在,一般情况下也是这样,这里为了测试,所以关掉。
• 然后杀死redis服务,再重新启动Redis服务,进入redis-cli客户端,查看刚才的测试数据,这个测试数据是在rdb模式下执行的。
[root@vm1 src]# redis-cli
127.0.0.1:6379> get fang
"cuixian"
可以看到在 在rdb模式下 写的命令,在转换为aof模式后,数据还在。
参考文档:https://redis.io/topics/persistence

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









