



 本文详细介绍了一个包含Hadoop、Spark等组件的大数据实验环境搭建过程,适用于学习和实践大数据技术。
本文详细介绍了一个包含Hadoop、Spark等组件的大数据实验环境搭建过程,适用于学习和实践大数据技术。
>大数据实验环境
- Hadoop 2.7.3
- Flume 1.7.0
- Hive 2.3.0
- Storm 1.0.3
- HBase 1.3.1
- Pig 0.17
- Spark 2.1.0
- Zookeeper 3.4.10
- Sqoop 1.4.5
- Hue 4.0.1
- Scala语言:用于开发Spark
- MySQL 5.7.19
- 其他环境:Redhat7.4 x86_64,Tomcat7,JDK1.8
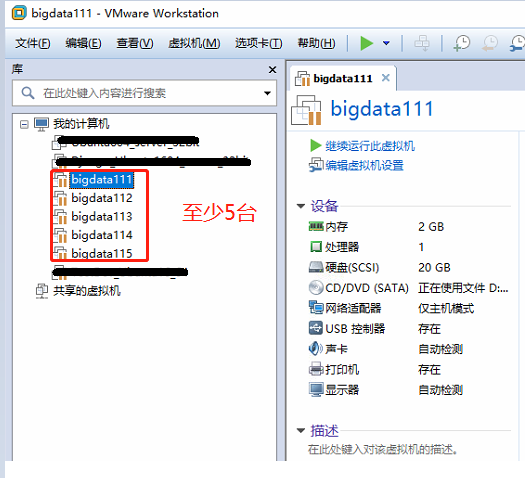
- PC、服务器环境:由于至少需要5台虚拟机(每台内存至少2G),因此如果是个人PC的话,至少8G内存(8G是乞丐版)!服务器安装的话推荐!
>Redhat7虚拟机安装与配置
由于Hadoop支持本地模式(1台),伪分布模式(1台),全分布模式(3台)。所以为了学习,至少搭建5台虚拟机。下面演示的是一台虚拟机的安装与配置,其他虚拟机参照第一台配置即可。
-
VMware自定义安装虚拟机
新建虚拟机-自定义
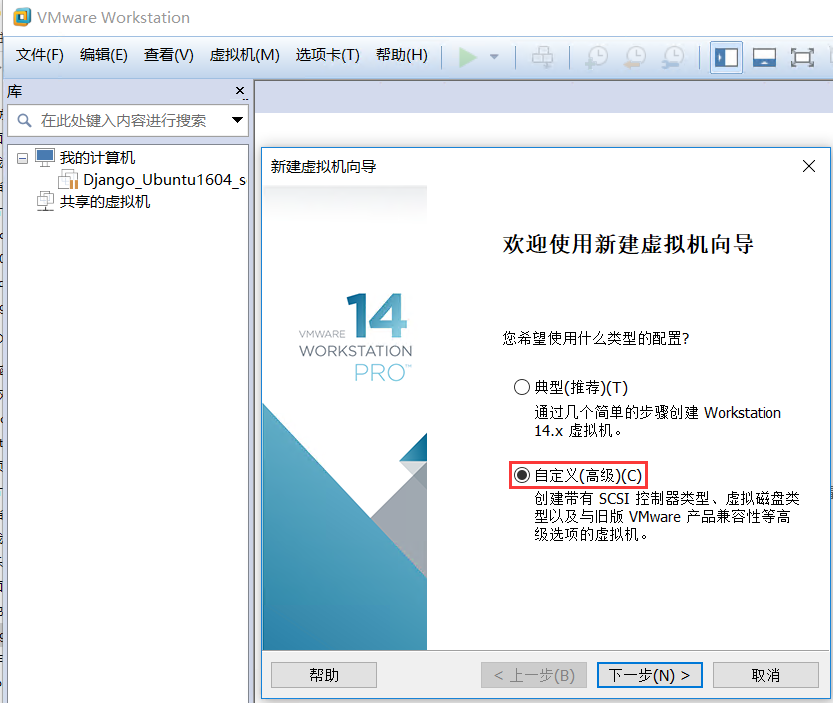
硬件兼容性-12
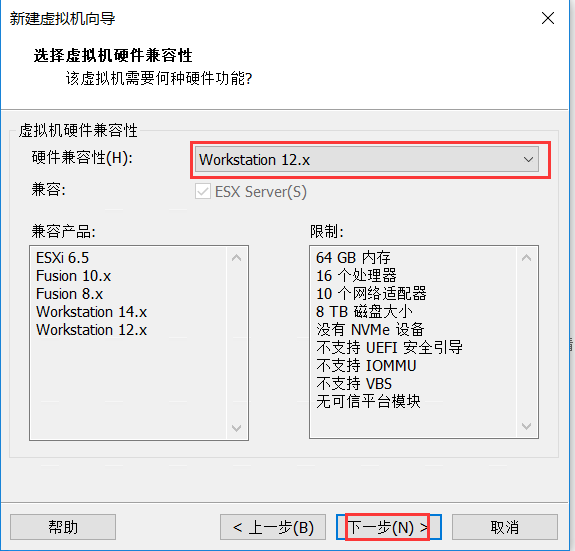
稍后安装操作系统
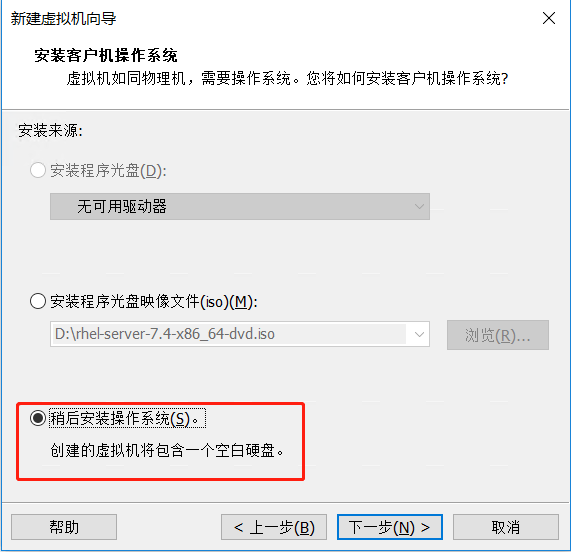
系统类型为Linux-Redhat7 64位
设置虚拟机名称和位置
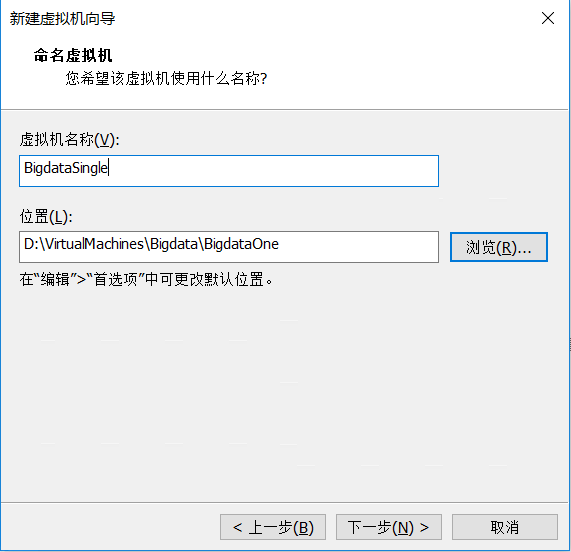
处理器配置(最低配1:1也可以)
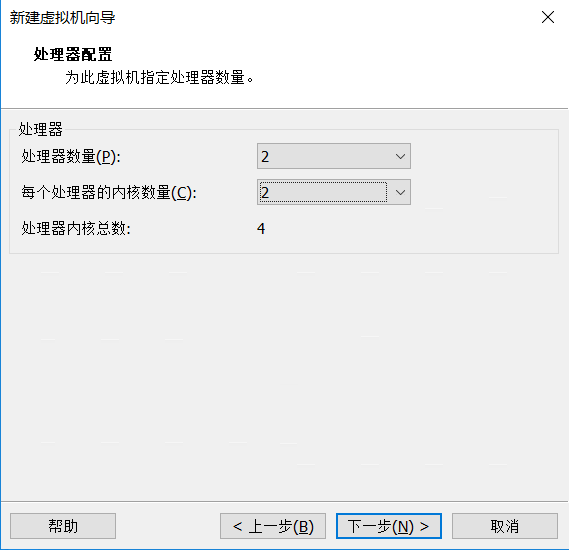
内存至少2G
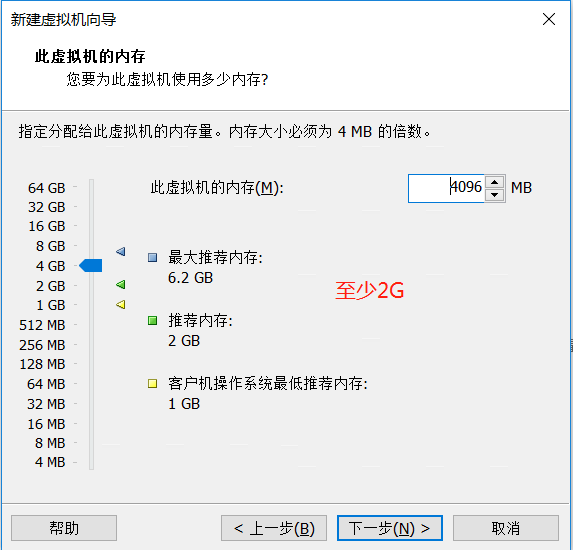
网络模式选择:只要可以保证虚拟机可以互相联通,可以选择任意类型。
其他设置默认即可:
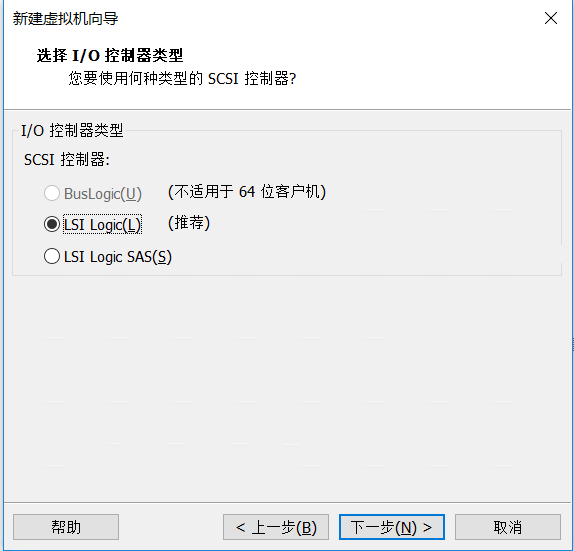
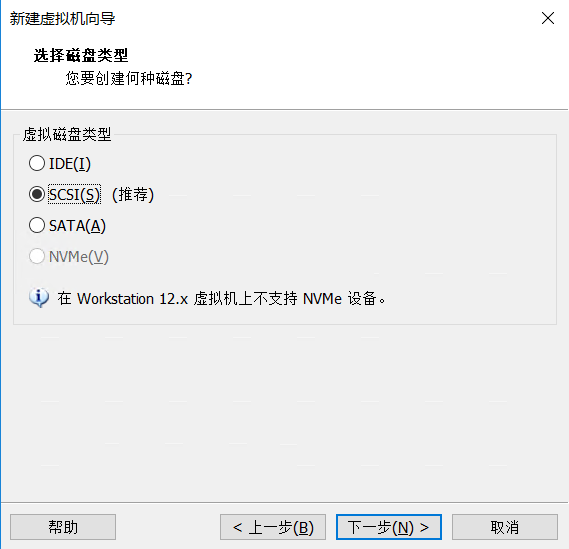
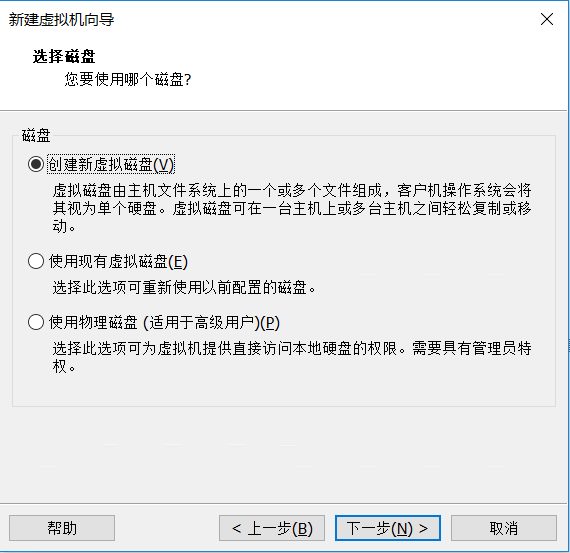
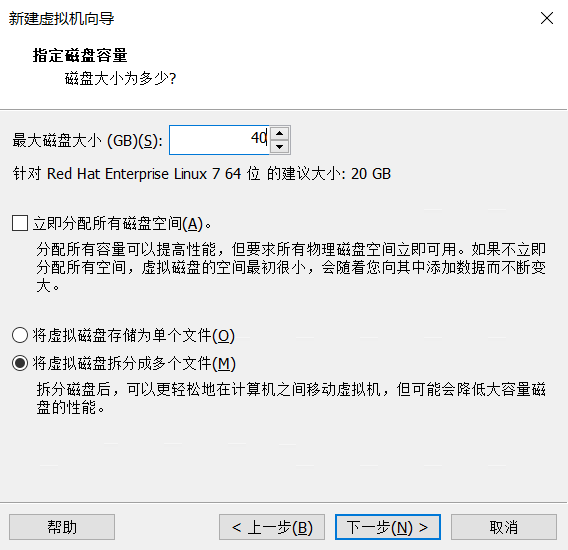
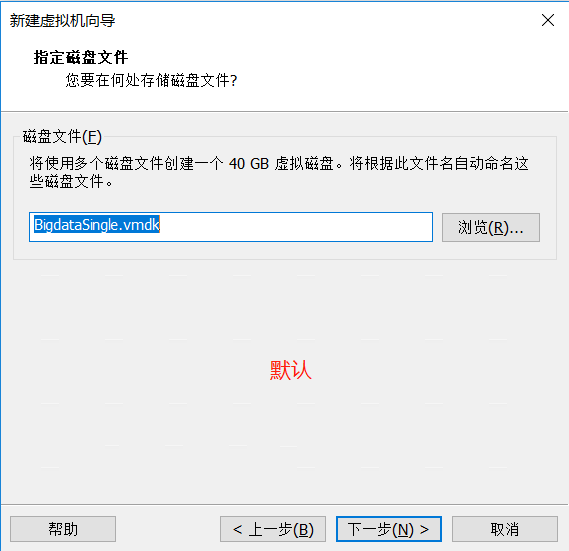
点击完成即可,启动虚拟机前先配置加载的ISO(Redhat7的安装镜像)
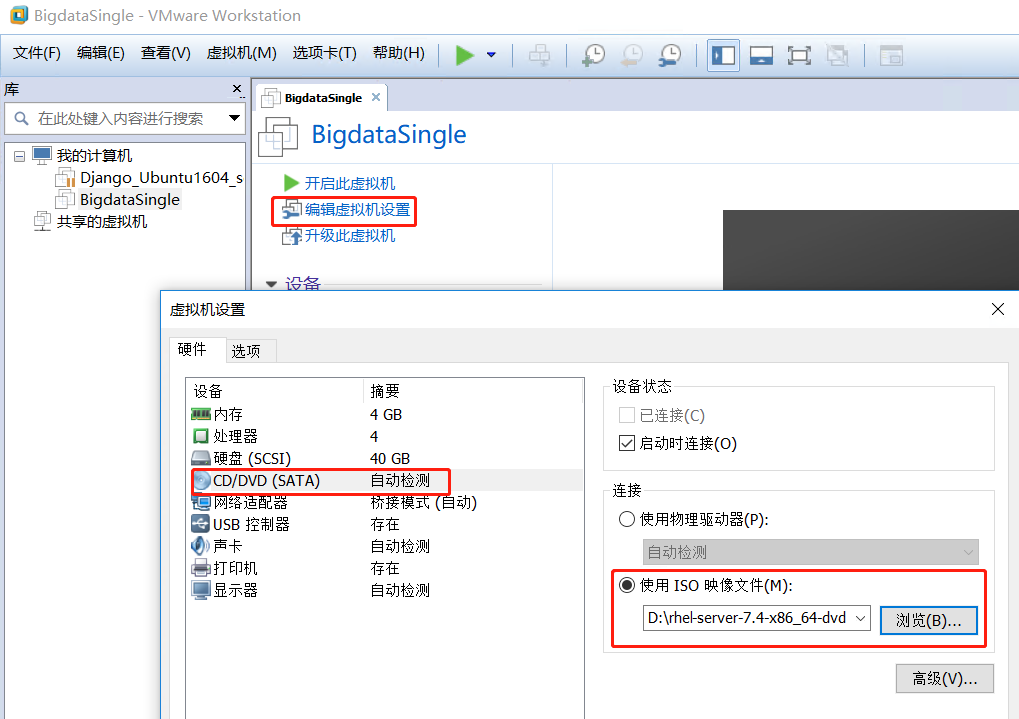
开启虚拟机,下面开始配置
-
配置虚拟机
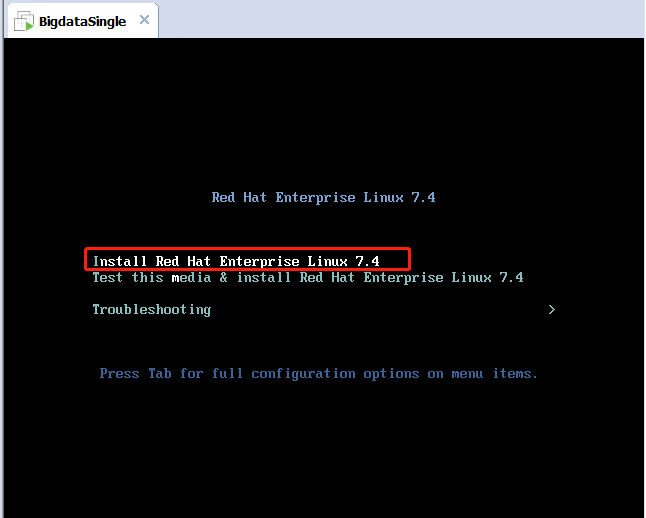
选择安装
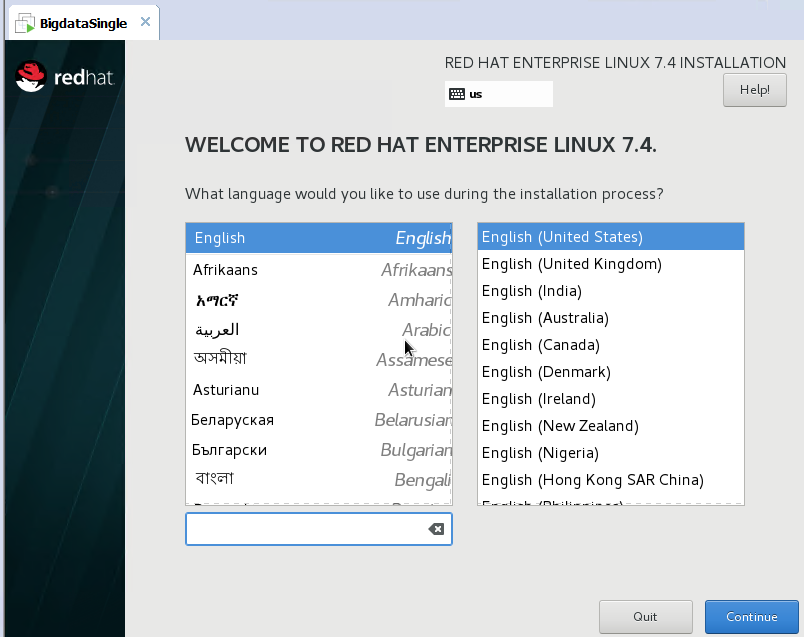
选择语言English
设置时区(Asia/Shanghai)
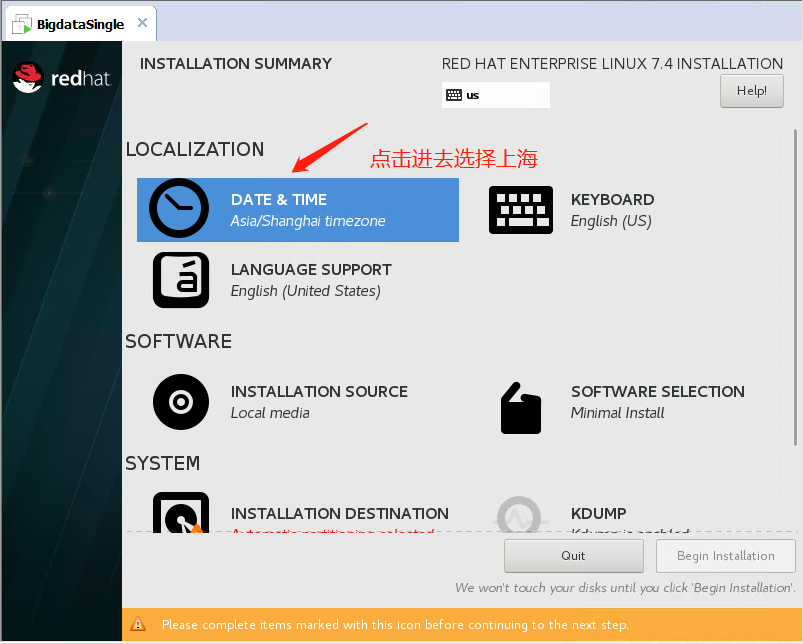
Software Install 选择:Server with GUI+Development Tools
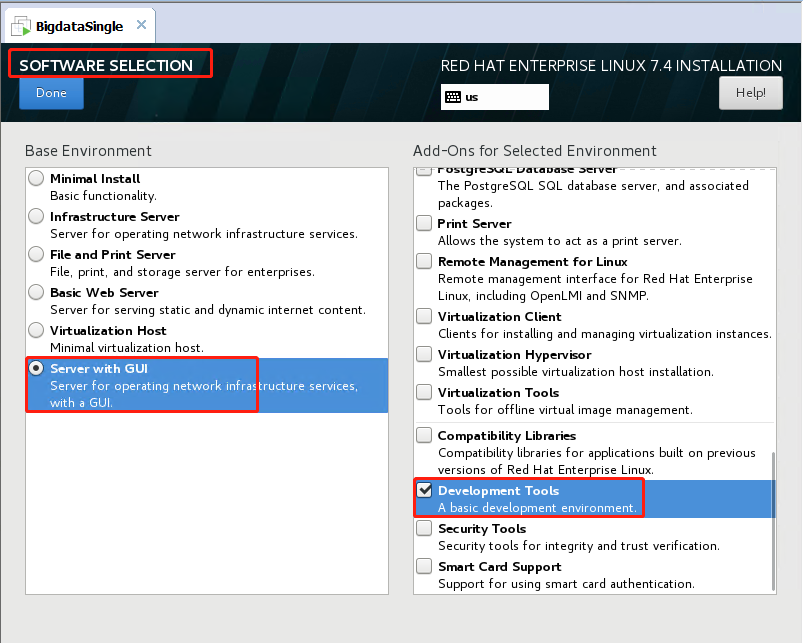
System配置按照下图即可
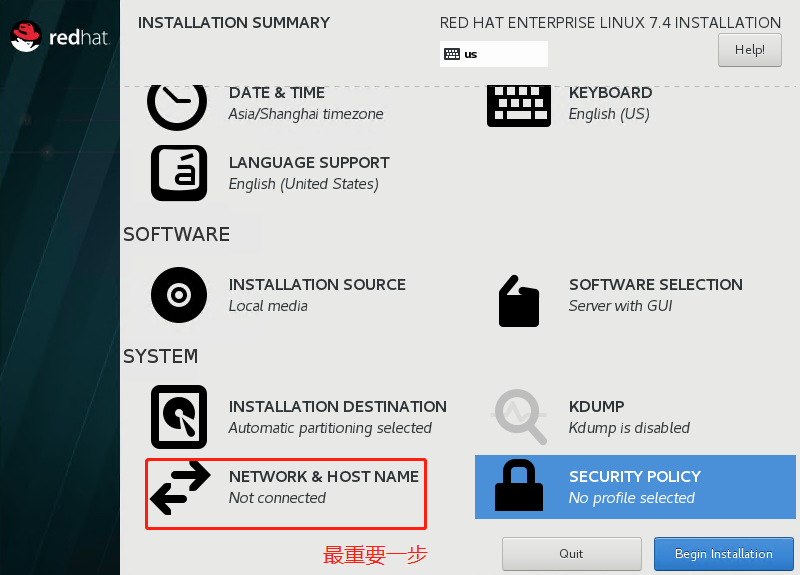
配置网络和主机名【最重要一步】
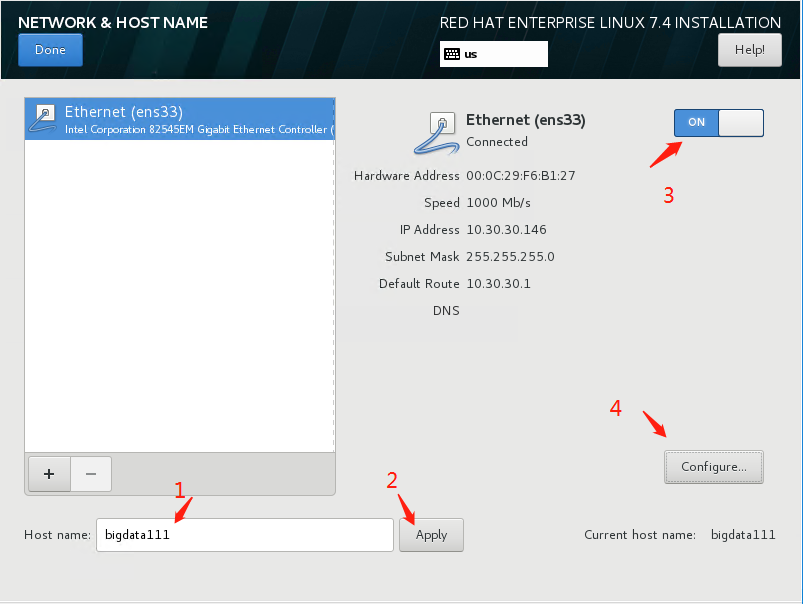
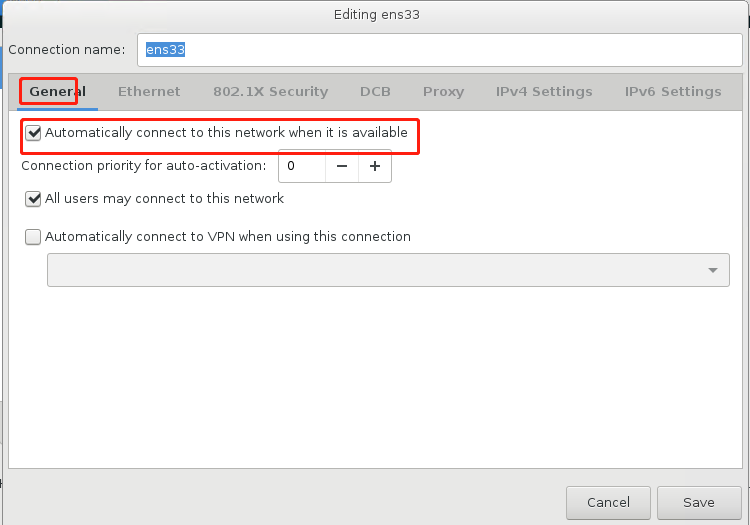
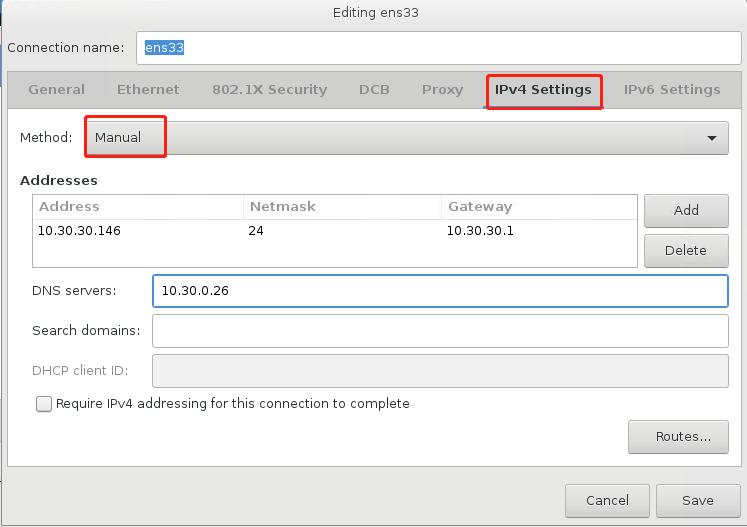
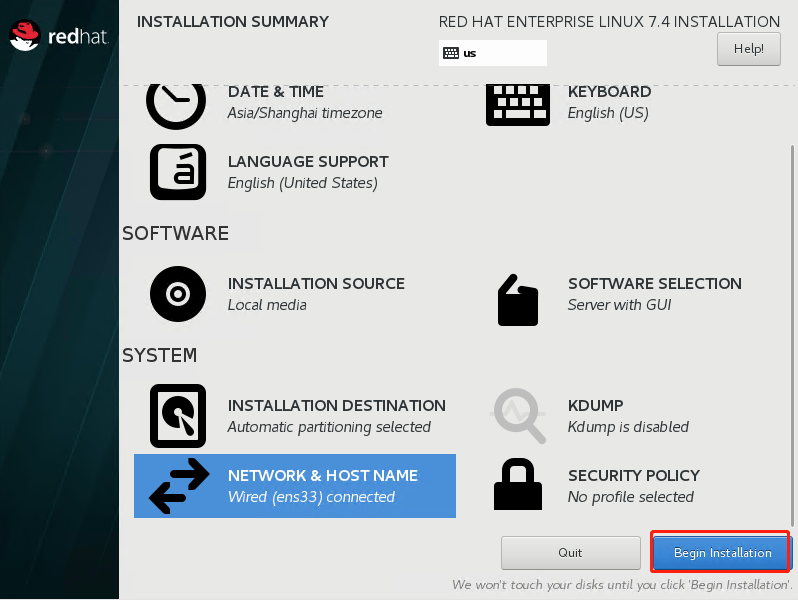
开始安装
设置root密码
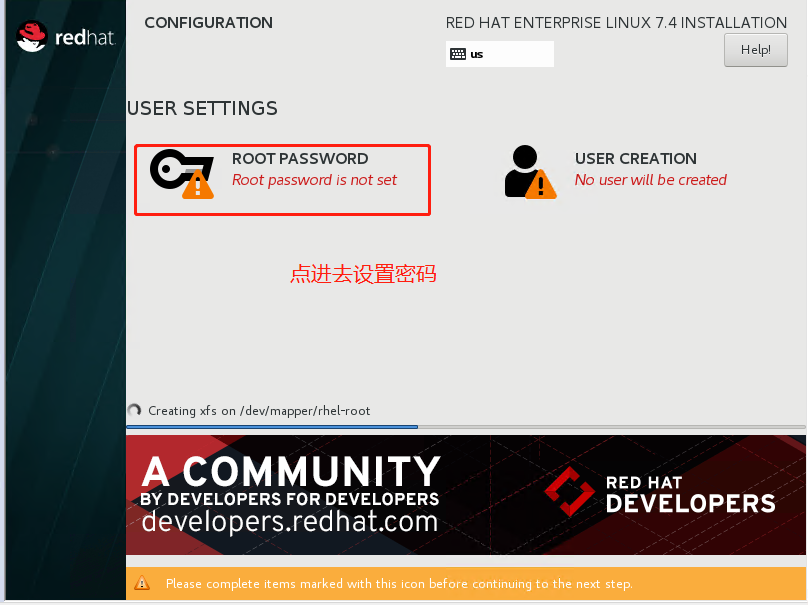
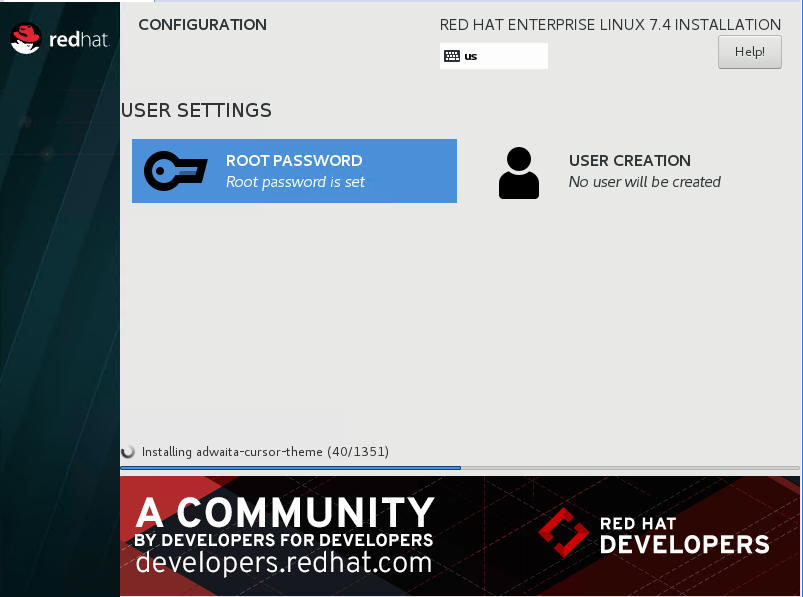
等待安装完成,重启虚拟机
重启后开始安装向导配置
接受license
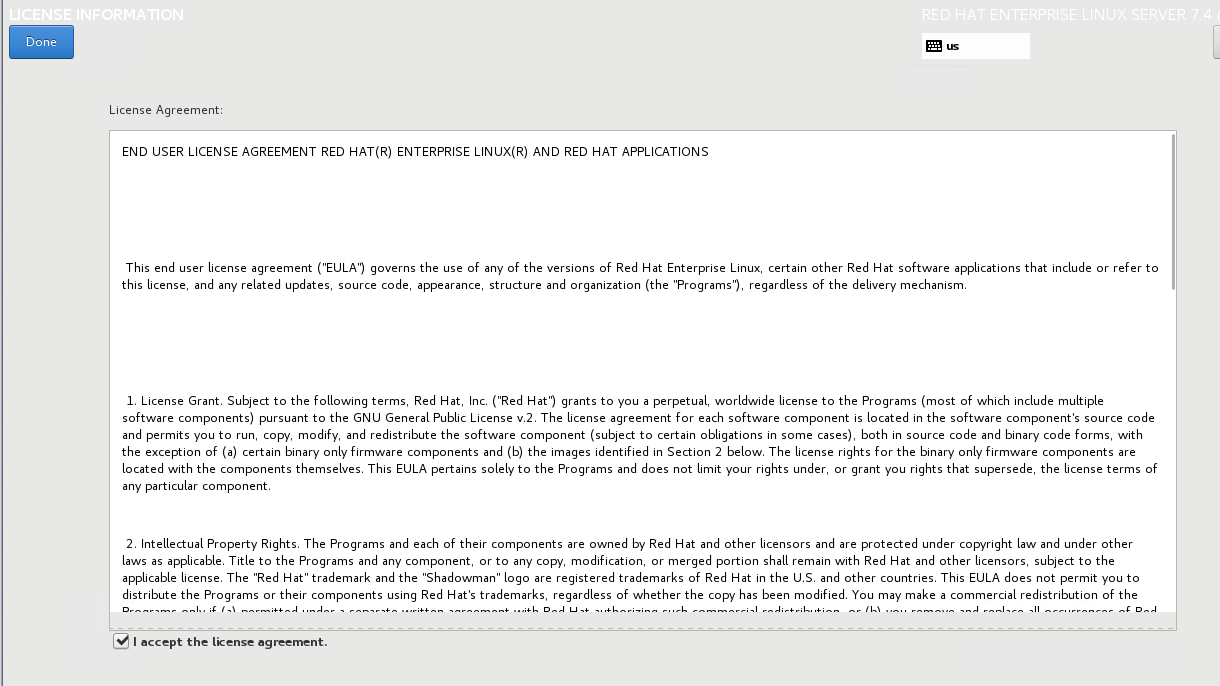
语言选择:English
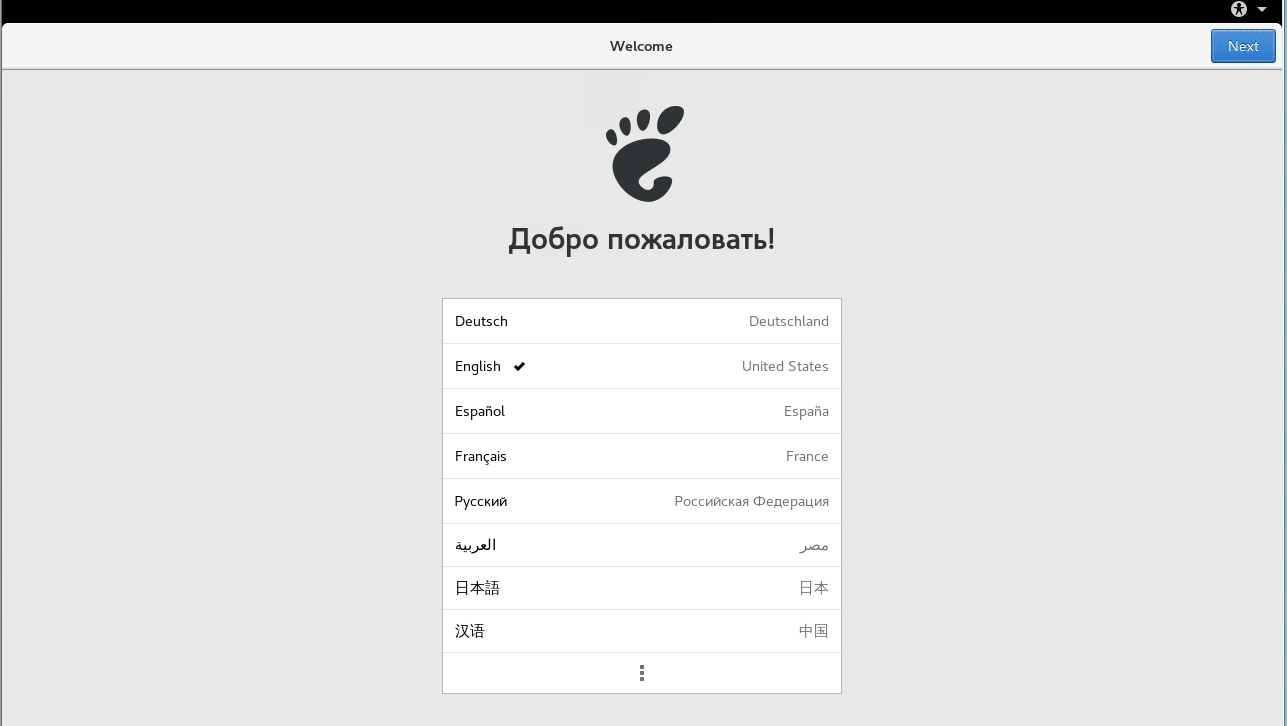
键盘:English
隐私设置:关闭
时区
在线账户,跳过
新建一个用户,注意这里不是root用户,用户名是roo
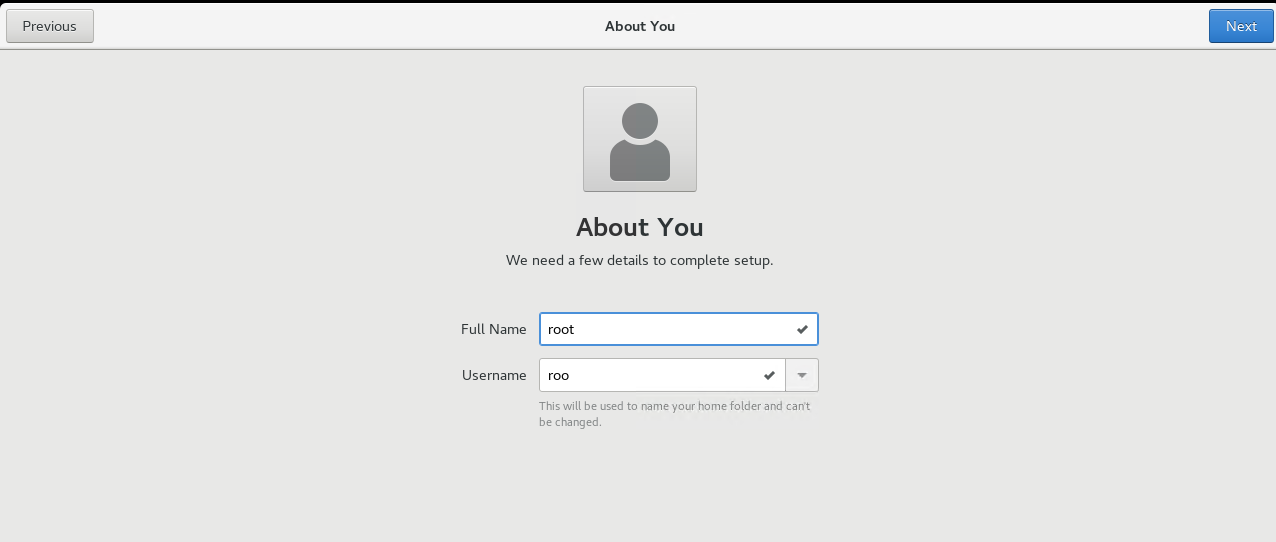
设置密码
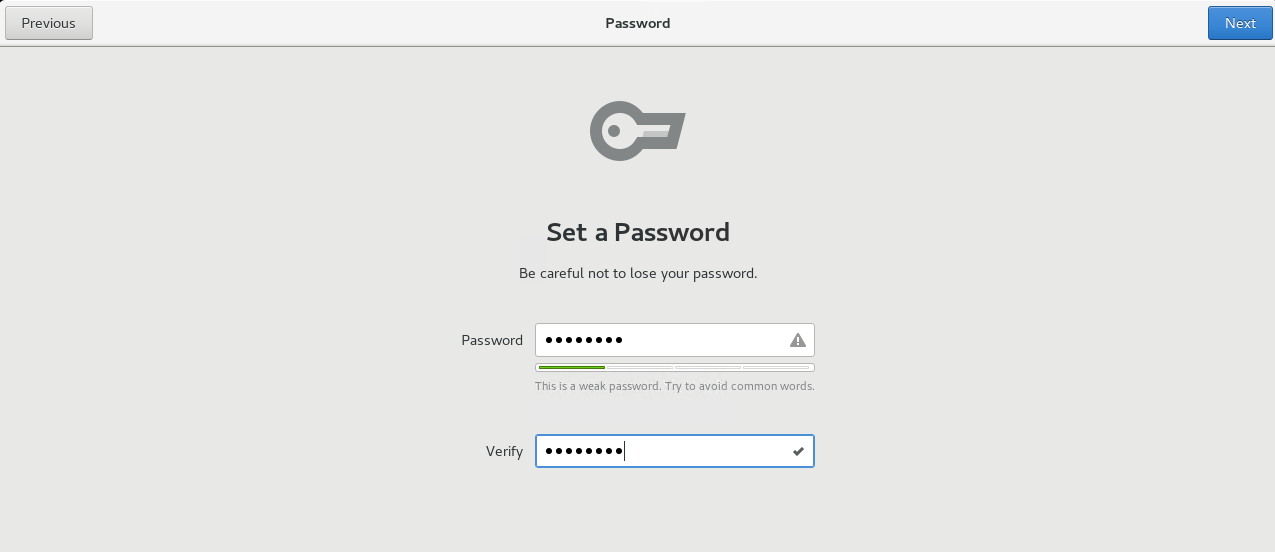
注意:这时登录的用户并不是root用户,登录进去后,选择logout,重新登录root用户并按照上面的安装向导重新配置一遍即可。(Linux系统的基础操作,不再截图演示)。这时我们就可以登录root用户了。
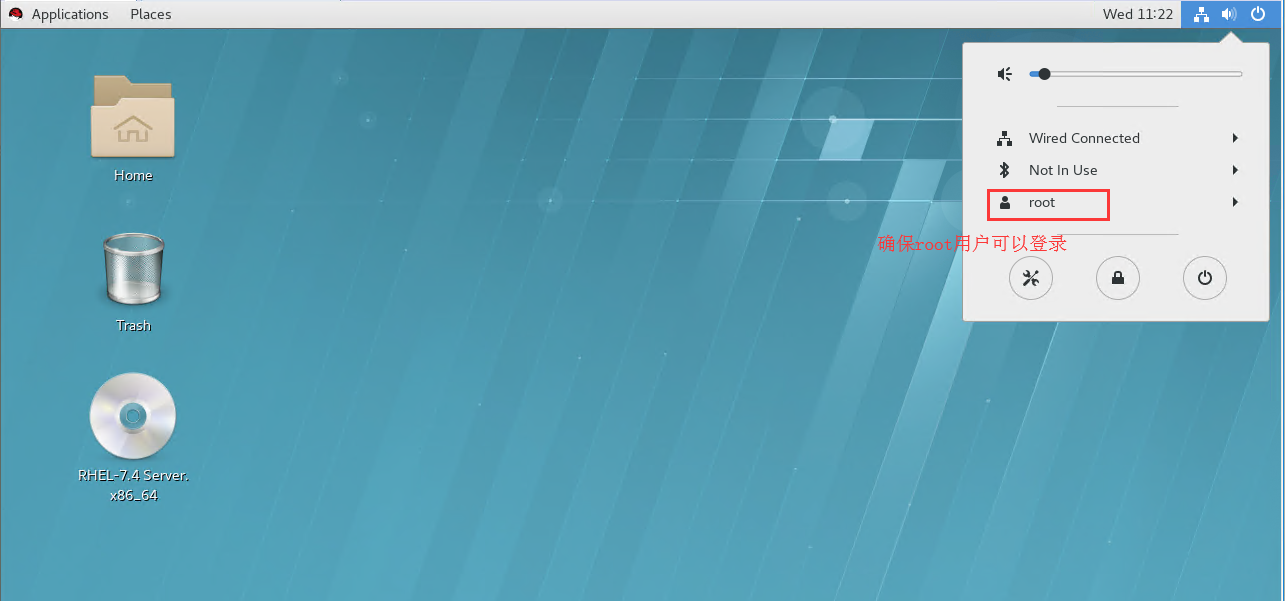
其他4台虚拟机参考上图操作,完整安装即可!不可以不安装,否则讲分布式配置的时候无法完成。配置完成参考下图。
>配置完成效果图

















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









