






 本文详细解析了变量创建、初始化及赋值的过程,并通过实例对比了不同方式下变量的行为表现,包括内置类型变量的初始化特点及成员变量的初始化与赋值区别。
本文详细解析了变量创建、初始化及赋值的过程,并通过实例对比了不同方式下变量的行为表现,包括内置类型变量的初始化特点及成员变量的初始化与赋值区别。
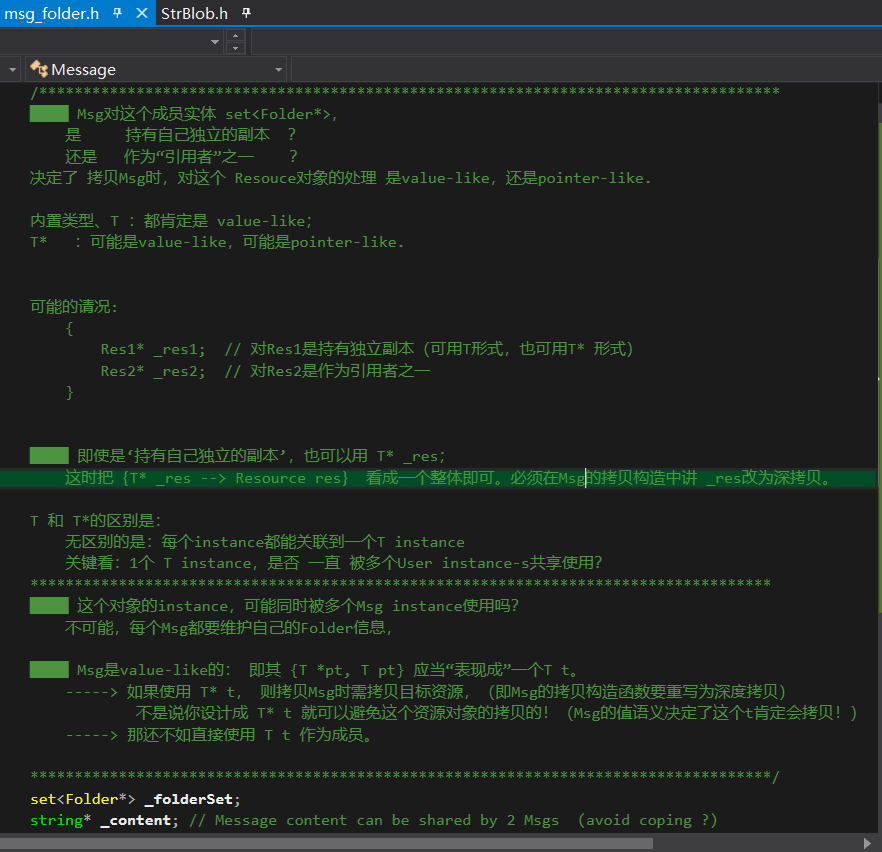
★ (一个成员)变量的 创建、初始化、赋值
“默认值”:内置类型的局部变量、内置类型的成员变量(未设置=initval;) 没有默认值! 若创建时不指定值,则不进行初始化、则其值未定义!!!
“指定值”:显式传给你值。 调用类的有参构造函数。
★ 等号即为赋值。
int i = 0; // 创建i —— > (内置类型无默认值、同时未指定值? 则不进行初始化, 值为未定义) ——> 赋值
Man man("wjh", 21); // 创建man ——> 指定值-初始化
Man man = m1; // 创建man ——> (使用默认构造,成员变量采用类中定义的无默认值/有默认构造 初始化方案、)
“指定值-初始化” 实际的语义行为: 对该成员T instance采取 “copy constructor”。 所以采用member1(member2)的形式啊!
“默认值-初始化” + “赋值” : 对该成员T instance采取 “default constructor” + "copy assignment"
写段代码、打log验证一下!

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









