dom4j的DOM结构解析
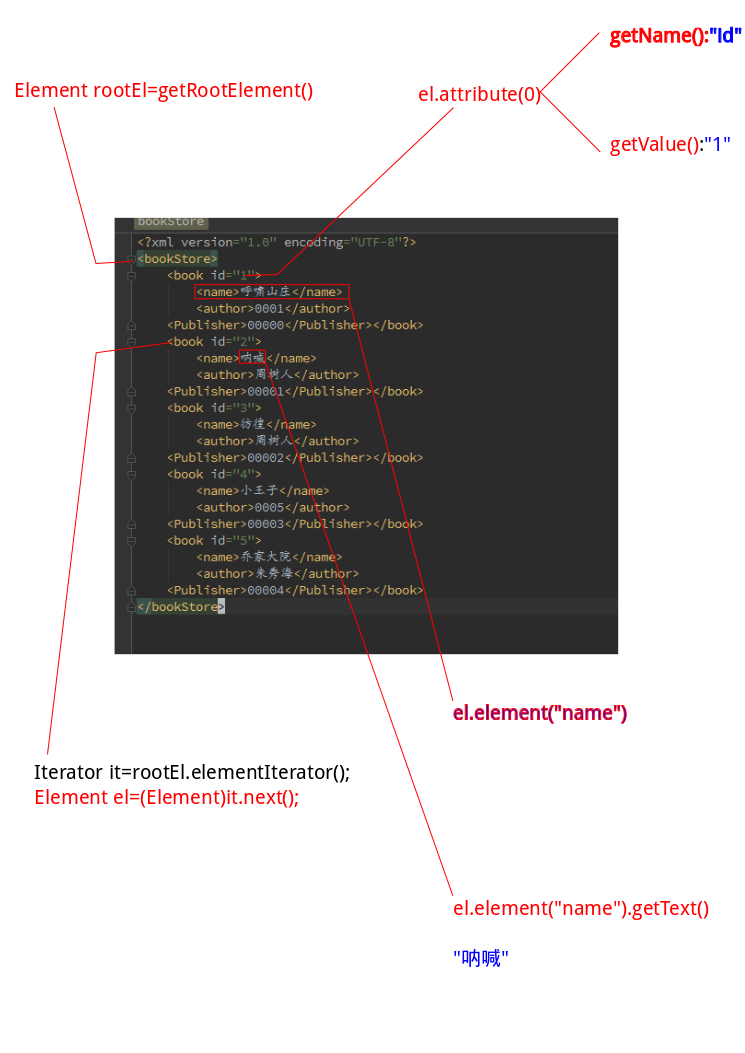
读取下列xml中所有的书名
<?xml version="1.0" encoding="utf-8" ?>
<bookStore>
<book id="1">
<name>呼啸山庄</name>
<author>0001</author>
</book>
<book id="2">
<name>呐喊</name>
<author>周树人</author>
</book>
<book id="3">
<name>彷徨</name>
<author>周树人</author>
</book>
<book id="4">
<name>小王子</name>
<author>0005</author>
</book>
<book id="5">
<name>乔家大院</name>
<author>朱秀海</author>
</book>
</bookStore>
import org.dom4j.Element;
import org.dom4j.io.ElementModifier;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.Iterator;
import org.dom4j.Document;
/**
* Created by root on 16-3-21.
*/
public class dom4j {
public static void main(String[] args) throws Exception{
method_1();
}
private static void method_1() throws Exception{//抛出异常 减少try--catch的使用
SAXReader reader=new SAXReader(); //建立SAXReader对象
Document document=reader.read(new File("hello.xml")); //建立document对象
Element rootElement =document.getRootElement(); //根element对象
Iterator it= rootElement.elementIterator(); //从rootelement获得枚举器
while (it.hasNext()){
Element el=(Element) it.next();//枚举方法
System.out.println( el.element("name").getText()); //获得<book></book>中的<name></name>标签内的内容 并打印
}
// System.out.println("book name---> "+bookName);
}
}







 本文介绍如何利用dom4j库解析XML文件,提取特定元素中的书名信息。
本文介绍如何利用dom4j库解析XML文件,提取特定元素中的书名信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









