



 本文详细介绍了Linux IA32系统中异常处理机制,包括故障(Faults)与终止(Aborts)的区别,以及常见异常类型如除错异常、一般保护故障、页错误等的处理方式。此外还解释了系统调用如何通过特定指令触发内核处理。
本文详细介绍了Linux IA32系统中异常处理机制,包括故障(Faults)与终止(Aborts)的区别,以及常见异常类型如除错异常、一般保护故障、页错误等的处理方式。此外还解释了系统调用如何通过特定指令触发内核处理。
Faults
Faults result from error conditions that a handler might be able to correct. When a fault occurs, the processor transfers control to the fault handler. If the handler is able to correct the error condition, it returns control to the faulting instruction, thereby reexecuting it. Otherwise, the handler returns to an abort routine in the kernel that terminates the application program that caused the fault.
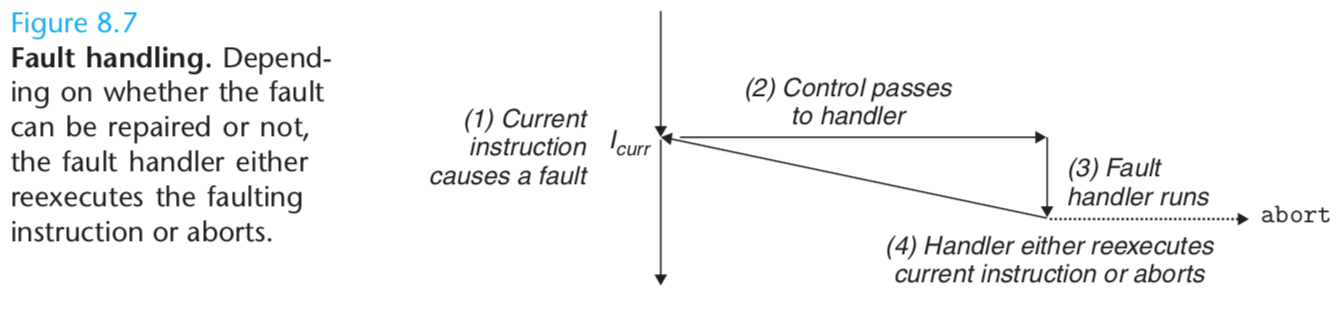
A classic example of a fault is the page fault exception, which occurs when an instruction references a virtual address whose corresponding physical page is not resident in memory and must therefore be retrieved from disk. The page fault handler loads the appropriate page from disk and then returns control to the instruction that caused the fault. When the instruction executes again, the appropriate physical page is resident in memory and the instruction is able to run to completion without faulting.
Aborts
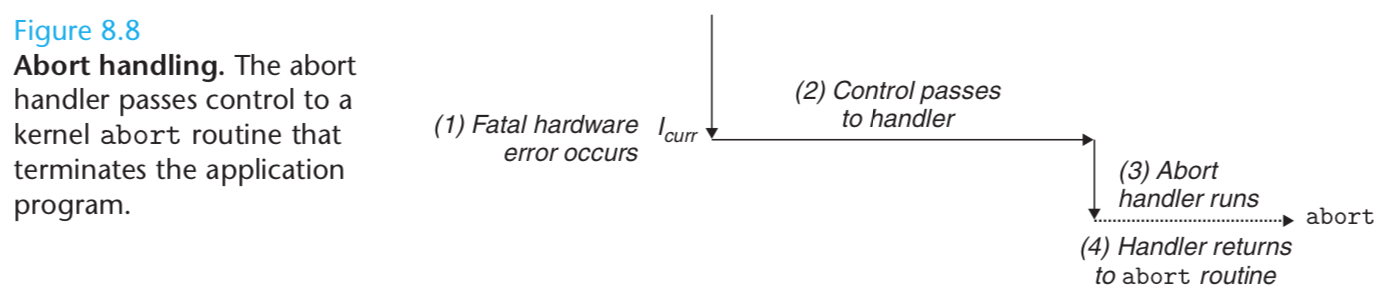
Aborts result from unrecoverable fatal errors, typically hardware errors such as parity errors that occur when DRAM or SRAM bits are corrupted.
Abort handlers never return control to the application program. As shown in Figure 8.8, the handler returns control to an abort routine that terminates the application program.
Exceptions in Linux/IA32 Systems
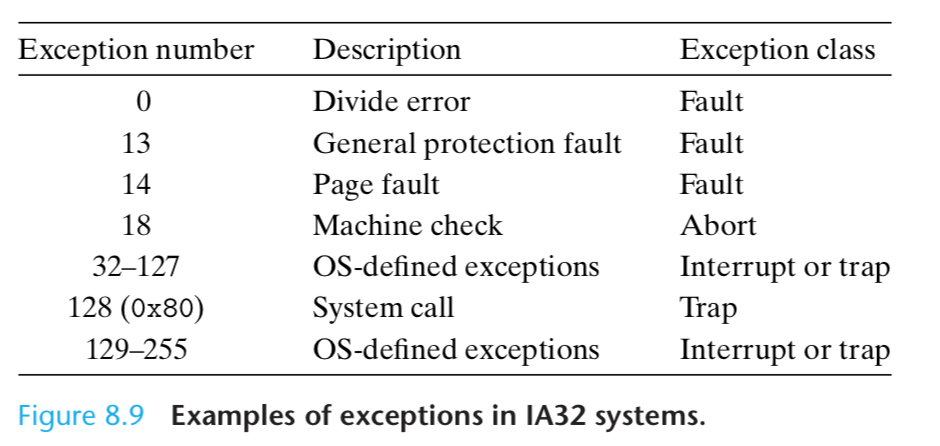
There are up to 256 different exception types [27].
Numbers in the range from 0 to 31 correspond to exceptions that are defined by the Intel architects, and thus are identical for any IA32 system.
Numbers in the range from 32 to 255 correspond to interrupts and traps that are defined by the operating system.
Explanations of Linux/IA32 Faults and Aborts
Divide error. A divide error (exception 0) occurs when an application attempts to divide by zero, or when the result of a divide instruction is too big for the destina- tion operand.
Unix does not attempt to recover from divide errors, opting instead to abort the program.
Linux shells typically report divide errors as “Floating ex- ceptions.”
General protection fault. The infamous general protection fault (exception 13) occurs for many reasons, usually because a program references an undefined area of virtual memory,
or because the program attempts to write to a read-only text segment.
Linux does not attempt to recover from this fault. Linux shells typically report general protection faults as “Segmentation faults.”
Page fault. A page fault (exception 14) is an example of an exception where the faulting instruction is restarted.
The handler maps the appropriate page of physical memory on disk into a page of virtual memory, and then restarts the faulting instruction.
Machine check. A machine check (exception 18) occurs as a result of a fatal hardware error that is detected during the execution of the faulting instruction.
Machine check handlers never return control to the application program.
Examples of Linux/IA32 System Calls
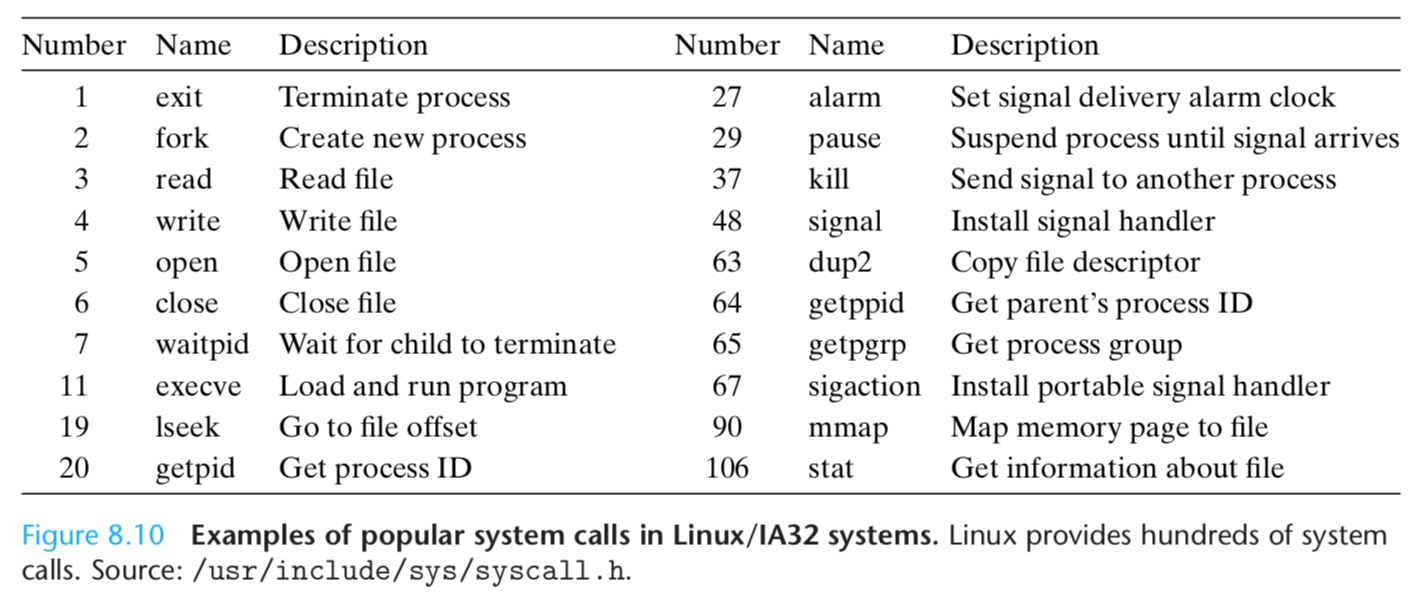
Each system call has a unique integer number that corresponds to an offset in a jump table in the kernel.
System calls are provided on IA32 systems via a trapping instruction called int n, where n can be the index of any of the 256 entries in the IA32 exception table.
Historically, system calls are provided through exception 128 (0x80).
C programs can invoke any system call directly by using the syscall function.
However, this is rarely necessary in practice. The standard C library provides a set of convenient wrapper functions for most system calls.
The wrapper functions package up the arguments, trap to the kernel with the appropriate system call number, and then pass the return status of the system call back to the calling program.
Throughout this text, we will refer to system calls and their associated wrapper functions interchangeably as system-level functions.
All parameters to Linux system calls are passed through general purpose registers rather than the stack.
By convention, register %eax contains the syscall number, and registers %ebx, %ecx, %edx, %esi, %edi, and %ebp contain up to six arbitrary arguments.
The stack pointer %esp cannot be used because it is overwritten by the kernel when it enters kernel mode.
examples of a C program and its conresponding assambly codes:



















 2580
2580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









