



 本文介绍了一个使用Python实现的简易MapReduce框架。通过定义Mapper和Reducer类,实现了对输入文件的数据处理过程,包括映射、组合及规约步骤,并展示了如何运行整个流程。
本文介绍了一个使用Python实现的简易MapReduce框架。通过定义Mapper和Reducer类,实现了对输入文件的数据处理过程,包括映射、组合及规约步骤,并展示了如何运行整个流程。
此书不错,很短,且想打通PYTHON和大数据架构的关系。
先看一次,计划把这个文档作个翻译。
先来一个模拟MAPREDUCE的东东。。。

mapper.py
class Mapper: def map(self, data): returnval = [] counts = {} for line in data: words = line.split() for w in words: counts[w] = counts.get(w, 0) + 1 for w, c in counts.iteritems(): returnval.append((w, c)) print "Mapper result:" print returnval return returnval
reducer.py
class Reducer: def reduce(self, d): returnval = [] for k, v in d.iteritems(): returnval.append("%s\t%s"%(k, sum(v))) print "Reducer result:" print returnval return returnval
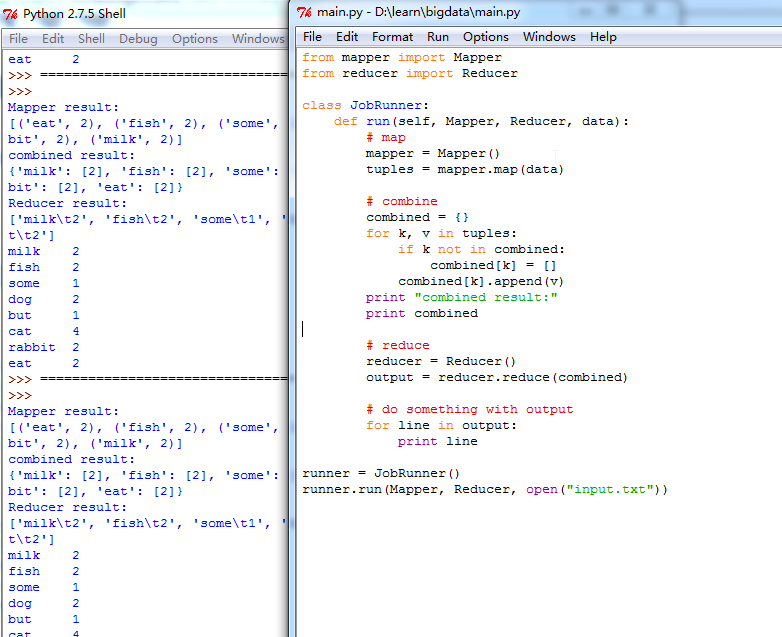
main.py
from mapper import Mapper from reducer import Reducer class JobRunner: def run(self, Mapper, Reducer, data): # map mapper = Mapper() tuples = mapper.map(data) # combine combined = {} for k, v in tuples: if k not in combined: combined[k] = [] combined[k].append(v) print "combined result:" print combined # reduce reducer = Reducer() output = reducer.reduce(combined) # do something with output for line in output: print line runner = JobRunner() runner.run(Mapper, Reducer, open("input.txt"))

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









