



 本文深入探讨了Sharepoint的内容层次结构,从高、中、低三个层次详细介绍了Sharepoint对象模型,包括Web应用程序、内容数据库、网站集、网站、列表、列表项等核心组件,以及如何在代码中管理和操作这些对象。
本文深入探讨了Sharepoint的内容层次结构,从高、中、低三个层次详细介绍了Sharepoint对象模型,包括Web应用程序、内容数据库、网站集、网站、列表、列表项等核心组件,以及如何在代码中管理和操作这些对象。
Sharepoint的内容层次结构(Content Hierarchy)包括表示可发布数据项(publishable items),如列表项的类,还包括表示嵌套的数据容器(nested containers of data),如列表、内容数据库、网站、网站集以及称为"Web 应用程序"的网站集分组)的类。
内容层次结构中的主要对象如下图:
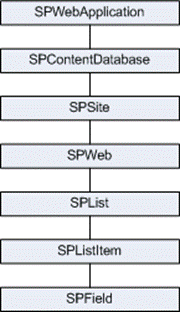
这里我们把Sharepoint的内容层次结构进一步细分成三个层次分别描述:
一、高层次的对象模型(High Level Object Model)
在Sharepoint场中最高级别的内容容器(Content Container)就是Web应用程序(Web Application),它是由SPWebApplication类来表示的。
SPWebApplication对象在SharePoint Foundation 中表示用于发布内容的 Web 应用程序。该对象包含一个或多个内容数据库(Content Database)以用于存储一个或多个网站集数据。每个此类 Web 应用程序都由 IIS 网站提供服务并且在 IIS 中通常具有自己的应用程序池。 而且每个Web应用程序都有它们自己的安全(security)和身份认证(authentication)的相关设置。
一个由SPWebApplication类表示的 SharePoint Foundation Web 应用程序,它基本上就是一组内容数据库,其中每个内容数据库均包含网站集;而网站集自身是网站的集合,这些网站又是文件的集合。
但SharePoint Foundation Web 应用程序并不仅仅是最高级别的网站分组,它还是 SharePoint Foundation 部署在其上对 IIS 可见的层。每个 SharePoint Foundation Web 应用程序均通过一个 IIS 网站公开,并在 IIS 管理器的网站树中出现。 下图就是在一个SharePoint Foundation 前端 Web 服务器上显示应用程序池和 IIS 网站的 IIS 管理器:
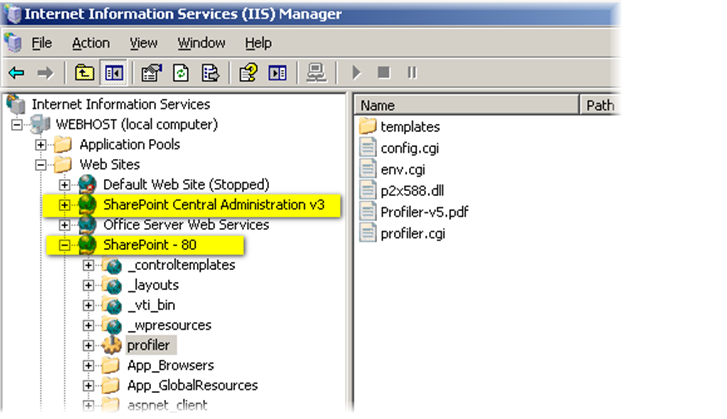
上图显示的是在单一服务器上刚安装 SharePoint Foundation 之后的 IIS 管理器。请注意,此安装创建了两个 IIS 网站,每个网站均具有它自己的应用程序池(和进程)。
其中一个 IIS 网站针对的是用于向最终用户提供内容的主要 SharePoint Foundation Web 应用程序,此网站名为"SharePoint - 80"("80"为服务器端口号,将通过此端口号传入 SharePoint Foundation 页面的请求);
另一个 IIS 网站名为"SharePoint Central Administration v3",可供 IT 专业人士用来执行高级管理任务。您也许能够猜到为什么要创建单独的 SharePoint Foundation Web 应用程序,而不是在"SharePoint - 80"内创建一个网站集或网站。通过将两个 SharePoint Foundation Web 应用程序的进程隔离,即使"SharePoint - 80"内的某个网站上的错误代码导致后面的 Web 应用程序在每次重启后立即崩溃,网络管理员仍然可以访问管理中心。此外,通过使管理应用程序成为一个单独的 Web 应用程序,管理员能够为其指定与身份验证和匿名用户相关的不同策略。
如果在具有多台服务器的场中安装 SharePoint Foundation,并且前端服务器和后端服务器(在 SharePoint Foundation 中称作"应用程序服务器")的配置不同,则"SharePoint – 80"仅在前端服务器上运行。"SharePoint Central Administration v3"在一台应用程序服务器上(且仅在一台应用程序服务器上)运行。
"SharePoint Central Administration v3"应用程序之外的 SharePoint Foundation Web 应用程序称作"内容发布 Web 应用程序"。
当创建初始"SharePoint - 80"Web 应用程序时以及创建任何内容发布 Web 应用程序时,都将为相应的 Web 应用程序创建新的内容数据库。然后依次为新建的数据库创建一个网站集,并为新建的网站集创建一个首要网站。
因此,SharePoint Foundation Web 应用程序中的所有网站集和网站(以及子网站)对于 IIS 来说只是一个大的网站而已。
在创建 IIS 网站后,IIS 将自动为每个 IIS 网站提供它自己的应用程序池,并且每个应用程序池具有自己的进程。这样,每个 SharePoint Foundation Web 应用程序将在自己的进程中运行。如果其中的某一个进程发生崩溃,则其他进程将继续运行。这是 SharePoint Foundation Web 应用程序与对象模型层次结构中的较低层之间最重要的区别。
内容数据库(ContentDatabase)和网站集(Site Collection)彼此之间没有进程隔离机制,但 Web 应用程序具有这种机制。
严格来说,无需保持 IIS 网站与应用程序池之间的一对一关系。在 IIS 管理器中,可将网站从一个应用程序池移动到另一个应用程序池。因此,可以将多个 SharePoint Foundation Web 应用程序移动到同一个池中,从而共享同一进程。在某些情况下,为了获得这种进程共享带来的性能增强,有必要放弃崩溃保护。尽管如此,人们并不会经常使用进程共享。
SPWebApplication类的一些特征:
•SPWebApplication 对象是 SPWebService 对象的子对象。
•SPWebApplication 类具有一个保存其所有子级 SPContentDatabase 对象的 ContentDatabases 属性。(该类还具有一个方便使用的 Sites 属性,利用该属性可以获取对其所有内容数据库的全部网站集的引用,而不必首先获取对一个或多个内容数据库的引用。)
•与管理中心应用程序类似,SPWebApplication 类使管理员能够不用打开 IIS 管理器即可访问 IIS 属性。例如,IisSettings 属性和 ApplicationPool 属性提供对 SharePoint Foundation Web 应用程序分配到的 IIS 应用程序池的属性的编程访问。
•SPWebApplication 继承自 SPPersistedObject,这意味着该类的对象将保存在配置数据库(Configuration Database)中。
•SPWebApplication 具有很多可用于开发管理功能的成员。一些较重要的成员可帮助管理诸如: 安全策略,通知,文档转换,备份和还原 Web 应用程序,记录 Web 应用程序的更改,出站电子邮件,外部工作流参与,使用 Windows Live MetaWeblog API,使用回收站,未使用的网站集,Web.config 文件修改 等等内容:
•当 Web 应用程序需要使用某服务应用程序(Service Application)提供的数据或处理功能时,它会通过 SPServiceApplicationProxy 来完成。
•SPWebApplication 类与 SPHttpApplication 类具有密切的关系。后一个类的对象是 HTTP 请求处理程序。SharePoint Foundation Web 应用程序分配到的进程(IIS 应用程序池)具有一个或多个处理定向到 Web 应用程序的页面请求的 SPHttpApplication 对象
前面说了,每个 SharePoint Foundation Web 应用程序至少拥有一个内容数据库(由SPContentDatabase类表示),此内容数据库是在创建 Web 应用程序时自动创建的。可以根据需要向 Web 应用程序中添加更多内容数据库。内容数据库包含所有数据(列表、列表项、博客文章和评论、Wiki 网页和文档库中的文档)和大多数页面文件,它们构成了属于数据库的网站集。
某些属于网站集的文件将存储在 SharePoint Foundation 部署的前端服务器的文件系统中。乍一看,这似乎可能会损坏网站集作为内容数据库的子集的系统性。不过,即使文件未存储在内容数据库中,它们也由该数据库中的行表示。表示此类文件的表行将用作该文件的一种别名。
SPContentDatabase类的某些特征:
•SPContentDatabase 对象是 SPWebApplication 对象的子对象。Web 应用程序的 ContentDatabases 属性中将引用 Web 应用程序的内容数据库的集合。
•SPContentDatabase 类具有一个保存其所有子级 SPSite 对象的 Sites 属性。
•SPContentDatabase 继承自 SPPersistedObject,这意味着实例化类的对象将保存在配置数据库中。
•SPContentDatabase 具有很多可用于开发管理功能的成员。一些较重要的成员可帮助管理诸如备份和还原数据库、升级数据库、迁移(移动)数据库、修复数据库、数据库连接字符串以及登录用户名和密码、限制网站集的数量等内容
•SPContentDatabase 的大部分属性是只读的。
•SPWebApplication 与SPContentDatabase类都继承自SPPersistedObject,也就是说,它们的实例化的对象将保存在配置数据库中。
二、中间层次的对象模型(Middle Level Object Model)
处于中间层次的对象模型是网站集(SiteCollection)和它的子集。其中SPWeb对象代表一个单独的网站对象,而SPSite对象则代表处于同一个WebApplication中的多个网站对象组成的集合,这样打包的目的是出于管理的需要。
SPSite类
SPSite类表示网站的集合,但它并不是一个实现了 ICollection 接口的类,因此SPSite 类其实并不是一个集合。(SPSiteCollection 类实现后一个接口。它才真正表示 SPSite 对象的集合。)
以下是 SPSite 类的一些特征:
•SPSite 对象表示 SPContentDatabase 对象的内容的子集。
•SPSite 类具有一个保存其子级首要网站的 RootWeb 属性。(在第一个版本的 SharePoint Foundation 中,即在 Microsoft SharePoint Team Services 中,首要网站【Top –level webstie】称作"根网站"。)而表示首要网站的 SPWeb 对象则具有一个保存其所有"直接"子网站[immediate child subsites](但不是这些直接子网站所包括的更下一级的子网站)的 Webs 属性。(AllWebs 属性将返回所有 子网站和首要网站。)
•SPSite 具有很多可用于开发管理功能的成员。一些较重要的成员可帮助管理诸如: 网站 URL 的最大长度、RSS 源、审核、不活动网站、功能、网站集的所有权、网站集的大小配额、网站使用率数据、网站集中的工作流、模板和 Web 部件库、自助式网站创建等内容
•SPSite 类中大约一半的方法都是用来返回某类信息的 Get* 方法,这些方法的大多数属性都是只读的。
网站集(由 SPSite 类表示)的存在可为网站所有者、服务器管理员和销售 SharePoint Foundation 宿主服务的企业提供管理上的便利。
以下是网站集的一些最重要的特征:
•与 SharePoint Foundation Web 应用程序相比,SharePoint Foundation 网站集能够为 SharePoint Foundation 部署提供更细化的管理,但特定网站自身的管理仍由网站所有者(他们通常不是 IT 专业人士)负责。
•每个网站集有且仅有一个首要网站。对于某些类型的管理任务,最好是将网站集及其首要网站视为单个实体。例如,首要网站的"网站设置"页面中包含一个"网站集管理"区域,首要网站的所有者可在此区域中激活网站集的功能,并从回收站中还原任何已删除的网站集内容。另外,可以在首要网站中创建某些自定义实体(如自定义列)。之后,网站集中的所有网站都可以使用这些实体。
•网站集横跨网站所有者的管理责任与网站集管理员(通常不是 IT 专业人士)的管理责任之间的边界。如上一条中所述,一些网站集级别的管理任务将由首要网站的所有者处理。但服务器管理员和网络管理员可以使用管理中心的"应用程序管理"选项卡来创建和删除网站集以及设置网站集的大小配额。
•网站集(或严格来说是网站集的首要网站)是痕迹导航中最高级别的对象。(尽管子网站的用户不一定能够访问层次结构中较高级别的每个网站,但他们可以在痕迹导航中看到这些网站。)
•由网站集范围和网站范围的功能(feature)、内容类型(content type)、列表(list)、主题(theme)和工作流(workflow)组成的池在网站集级别进行维护并提供给子网站使用。也就是说Sharepoint中的master pages, Web Parts, themes, lists, content types, 以及 Features的作用范围都可以达到Site Collection级别。也就是说可以把它们部署到Site Collection级别并对此Site Collection下的所有子级起作用。
•网站集是可从中激活 SharePoint Foundation 功能的四个级别之一。其他三个级别为网站、Web 应用程序和场。
•用户组是在网站集级别进行维护并分配默认权限的。(可以在任何网站、列表或列表项级别更改这些权限。可以在任何网站的"网站设置"页面上创建组。但不管在何处创建组,该组都将处于网站集级别并且对网站集中的所有网站可用。)也即一个Site Collection是Sharepoint用于创建用户组(create groups of users)以及分配默认权限(default permission)的级别
•可以在网站集内而不是网站集之间共享母版页和 Web 部件。
•网站集是层次结构中最高级别的对象,可以审核对它的访问权。将在此级别维护审核数据库。
•一个网站集(Site Collection)是具有实用的备份和还原 API 的最小单元。(但可以使用未连接的数据库和数据库快照功能来备份和还原列表和其他更细化的单元。
•在SharePoint Foundation中Site Collection是搜索(search)功能所能作用的最大范围,如果你的搜索功能想要突破这个范围限制,就必须要使用SharePoint Server 2010。
•一个网站集(site collection)的内容(content)总是被存储在一个内容数据库(a single content database)中的。
•每个网站集都有一名网站集管理员
SPWeb类
SPWeb 类表示一个 SharePoint Foundation 网站。网站是一个包含一个或多个网页的集合,它通常包含一组列表、文档库、内容类型、字段(列)类型、一组可用功能、一组用户警告以及一组工作流实例。此外,网站还具有一个所有者和一组关联的用户和用户组。可以通过编程方式在网站中添加或删除所有这些类型的实体。网站也可以作为搜索范围。
以下是 SPWeb 类的某些特征:
•SPWeb 对象可以是另一个 SPWeb 对象或 SPSite 对象的子对象。如果它是 SPSite 对象的子对象,则将是网站集中的首要网站(Top-level Website)。
•SPWeb 对象具有一个可返回其他 SPWeb 对象的集合(具体是指它下面的直接子网站)的 Webs 属性。
•该类提供了一组非常丰富的成员,可用于编程管理和网站自定义。
•网站的层次结构始终必须具有一个首要网站。此网站是 SPSite 对象的子对象。
一个SPWeb类有许许多多的属性和方法用于处理网站(Website)的相关内容,包括它们的用户、列表、字段,内容类型,功能,报警等方方面面。SPWeb类也包含一个关键的Update()方法,该方法用于将更改提交到 SharePoint Foundation 数据库。
Sharepoint的网站 与ASP.NET传统网站的比较:
一个由 SPWeb 类表示的 SharePoint Foundation 网站,它是经过优化以便进行内容管理和协作的 ASP.NET 网站。该网站主要在以下几个方面与其他 ASP.NET 应用程序不同:
•该网站不再强调页面,而是改为强调列表(List)和列表项(List Item)。例如,SharePoint Foundation 网站(类型为 STS)的"快速启动"会显示一个网站、子网站和列表(包括列表的列表)的层次结构,而不是页面本身构成的层次结构。如果向此网站添加页面,则新的页面在"快速启动"中将作为共享文档列表中的新项出现,而不是作为主页或某些其他页面下的子节点出现。
•该网站赋予用户管理能力。任何给定用户所具有的能力大小由授予该用户的权限决定。通常,最终用户能够创建全新的网站(作为现有网站的子网站),并能够在现有网站上添加和编辑内容。
•该网站是可以在其上激活 SharePoint Foundation 功能(Feature)的四个级别之一。其他三个级别为网站集(Site Collection)、Web 应用程序(Web Application)和场(Farm)。
•网站是网站集内容的子集这一事实并不表示给定集合中两个网站的内容会相互排斥:例如,一个给定列表可以在多个网站上出现。
关于SPSite与SPWeb两个对象的创建与销毁:
由于Sharepoint的最早期版本在.NET Framework出现之前就存在了,而现在Sharepoint中的SPWeb与SPSite则是源自早期的版本并由此发展而来的,所以,甚至到了现在SPWeb与SPSite仍包装了一些COM对象,这些COM对象是无法让.NET Framework的垃圾回收(Garbage collection)机制自动回收的,如果你在使用它们之后没有正确的销毁它们,就很容易引起Sharepoint场服务器的内存泄漏。所以Sharepoint开发人员有必要调用SPWeb或SPSite的Dispose方法来及时释放它们。值得注意的是,SPContext 对象由 SharePoint 框架进行管理并且不应该在代码中明确释放。SPContext.Site、SPContext.Current.Site、SPContext.Web 和 SPContext.Current.Web 返回的 SPSite 和 SPWeb 对象也是如此。每当在同一行上合并 SharePoint 对象模型调用时,必须慎重并知道运行库所做的操作。这种情况引发的泄露最难找到。
三、低层次的对象模型(Low Level Object Model)
这个层次的对象模型包括列表(List)和列表项(List items),它们分别由SPList 和 SPListItem 这两个类来表示。
SPList类提供了不少的成员支持程序员通过代码增、删和获取列表项,并支持管理诸如内容类型(content type)和字段(fields)等的元数据(metadata)。返回特定列表的高效方法是通过 SPWeb 或 SPListCollection 的 GetList 方法。ListItem类也提供了成员以支持管理列表项的字段(fields)、字段值(value of its fields)、它的内容类型以及与之关联的工作流(workflow)。返回列表项或 SPListItemCollection 的高效方法是通过 SPList 或 SPWeb 的 GetItem* 方法。 文件夹(Folder)在Sharepoint则由SPFolder类表示。SPFolder 类的 Files 属性返回文档库文件夹中的所有文件,而 SPWeb 的 Files 属性返回网站中使用的 .aspx 文件。返回特定文件夹的有效方式是使用网站的 GetFolder() 方法。列表项中的字段由SPField对象来表示。。
需要注意的是,虽然任何给定的列表项都有特定的内容类型与之关联,Sharepoint的对象模型只提供SPListItem类来表示所有的列表项。因此,当你操作列表项及其字段时,你更像在与一个弱类型环境(weakly typed enviorment)打交道。所以Sharepoint提供了SPMetal这个工具,SPMetal 是一类用于生成实体类的命令行工具,这些类可向 Microsoft SharePoint Foundation 内容数据库提供面向对象的界面。虽然这些类主要用于 LINQ to SharePoint 查询,但它们也可用于通过利用并发冲突解决方法来添加、删除和更改列表项。此外,还可将它们作为用于引用内容的常规 SharePoint Foundation 对象模型的替代项使用。使用SPMetal生成的实体类的好处就是你可以在编码阶段就发现那些有可能在运行时才能发现的某些错误。 比如说:某个列表中有一个字段名为Country的字段,程序员在通过传统方式获取这个字段的值时可能使用了myItem["Country"]代码,如果他把字段名用错了,比如用成了myItem["Countyr"],类似这种拼写错误,那么这种错误只会在运行时才能表现出来。但当你使用了SPMetal来生成实体类时,你就会看到myTask.Country这样的代码自动提示,从而更早避免了此类错误。
当然SPMetal也有如下限制:
•SPMetal 只能为内容类型的字段 生成代码。不存在到 SPListItem 对象的属性(例如 Properties 属性包或 Attachments 属性)的内置映射。
•SPMetal 不能为使用自定义字段数据类型的字段生成代码。
•SPMetal 无法预测未来,因此无法映射在部署解决方案后用户将添加到列表中的字段(列)
下图展示了Sharepoint各对象之间的关系(当然,还包括了物理层次结构与服务结构)。
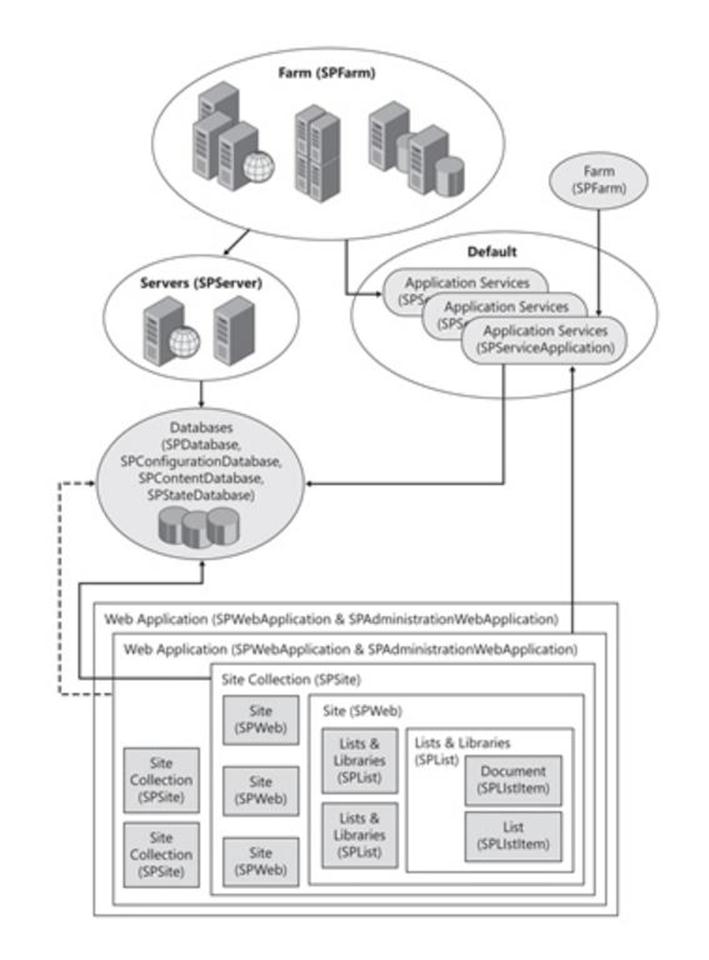
转载:http://www.cnblogs.com/wsdj-ITtech/archive/2013/01/08/2559338.html

















 118
118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









