






在做memcached分布式集群时往往要用到一致性hash算法来调节缓存数据的分布。
通常的hash算法是以服务器数量N作为模数,使用key%N的值来获得最终位置,显然当服务器数量发生变化即N发生变化是,所有的结果都会改变,导致缓存数据大面积失效,从而导致服务崩溃。
一致性hash的核心是模数采用不变的2**32次方作为模数,这样不管服务器的数量是否变化,服务器的hash值和数据的hash值都不会发生改变,但hash结果分布在0-2**32-1这个范围,那怎么才能对应呢?
一致性hash采用向后查询的方式来分配数据,如果hash值太大找不到对应的服务器,则归0继续查找。
假设我们将2**32这个范围放在一个环上:
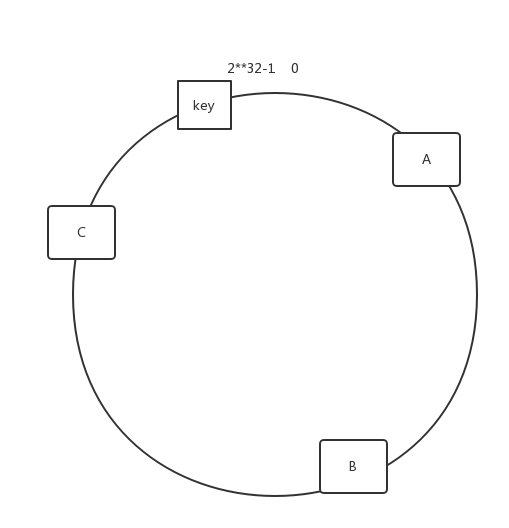
key将以顺时针的方向查找,最终分配到A服务器。
但如果服务器分配不均匀,ABC都挤在了一起怎么办呢?
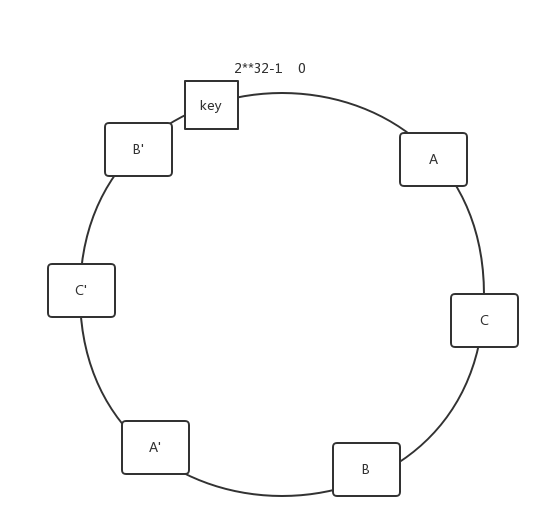
一致性hash默认在现有的服务器hash值基础上生成一些虚拟的hash值,尽量保证服务器hash值分布均匀。
所以采用一致性hash之后,当A服务器宕机,则key可以分配到C服务器上,即除了C服务器之外,其他的服务器不受影响。

















 7493
7493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









