 Java String详解
Java String详解







 本文深入剖析Java中的String类型,包括字符串初始化、字符串常量池的概念、字符串连接操作的底层原理及性能考量。
本文深入剖析Java中的String类型,包括字符串初始化、字符串常量池的概念、字符串连接操作的底层原理及性能考量。
一. 字符串基本知识要点
字符串类型String是Java中最常用的引用类型。我们在使用Java字符串的时候,通常会采用两种初始化的方式:1. String str = "Hello World"; 2. String str = new String("Hello World"); 这两种方式都可以将变量初始化为java字符串类型,通过第一种方式创建的字符串又被称为字符串常量。需要注意的是,Java中的String类是一个final类,str指向的字符串对象存储于堆中,而str本身则是存储在栈中的一个引用罢了。字符串对象一旦被初始化,则不允许再次被修改。从如下String的定义中我们可以验证以上所述:
1 public final class String implements java.io.Serializable, Comparable<String>, CharSequence{ 2 3 /** The value is used for character storage. */ 4 private final char value[]; 5 6 /** Cache the hash code for the string */ 7 private int hash; // Default to 0 8 9 }
从代码中我们发现,String前有final修饰,表示是final类;而其中存储的字符数组value[],也是由final修饰,表明一旦被赋值,则不允许再次修改。
那么,使用如上两种字符串初始化的方式有什么不同呢?我们可以通过如下代码体会:
public class EqualTest {
public static void main(String[] args) {
String s1 = "Hello";
String s2 = new String("Hello");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
程序输出结果为false和true。从== 和equals的区别上,我们一般这样来总结:==比较的是两个对象的引用,对象必须一模一样;equals则比较的是对象的内容,字符串内容一致便返回true。这说明,两种初始化的方式所构造的字符串对象,内容是一致的(可以理解为values数组一致),但是却是两个不同的对象,分别存储在内存的不同位置。其实,这两种初始化方式的最大不同在于,s1被初始化在字符串常量池中,而s2则存储在堆中。那么,什么是字符串常量池呢?
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价。JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。为了减少在JVM中创建的字符串的数量,字符串类维护了一个字符串池,每当代码创建字符串常量时,JVM会首先检查字符串常量池。如果字符串已经存在池中,就返回池中的实例引用。如果字符串不在池中,就会实例化一个字符串常量并放到池中。Java能够进行这样的优化是因为字符串是不可变的final类型,共享的时候不用担心数据冲突(读写不冲突,因为不能写,相当于数据库中的S锁,即共享锁)。在常量池中,任何字符串至多维护一个对象。字符串常量总是指向常量池中的一个对象。通过new操作符创建的字符串对象不指向池中的任何对象,但是可以通过使用字符串的intern()方法来指向其中的某一个。java.lang.String.intern()返回一个池字符串,就是一个在全局常量池中有了一个入口。如果该字符串以前没有在全局常量池中,那么它就会被添加到里面。
Java String类中有很多基本的方法。主要分成以下两个部分:
1)和value[]相关的方法:
- int length(); //返回String长度,即value[]数组长度;
- char charAt(int index); //返回指定位置字符;
- int indexOf(int ch, int fromIndex); //从fromIndex位置开始,查找ch字符在字符串中首次出现的位置;
- char[] toCharArray(); //将字符串转换成一个新的字符数组
2)和其他字符串相关的方法:
- int indexOf(String str, int fromIndex); //从fromIndex位置开始,查找str字符串在字符串中首次出现的位置;
- int lastIndexOf(String str, int fromIndex); //从fromIndex位置开始,反向查找str字符串在字符串中首次出现的位置;
- boolean contains(String str); //contains内部实现也是调用的indexOf,找不到则返回-1
- boolean startsWith(String str); //判断字符串是否以str开头
- boolean endsWith(String str); //判断字符串是否以str结尾
- String replace(CharSequence target, CharSequence replacement); //使用replacement替换target
- String substring(int beginIndex, int endIndex); //字符串截取,不传第二个参数则表示直接截取到字符串末尾
- String[] split(String regex); // 以regex作为分割点进行字符串分割
另外一个值得注意的细节是,String是不可变字符串对象,StringBuilder和StringBuffer是可变字符串对象(其内部的字符数组长度可变),StringBuffer线程安全,StringBuilder非线程安全。关于String的append操作,会在下面结合具体的例子进行解释。
二. 几个关于String的程序分析
2.1 intern的程序示例
参看如下程序:
public class StringTest1 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String s1 = "hello world";
String s2 = new String("hello world");
String s3 = s2.intern();
System.out.println(s1 == s2);
System.out.println(s1 == s3);
}
}
程序的输出是false,true。关于==和equals的区别在上面已做了详细的解释,由于s1是分配在字符串常量池中,s2则存储在堆中,因此两个对象并不是同一个对象,==操作返回false。而intern在JDK 1.7及以下,都是返回一个池字符串,该池字符串和原来的String对象的内容一致。若池中无该常量则添加,若有,则直接返回该常量的引用。因此,s1和s3是一个对象。说白了,在JVM的字符串常量池中,对于每一个字符串,只有一个共享的对象。
2.2 通过字节码进行深入分析
当情况变得复杂的时候,参看如下程序:
public class StringTest2 {
public static void main(String[] args){
String baseStr = "base";
final String baseFinalStr = "base";
//extend
String s1 = "baseext";
String s2 = "base" + "ext";
String s3 = baseStr + "ext";
String s4 = baseFinalStr + "ext";
String s5 = new String("baseext").intern();
System.out.println(s1 == s2);
System.out.println(s1 == s3);
System.out.println(s1 == s4);
System.out.println(s1 == s5);
}
}
这段程序乍一看非常复杂,里面有final String(final是限制在String对象的引用上,即该引用不能再更改所指向的String对象,String对象本身便是final类型的),还有字符串常量,以及字符串对象,和各个对象之间的“+”操作(“+”操作在下面的程序中详细解释)。那么我们不禁会问,在“+”操作的过程中,JVM到底是如何进行对象转换和操作呢?要想搞清楚这个问题,我们需要深入Bytecode一探究竟。使用javap -v XXX.class命令,可以打印出字节码文件中的符号表和指令等信息,该段程序的字节码输出如下:
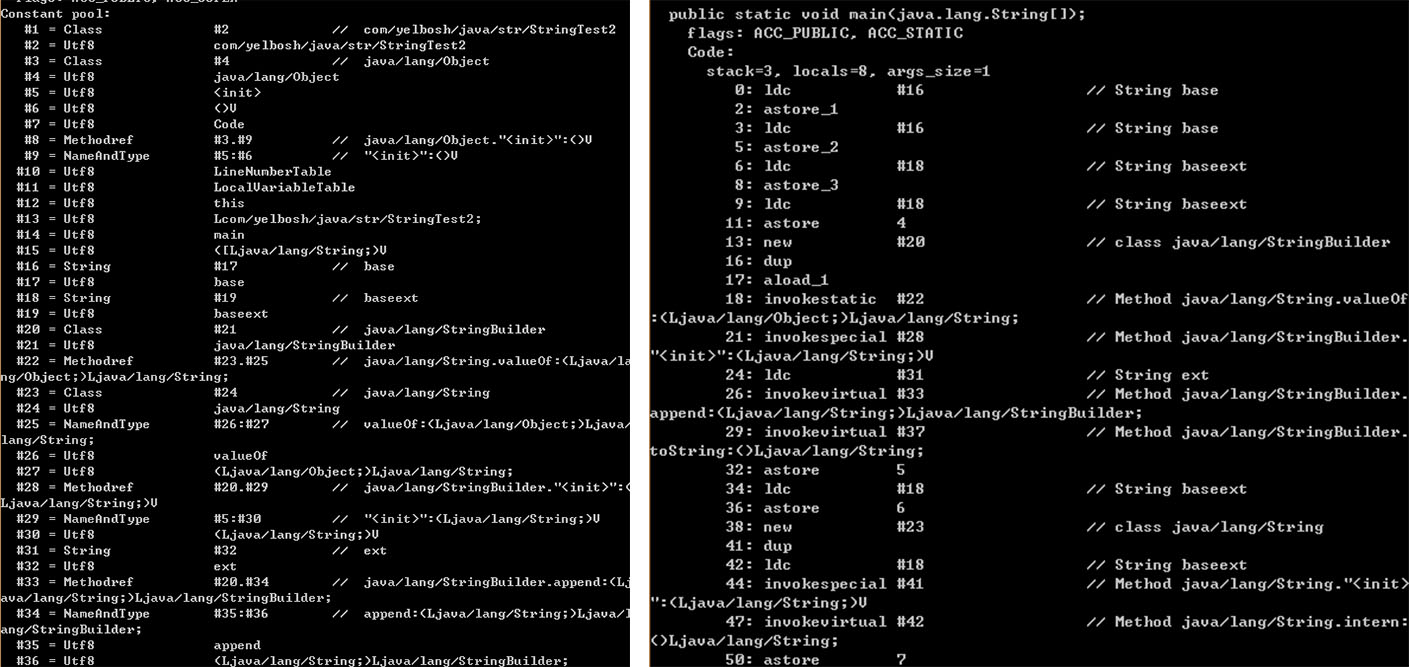
这里的constant pool指的是JVM内存结构中的运行时常量池,是方法区的一部分(参见周志明 《深入理解Java虚拟机》),我们上文提到的字符串常量池只是constant pool的一部分,除此之外,它还主要用来存储编译期生成的各种字面量和符号引用。javap -v的输出主要分为constant pool和方法体指令两部分,而指令中的操作数则是常量池中的序号。为了方便接下来的描述,我们先对常用的JVM字节码指令做一下说明:
LDC 将int, float或String型常量值从常量池中推送至栈顶;
ASTORE_<N> Store reference into local variable,将栈顶的引用赋值给第N个局部变量;
ALOAD 将指定的引用类型本地变量推送至栈顶
INVOKE VIRTUAL 调用实例方法
INVOKE SPECIAL 调用超类构造方法等初始化方法
INVOKE STATIC 调用静态方法
NEW 创建一个对象,并将其引用值压入栈顶
DUP 复制栈顶数值并将复制值压入栈顶
以上指令是需要仔细理解的。使用javap -v进行字节码的查看和理解可能比较困难,因为你要将 #序号 和 constant pool中的字面量不断照应已方便理解。Eclipse中提供了Bytecode Outline的插件可以很方便的查看和理解bytecode。插件的安装请自行百度,这里不再赘述。这里贴出本段代码的outline:
// access flags 0x9
public static main([Ljava/lang/String;)V
L0 //
LINENUMBER 5 L0
LDC "base" //将"base"从常量池推送至栈顶
ASTORE 1 //赋值给baseStr变量
L1
LINENUMBER 6 L1
LDC "base"
ASTORE 2 //赋值给baseFinalStr变量
L2
LINENUMBER 8 L2
LDC "baseext"
ASTORE 3
L3
LINENUMBER 9 L3
LDC "baseext" //注意,这里直接将"baseext"赋值给了s2,而没有进行"+"操作!!!
ASTORE 4
L4
LINENUMBER 10 L4
NEW java/lang/StringBuilder //创建StringBuilder对象
DUP
ALOAD 1 //将baseStr推送至栈顶
INVOKESTATIC java/lang/String.valueOf (Ljava/lang/Object;)Ljava/lang/String; //获取baseStr的value
INVOKESPECIAL java/lang/StringBuilder.<init> (Ljava/lang/String;)V //将创建的StringBuilder对象初始化为上一步获得的value
LDC "ext"
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder; //调用StringBuilder对象的append实例方法
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String; //调用StringBuilder对象的toString实例方法
ASTORE 5 //将toString的结果赋值给s3
L5
LINENUMBER 11 L5
LDC "baseext" //s4也是直接赋值
ASTORE 6
L6
LINENUMBER 12 L6
NEW java/lang/String
DUP
LDC "baseext"
INVOKESPECIAL java/lang/String.<init> (Ljava/lang/String;)V
INVOKEVIRTUAL java/lang/String.intern ()Ljava/lang/String; //调用intern()方法
ASTORE 7
//===================================以下为 输出部分,可以忽略=========================================
.......
.......
L19
LINENUMBER 17 L19
RETURN
L20 //类似于符号表,对应于local variable和变量编号
LOCALVARIABLE args [Ljava/lang/String; L0 L20 0
LOCALVARIABLE baseStr Ljava/lang/String; L1 L20 1
LOCALVARIABLE baseFinalStr Ljava/lang/String; L2 L20 2
LOCALVARIABLE s1 Ljava/lang/String; L3 L20 3
LOCALVARIABLE s2 Ljava/lang/String; L4 L20 4
LOCALVARIABLE s3 Ljava/lang/String; L5 L20 5
LOCALVARIABLE s4 Ljava/lang/String; L6 L20 6
LOCALVARIABLE s5 Ljava/lang/String; L7 L20 7
MAXSTACK = 3
MAXLOCALS = 8
如果想深入理解,请逐行理解以上字节码程序。根据程序的分析,我们不难得出输出结果:true false true true。
s1和s2,s4,s5都是指向字符串常量池中的同一个字符串常量。s2和s4中的“+”并没有起任何作用。String中使用 + 字符串连接符进行字符串连接时,连接操作最开始时如果都是字符串常量,编译后将尽可能多的直接将字符串常量连接起来,形成新的字符串常量参与后续连接。而s3中的第一个操作数是String对象类型,因此会首先以最左边的字符串为参数创建StringBuilder对象,然后依次对右边进行append操作,最后将StringBuilder对象通过toString()方法转换成String对象。
这里要注意的一点是,对于final字段修饰的字符串常量,编译期直接进行了常量替换。如果final修饰的不是字符串常量,而是字符串对象,如final String a = new String("baseStr"); 则和没有final修饰的情况是一样的,同样需要用StringBuilder进行append并toString才可以。
我们再通过一个程序来更深入的理解字符串常量和“+”操作符。程序如下:
public class AppendTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
String a = "aa";
String b = "bb";
String c = "xx" + "yy " + a + "zz" + "mm" + b;
System.out.println(c);
}
}
程序输出自然不用赘述,我们通过同样的方法查看Bytecode的outline,输出如下:
// access flags 0x21
public class com/yelbosh/java/str/AppendTest {
// compiled from: AppendTest.java
// access flags 0x1
public <init>()V
L0
LINENUMBER 3 L0
ALOAD 0
INVOKESPECIAL java/lang/Object.<init> ()V
RETURN
L1
LOCALVARIABLE this Lcom/yelbosh/java/str/AppendTest; L0 L1 0
MAXSTACK = 1
MAXLOCALS = 1
// access flags 0x9
public static main([Ljava/lang/String;)V
L0
LINENUMBER 6 L0
LDC "aa"
ASTORE 1
L1
LINENUMBER 7 L1
LDC "bb"
ASTORE 2
L2
LINENUMBER 8 L2
NEW java/lang/StringBuilder
DUP
LDC "xxyy " //直接load的是字符串常量“xxyy ”
INVOKESPECIAL java/lang/StringBuilder.<init> (Ljava/lang/String;)V
ALOAD 1
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder; //之后都是在调用StringBuilder对象的append实例方法
LDC "zz"
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
LDC "mm"
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
ALOAD 2
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String;
ASTORE 3
L3
LINENUMBER 9 L3
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
ALOAD 3
INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/String;)V
L4
LINENUMBER 10 L4
RETURN
L5
LOCALVARIABLE args [Ljava/lang/String; L0 L5 0
LOCALVARIABLE a Ljava/lang/String; L1 L5 1
LOCALVARIABLE b Ljava/lang/String; L2 L5 2
LOCALVARIABLE c Ljava/lang/String; L3 L5 3
MAXSTACK = 3
MAXLOCALS = 4
}
通过这个程序,更印证了我们如上的结论。
通过这个深入分析,我们在写代码的时候,也要注意使用StringBuilder对象。如果直接在for循环中使用“+”操作符进行字符串对象(常量无所谓)的拼接,那么实际上在每次循环的时候,都要创建StringBuilder,然后append,再toString出来,因此性能是十分低下的。这个时候,就需要在循环外声明StringBuilder对象,然后在循环内调用append方法进行拼接。另外要注意的是,StringBuilder是线程不安全的,如果涉及到多个线程同时对StringBuilder的append操作,请使用synchronized或lock确保并发访问的安全性,或者转而使用线程安全的StringBuffer。
总结:Java String是非常灵活的一个对象,但是只要把细节搞清楚,问题还是很简单的。在实际编码的过程中,一定要考虑字符串操作的性能和线程安全问题,这样才能更好的运用字符串完成自己的业务逻辑。希望这篇博文能对您的学习有些帮助,如果错误,请不吝赐教。

















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









