



写
在前面
在目前为止所有小伙伴们向大猫请教过的R问题中,大猫总结了最常遇见同时也是比较难的三个问题,分别是(1)事件研究法;(2)分组回归;(3)滚动回归。事件研究法在第一期中已经讲述,本期我们就来瞧瞧如何做分组回归~
PS:由于微信的限制,给大猫留言的小伙伴超过48小时后大猫就不能回复你们了。所以如果想联系大猫,可以按照文章最后的微信号加大猫微信哦。
问
题引入
很多时候我们需要处理的数据集中会有一个变量用于标记变量所在的组。例如下图中,stkid(我们可以把它想象成股票代码)有五种可能:a, b, c, d, e,每一个字母表示一只股票。y是因变量,可以想象成股票的日收益,x是自变量,可以想象成市场收益。我们希望对于每个股票,都跑一个如下回归:
y = x
并且把系数都保存在输出数据集中。
图:样例数据集
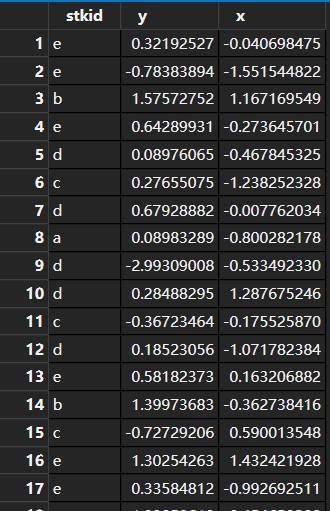
看似非常简单,但其实想要高效优美地实现是需要一定技巧滴。很多小伙伴大动干戈想把原数据集按照stkid的值拆成若干子数据集,并用for循环来做回归——大可不必这样。其实,要实现这一步只需要一行代码哦。
为了便于说明问题,我们先构造一个样例数据集:
# 确定随机数种子
# 想知道为什么要把42作为随机数种子?在google中输入“the answer to life the universe and everything”会有惊喜哦。
set.seed(42)
# 生成样例数据集dt,其一共有100行。stkid代表分组变量,有a, b, c, d, e五个类别;x和y分别随机生成
dt
要实现一行代码完成分组回归,需要用到data.table包!
步
骤分解
我们先把这一行优雅的代码放上来:
# result是输出数据集
result
最终的输出数据集是这个样子的:
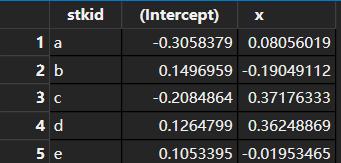
现在我们逐一分析这一行代码。
- keyby语句为data.table包中的分组语句,它能够对keyby中的每一个不同的值(这里为abcde)都分别跑一次回归。
- ".SD"的含义是Subset of Data,每一个.SD都代表一个由keyby所决定的分组。具体而言,如果此时keyby语句循环到'a',那么.SD就表示原数据集中所有stkid == 'a'的行。在这里,.SD用来作为回归函数lm的输入数据集。
- coef函数用来提取回归的系数。
- 整行代码的关键在as.list函数。我们先看看如果不加as.list结果会是怎样的:
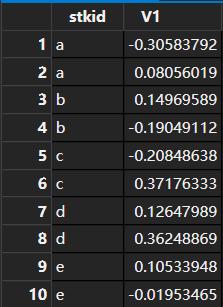
小伙伴们会发现此时每个组都有两行观测,其实他们分别对应着回归的intercept和coefficient。如果我们的回归不是单自变量而是双自变量,那么每个分组就会有三行观测了,一行是截距,还有两行是系数。
as.list的作用就在于,它把原来“竖着”的系数给“拉平”了,无论最终结果会出现几个系数,统统放到一行中显示。其中的原理是,data.table最终的输出必须是一个class为list的元素,符合条件的除了list自己,还包括 data.frame,data.table等。如果我们只加coef函数而不加as.list,那么最终输出的是一个vector,data.table会自动把这个vector拉直(也就是上图看到的这样),而加了as.list之后,原来输出vector就被打包成了list,变成了我们需要的样子。
拓
展
这时有的小伙伴可能想问,有没有可能同时计算两个不同的回归方程?比如还是上面这个数据集,我想同时输出带系数的回归结果和不带系数的回归结果,应该怎么做?
还是只需要一行,大猫在这里给出答案(重点已经用红笔标出来啦):
result
结果是:
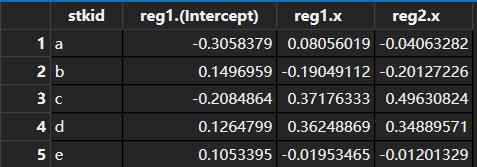
是不是很神奇?至于原理,大家自己回去研究哦。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









