



 本文介绍了爬虫技术的基础知识,包括使用Requests与BeautifulSoup抓取网页数据的方法,利用Selenium破解滑动验证的技巧,以及Scrapy框架的应用。通过具体案例展示了如何实现登录并抓取个人数据,以及破解滑动验证的具体步骤。
本文介绍了爬虫技术的基础知识,包括使用Requests与BeautifulSoup抓取网页数据的方法,利用Selenium破解滑动验证的技巧,以及Scrapy框架的应用。通过具体案例展示了如何实现登录并抓取个人数据,以及破解滑动验证的具体步骤。
一、爬虫基础-Requests&BeautifulSoup
心得体会:爬虫基本原理就是模仿浏览器的行为,来爬取我们所需要的数据。利用Request向指定地址发送请求,并且获取其返回值。在爬取数据时,根据情况所需,添加请求头,或者COOKIE。有时候爬取的对象的防爬策略比较高深,需要根据浏览器的开发者工具中Network工具,来一步一步分析我们所爬取对象的数据与后台交互的过程,进一步的完善爬虫,更像一个浏览器在访问。
知识点总结:Requests的基本使用,需要掌握请求的类型('method'),请求地址('url'),请求时的所带数据('data', 'json', 'params'),数据的类型('POST', 'GET'),请求头('headers'),COOKIE。


import requests r1 = requests.request( method='get', url='', ) r2 = requests.request( method='post', url='', )
BeautifulSoup是一个格式化工具,必须掌握最基本的标签查找,页面标签的内容提取。
代码演示:
from bs4 import BeautifulSoup import requests r = requests.request( method='get', url='https://github.com/login', headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' }, ) r.encoding = r.apparent_encoding key = BeautifulSoup(r.text, 'html.parser').find( name='input', attrs={ 'name': 'authenticity_token' }, ).get('value') r2 = requests.request( method='post', url='https://github.com/session', cookies=r.cookies, headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' }, data={ 'commit': 'Sign in', 'utf8': '✓', 'authenticity_token': key, 'login': 'WaveCloud592@outlook.com', 'password': 'WaveCloud999', } ) r3 = requests.request( method='get', url='https://github.com/WaveCloud592', cookies=r2.cookies, headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' }, ) r3.encoding = r3.apparent_encoding myinfo = BeautifulSoup(r3.text, 'html.parser') # # 头像 img = myinfo.find( name='img', attrs={ 'alt': '@WaveCloud592' }, ).get('src') imgFile = requests.request( method='get', url=img ) with open('img.png', 'wb') as f: f.write(imgFile.content) # # 名字 name = myinfo.find( name='span', attrs={ 'itemprop': 'name' }, ) print('我的名字:%s' % name.text) # # 用户名 name = myinfo.find( name='span', attrs={ 'itemprop': 'additionalName' }, ) print('我的用户名:%s' % name.text) # # 我的签名 cont = myinfo.find( name='div', attrs={ 'class': 'js-user-profile-bio-contents' }, ).find( name='div' ) print('我的个性签名:%s' % cont.text) # # 我的组织 group = myinfo.find( name='span', attrs={ 'class': 'p-org', }, ).find( name='div' ) print('我的组织:%s' % group.text) # # 地区 diqu = myinfo.find( name='span', attrs={ 'class': 'p-label' }, ) print('地区:%s' % diqu.text) # # 我的网址 url = myinfo.find( name='a', attrs={ 'class': 'u-url' }, ) print('我的网址:%s' % url.text)
二、爬虫基础-简单破解滑动验证
心得体会:万物以基础为繁衍,进行多次的改造和封装,内部原理永不更变。破解滑动验证亦是模仿浏览器的行为,但并不是发送数据或者发送请求,而是说模仿人的动作,进行滑动验证的操作(类似于按键精灵),并且通过各方面的比对,进行“块儿”的滑动。
知识点总结:Selenium是一个第三方模块,可以完全模拟用户在浏览器上操作。使用前需要拥有浏览器的内核(驱动)。
Firefox https://github.com/mozilla/geckodriver/releases Chrome http://chromedriver.storage.googleapis.com/index.html
Selenium模块儿支持一下浏览器内核:
在当前文件夹中的“__init__.py”文件中可以详细查看每个浏览器的“类”,类中封装了其对应的对象方法。
每创建一个动作行为(某个浏览器针对指定网站的模拟操作)就必须实例化指定浏览器的对象。
操作时,需掌握最基本的方法(chrome.webdriver.WebDriver对象为例):get(), get_cookies(), close()以及页面标签的查找方法。
代码演示:
from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait import os import shutil from PIL import Image import time def get_snap(driver): driver.save_screenshot('full_snap.png') page_snap_obj = Image.open('full_snap.png') return page_snap_obj def get_image(driver): img = driver.find_element_by_class_name('geetest_canvas_img') time.sleep(2) location = img.location size = img.size left = location['x'] top = location['y'] right = left + size['width'] bottom = top + size['height'] page_snap_obj = get_snap(driver) image_obj = page_snap_obj.crop((left * 2, top * 2, right * 2, bottom * 2)) # image_obj.show() with open('code.png', 'wb') as f: image_obj.save(f, format='png') return image_obj def get_distance(image1, image2): # start = 0 # threhold = 70 # for i in range(start, image1.size[0]): # for j in range(0, image1.size[1]): # rgb1 = image1.load()[i, j] # rgb2 = image2.load()[i, j] # res1 = abs(rgb1[0] - rgb2[0]) # res2 = abs(rgb1[1] - rgb2[1]) # res3 = abs(rgb1[2] - rgb2[2]) # # print(res1,res2,res3) # if not (res1 < threhold and res2 < threhold and res3 < threhold): # print(111111, i, j) # return i - 13 # print(2222, i, j) # return i - 13 start = 0 threhold = 70 v = [] for i in range(start, image1.size[0]): for j in range(0, image1.size[1]): rgb1 = image1.load()[i, j] rgb2 = image2.load()[i, j] res1 = abs(rgb1[0] - rgb2[0]) res2 = abs(rgb1[1] - rgb2[1]) res3 = abs(rgb1[2] - rgb2[2]) if not (res1 < threhold and res2 < threhold and res3 < threhold): print(i) if i not in v: v.append(i) stop = 0 for i in range(0, len(v)): val = i + v[0] if v[i] != val: stop = v[i] break width = stop - v[0] print(stop, v[0], width) return width def get_tracks(distance): import random exceed_distance = random.randint(0, 5) distance += exceed_distance # 先滑过一点,最后再反着滑动回来 v = 0 t = 0.2 forward_tracks = [] current = 0 mid = distance * 3 / 5 while current < distance: if current < mid: a = random.randint(1, 3) else: a = random.randint(1, 3) a = -a s = v * t + 0.5 * a * (t ** 2) v = v + a * t current += s forward_tracks.append(round(s)) # 反着滑动到准确位置 v = 0 t = 0.2 back_tracks = [] current = 0 mid = distance * 4 / 5 while abs(current) < exceed_distance: if current < mid: a = random.randint(1, 3) else: a = random.randint(-3, -5) a = -a s = -v * t - 0.5 * a * (t ** 2) v = v + a * t current += s back_tracks.append(round(s)) return {'forward_tracks': forward_tracks, 'back_tracks': list(reversed(back_tracks))} def crack(driver): # 破解滑动认证 # 1、点击按钮,得到没有缺口的图片 button = driver.find_element_by_xpath('//*[@id="embed-captcha"]/div/div[2]/div[1]/div[3]') button.click() # 2、获取没有缺口的图片 image1 = get_image(driver) # 3、点击滑动按钮,得到有缺口的图片 button = driver.find_element_by_class_name('geetest_slider_button') button.click() # 4、获取有缺口的图片 image2 = get_image(driver) # 5、对比两种图片的像素点,找出位移 distance = get_distance(image1, image2) print(distance) # # 6、模拟人的行为习惯,根据总位移得到行为轨迹 tracks = get_tracks(int(distance / 2)) # 7、按照行动轨迹先正向滑动,后反滑动 button = driver.find_element_by_class_name('geetest_slider_button') ActionChains(driver).click_and_hold(button).perform() # 正常人类总是自信满满地开始正向滑动,自信地表现是疯狂加速 for track in tracks['forward_tracks']: ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform() # 结果傻逼了,正常的人类停顿了一下,回过神来发现,卧槽,滑过了,然后开始反向滑动 time.sleep(0.5) for back_track in tracks['back_tracks']: ActionChains(driver).move_by_offset(xoffset=back_track, yoffset=0).perform() # # # 小范围震荡一下,进一步迷惑极验后台,这一步可以极大地提高成功率 ActionChains(driver).move_by_offset(xoffset=3, yoffset=0).perform() ActionChains(driver).move_by_offset(xoffset=-3, yoffset=0).perform() # # 成功后,骚包人类总喜欢默默地欣赏一下自己拼图的成果,然后恋恋不舍地松开那只脏手 time.sleep(0.5) ActionChains(driver).release().perform() def login_luffy(username, password): driver = webdriver.Chrome('/Users/wupeiqi/drivers/chromedriver') driver.set_window_size(960, 800) try: # 1、输入账号密码回车 driver.implicitly_wait(3) driver.get('https://www.luffycity.com/login') input_username = driver.find_element_by_xpath('//*[@id="router-view"]/div/div/div[2]/div[2]/input[1]') input_pwd = driver.find_element_by_xpath('//*[@id="router-view"]/div/div/div[2]/div[2]/input[2]') input_username.send_keys(username) input_pwd.send_keys(password) # 2、破解滑动认证 crack(driver) time.sleep(10) # 睡时间长一点,确定登录成功 finally: pass # driver.close() if __name__ == '__main__': login_luffy(username='wupeiqi', password='123123123')
三、爬虫框架-scrapy
心得体会:scrapy框架是是一款异步IO流的框架,内部基于twisted实现,完成了并发请求、数据爬去、数据持久化等操作。其中好可以利用scrapy-redis这个组件,进行分布式的操作,提高了灵活性、实用性。
知识点总结:
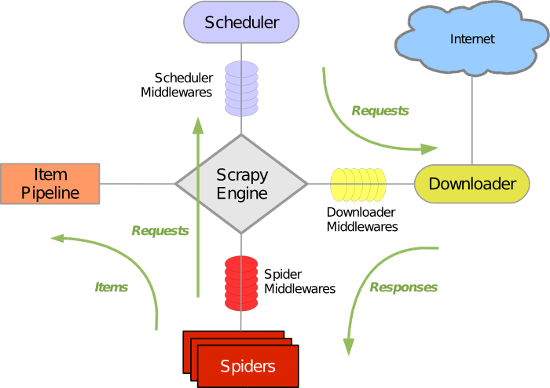
上图中,是scrapy框架的基本流程走向,以及其内部的组件。
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
- 引擎(Scrapy)
scrapy-redis是一个基于redis的scrapy组件,通过它可以快速实现简单分布式爬虫程序,该组件本质上提供了三大功能:
- scheduler - 调度器
- dupefilter - URL去重规则(被调度器使用)
- pipeline - 数据持久化
基本的Scrapy流程走向:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
一个简单的示例(路飞爬虫密训第三次作业):
链接:https://pan.baidu.com/s/1_MM7ntmEJ6LhaENEBGRgGQ 密码:rf54

















 1757
1757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









