



---恢复内容开始---
HADOOP:海量数据的计算和存储
HDFS
不管读还是写,客户端都要先访问NN
NN:hdfs系统中的文件与真实的block之间的映射,由NN管理。
hdfs的shell操作:
hadoop fs -cat/-put /-get/ls /
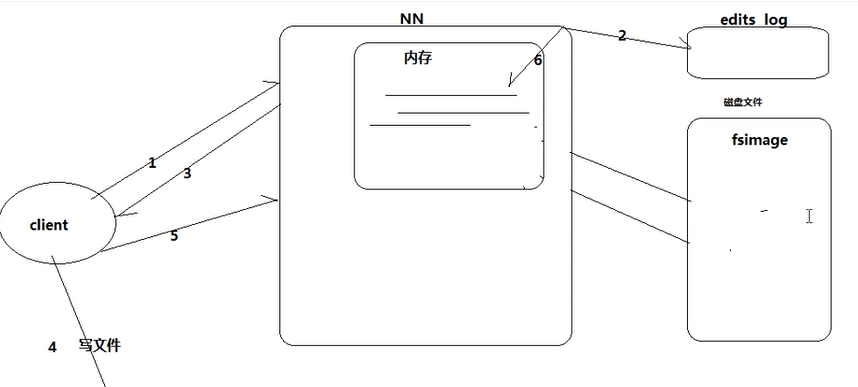
HDFS上传文件的流程
1.客户端向NN节点发出请求;
2.NN向客户端返回可以存数据的DN,并且往edits log文件中记录元数据操作日志;
3.客户端根据返回的信息将文件分块(1个block128M);
(客户端上传文件成功后,NN在内存中写入这次上传操作产生的元数据)
4.通过NN返回的DN信息,直接发送给DN,同时复制到其他两台机器;
5. DN向客户端通信,表示传完数据,同时向NN报告。
NN元数据管理机制
1.写副本
-对于客户端,只用写1个副本;剩余两个副本,由1个DN复制到另一个DN(管道)【这个过程与客户端写副本过程是异步进行的】。
客户端在连上的DN上写第一个副本,第二个副本放在另外一个机架上,第三个副本在本机架上随便找一个。
3个副本的保证,由NN进行管理。
-下一个副本成功复制后,会向上一个副本返回响应,如果返回失败响应,最终NN会接收到这个响应,然后重新分配1个DN进行复制。

2.元数据管理
磁盘fsimage(定期与edits log做合并) +内存(查询)+edits log(记录元数据)
当 edits log写满时,需要将这一段时间的新的元数据刷到fsimage中去
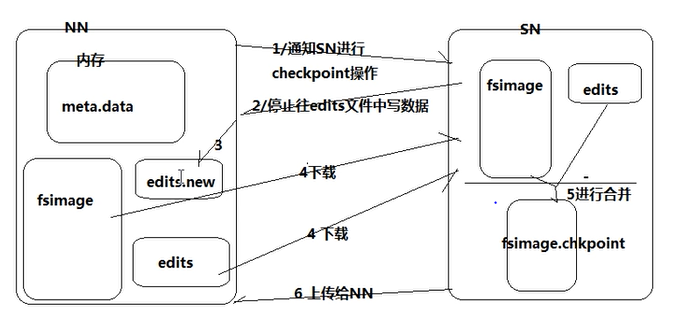
3.SN:fsimage与edits log的合并
checkpoint的时间:1.规定edits文件的最大值 ,默认64M 2.两次checkpoint之间的最大时间 默认3600秒
NN工作机制
维护元数据信息 维护hdfs目录树 响应客户端请求
DN工作机制
block 默认 128M,如果1个文件小于一个数据块的大小,并不占用整个数据块存储空间。
shell命令练习:
hadoop fs -put jdk /
HDFS的java客户端
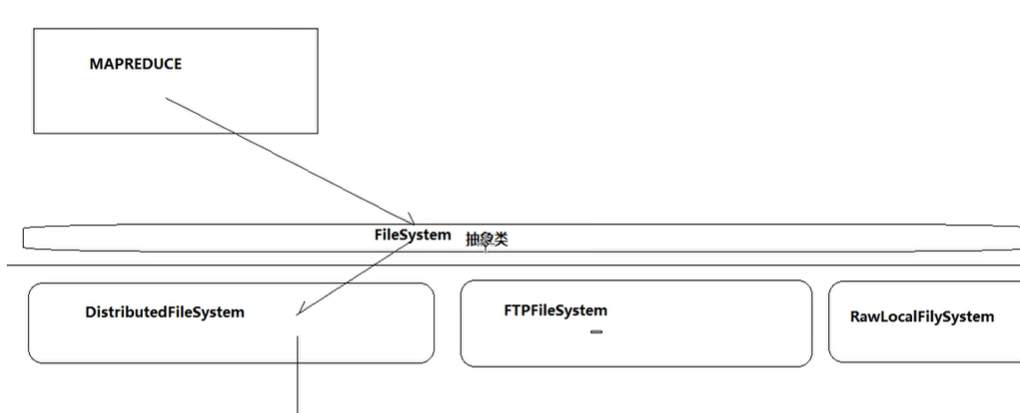
FileSystem抽象类 有很多子类(不同的文件存储类型)
RPC框架实现机制
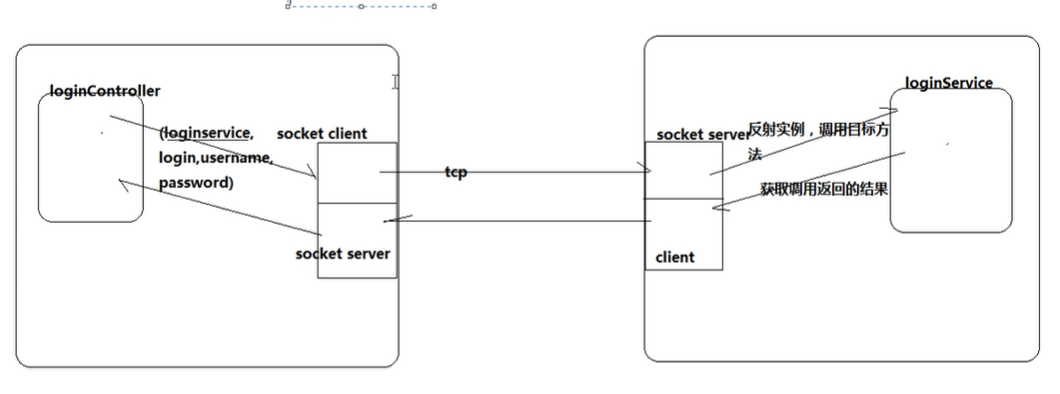
客户端与NN\ NN与DN\ 都通过RPC调用
DN会定期向NN汇报自己的block信息(例如某个block损坏了)
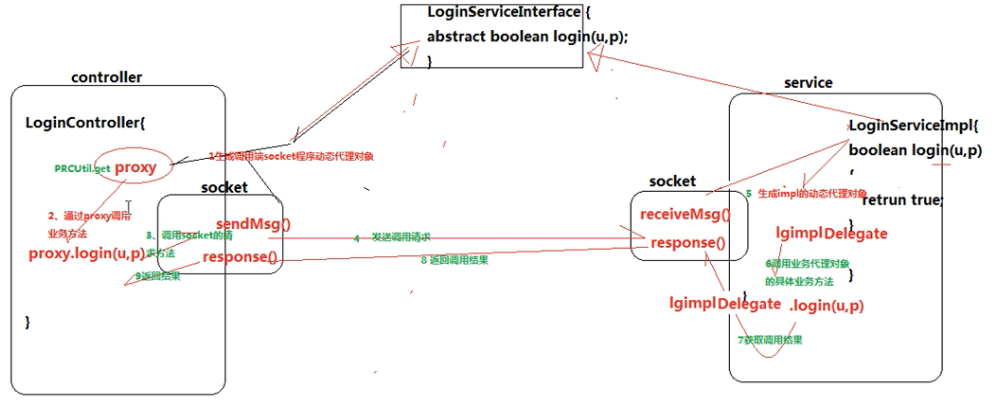
RPC????动态代理+反射+socket通信
hadoop对于小文件的处理办法
HDFS如何容错
一致性模型
在向HDFS写数据时,当某一个副本出错怎么办
hadoop和yarn的任务调度算法和任何对垒
HDFS接口类型
联邦HDFS
HDFS什么时候会出现副本数量多于设定值的情况
HDFA如何添加和撤销数据节点
NN的数据块和数据节点管理
HDFS有一个数据块损坏怎么处理
HDFS有一个数据块,如何知道其副本的数量
客户端在写入数据时只写入1个数据块,怎么处理
HDFS删除多余副本
HDFS删除一个文件的过程
mapreduce 简单的运算逻辑扩展到海量数据
案例:海量文件中某个参数出现的次数?wordcount?
map
相同的key分发到同一个reduce中。
wordmapper类:继承mapper类<1,2,3,4,>定义4个泛型,表示数据输入输出格式 都是k-v对形式
1.默认情况下,mapper中的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
2.<Long,String,自己定义,自己定义>---------<LongWritable,Text,自己定义,自己定义>
注意:这些数据在网络之间传递,所以需要序列化。hadoop自己的序列化机制,所以要使用hadoop自己的序列化类型.(jdk本身的序列化方法有很多附加信息,不适合在网络之间传输)
3.重写map方法(每读一行数据,就调用一下这个方法)
//写具体业务逻辑
//context.write(k,v)将结果输出
------------------------------------------------------------------------------------------------------------
每一组k统计完了,才会发送给reduce,也就是缓存层。
wordreducer类:继承reducer类<1,2,3,4,>定义4个泛型,表示数据输入输出格式
<Text key,Iterable<LongWritable> values,Content content>注意这里是迭代器!因为values是1个集合。
1.传递一个key,调用1次reduce方法。<hello,{1,1,1,1,1.....}>
2.遍历value,进行累加求和
3.输出统计结果context.write(key,new LongWritable(count) );
-------------------------------------------------------------------------------------------------------------
job描述
描述哪个mapper对应哪个reducer,指定要处理的数据路径,指定数据输出结果放在哪里。
hadoop:Job job=Job.getInstance(conf);
指定mapper和reduce
job.setMapperClass()
job.setReducerClass()
指定reduce的输出数据类型
job.setOutputKeyClass(Text.class)
指定rmapper的输出数据类型
指定原始数据在哪里
![]()
![]()
提交到集群运行
![]()
打成jar包,传到hadoop服务器,hadoop jar wc.jar (全路径包名)
查看结果 hadoop fs -cat (文件名)
切片
工作机制
计数器
shuffle机制
shuffle机制的缺陷
combiner函数何时被使用reduce函数如何知道从哪台机器获取map输出
yarn
applicationMaster 故障后如何处理
资源调度器
架构
APPmaster向resourcemanager申请资源的过程
container
hadoop文件读流程和写流程
读流程
1.客户端发起RPC请求访问NN;
2.NN查询元数据,找到这个文件的存储位置对应的数据块信息;
3.NN将文件对应的数据块节点地址放入1个队列中然后返回;
4.客户端收到数据块对应的节点地址;
5.客户端从队列中取出第一个数据块对应的节点地址,会从这些节点中选取一个最近的节点进行读取;
6.读取Block后,对block进行scheksum的验证,如果验证失败,说明数据块产生损坏,此时向NN发送信息进行说明,然后从其他节点读取数据块;
7.验证成功,则从队列中取出下一个block的地址,继续读取;
8.当把这一次的文件快全部读取完成之后,客户端向NN要下一批block的地址;
9.文件全部读取成功后,客户端向NN发送读取完毕的信号,NN关闭对应的文件。
写流程
1.客户端发送RPC请求给NN;
2.NN接收到请求后,对请求进行验证,例如请求的文件是否存在;
3.验证通过后,NN确定文件的大小以及分块的数量,确定对应的节点,将节点放入队列中返回;
4.客户端收到地址后,从队列中取出节点地址,然后数据块依次放入对应的节点地址上;
5.客户端在写完之后向NN发送写完数据的信号,NN会给客户端1个关闭文件的信号;
6.DN之间将会通过管道进行自动备份,保证副本数量。
Hive
只读不写
查询速度较慢
hive数据倾斜原因及处理办法
linux命令
在linux中找到满足下列条件的文件:
1.文件名包含字符串“profile”
find /path -name '*profile*'
2文件大小大于10MB
find . -type f -size +10M
3文件的修改时间在7天前
find . -type f -mtime +7;
以MR任务为例,yarn的整个过程
Hbase各个组成成分和作用
HBASE删除一条数据的过程
HA
SN
Mapreduece
框架和使用场景
API使用
运行机制
shuffle机制:map和reduce中间的数据调度机制,包含缓存,分区,排序。
reduce task数量决定机制
业务逻辑需要(有些场景只能有一个,比如统计某一个单词出现的次数)
数据量大小 job.setnumberReduceTsks(n)
如果重写了分区,就必须使任务数大于等于分区数。
map task数量决定
完全取决于数据量的大小
split
默认的切片机制:
Textinputformat.getsplit(“path”)做切片规划
1. 定义切片大小,可以通过参数调节,但是默认情况等于hdfs中的设置的blocksize
2. 获取数据目录下所有待处理文件list
3. 遍历文件list,逐个文件进行切片
For(file:list)
对file从0偏移量开始切,每128M构成一个切片
比如a.txt(200M),就会切成 a.txt0-128M,a.txt128M-256M
b.txt 切成1个 b.txt 0-80M
如果要处理的数据是大量的小文件???,使用上述切片机制导致大量的切片,但是每个切片非常小,导致map task进程多,但数据量很小,效率很低。
解决:将多个小文件划分为1和切片,自定义inputfoemat子类,重写split
Mapreduce自带实现类:combinefileinputformat
Yarn
框架和使用场景
Resourcemanager 主节点master 只需要1个来工作
Nodemanager 从节点 根据集群规模可以有很多个
心跳通信?
1. yarn只负责资源的分配,不参与job具体的运行机制
2. mapreduce有一个进程mrappmaster来负责程序的运行流程控制
3. yarn可以为各种应用程序提供资源服务(类似于操作系统平台)
4. 可以把各种分布式框架整合到hadoop集群

---恢复内容结束---
HADOOP:海量数据的计算和存储
HDFS
不管读还是写,客户端都要先访问NN
NN:hdfs系统中的文件与真实的block之间的映射,由NN管理。
hdfs的shell操作:
hadoop fs -cat/-put /-get/ls /
HDFS上传文件的流程
1.客户端向NN节点发出请求;
2.NN向客户端返回可以存数据的DN,并且往edits log文件中记录元数据操作日志;
3.客户端根据返回的信息将文件分块(1个block128M);
(客户端上传文件成功后,NN在内存中写入这次上传操作产生的元数据)
4.通过NN返回的DN信息,直接发送给DN,同时复制到其他两台机器;
5. DN向客户端通信,表示传完数据,同时向NN报告。
NN元数据管理机制
1.写副本
-对于客户端,只用写1个副本;剩余两个副本,由1个DN复制到另一个DN(管道)【这个过程与客户端写副本过程是异步进行的】。
客户端在连上的DN上写第一个副本,第二个副本放在另外一个机架上,第三个副本在本机架上随便找一个。
3个副本的保证,由NN进行管理。
-下一个副本成功复制后,会向上一个副本返回响应,如果返回失败响应,最终NN会接收到这个响应,然后重新分配1个DN进行复制。
2.元数据管理
磁盘fsimage(定期与edits log做合并) +内存(查询)+edits log(记录元数据)
当 edits log写满时,需要将这一段时间的新的元数据刷到fsimage中去
3.SN:fsimage与edits log的合并
checkpoint的时间:1.规定edits文件的最大值 ,默认64M 2.两次checkpoint之间的最大时间 默认3600秒
NN工作机制
维护元数据信息 维护hdfs目录树 响应客户端请求
DN工作机制
block 默认 128M,如果1个文件小于一个数据块的大小,并不占用整个数据块存储空间。
shell命令练习:
hadoop fs -put jdk /
HDFS的java客户端
FileSystem抽象类 有很多子类(不同的文件存储类型)
RPC框架实现机制
客户端与NN\ NN与DN\ 都通过RPC调用
DN会定期向NN汇报自己的block信息(例如某个block损坏了)
RPC????动态代理+反射+socket通信
hadoop对于小文件的处理办法
HDFS如何容错
一致性模型
在向HDFS写数据时,当某一个副本出错怎么办
hadoop和yarn的任务调度算法和任何对垒
HDFS接口类型
联邦HDFS
HDFS什么时候会出现副本数量多于设定值的情况
HDFA如何添加和撤销数据节点
NN的数据块和数据节点管理
HDFS有一个数据块损坏怎么处理
HDFS有一个数据块,如何知道其副本的数量
客户端在写入数据时只写入1个数据块,怎么处理
HDFS删除多余副本
HDFS删除一个文件的过程
mapreduce 简单的运算逻辑扩展到海量数据
案例:海量文件中某个参数出现的次数?wordcount?
map
相同的key分发到同一个reduce中。
wordmapper类:继承mapper类<1,2,3,4,>定义4个泛型,表示数据输入输出格式 都是k-v对形式
1.默认情况下,mapper中的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
2.<Long,String,自己定义,自己定义>---------<LongWritable,Text,自己定义,自己定义>
注意:这些数据在网络之间传递,所以需要序列化。hadoop自己的序列化机制,所以要使用hadoop自己的序列化类型.(jdk本身的序列化方法有很多附加信息,不适合在网络之间传输)
3.重写map方法(每读一行数据,就调用一下这个方法)
//写具体业务逻辑
//context.write(k,v)将结果输出
------------------------------------------------------------------------------------------------------------
每一组k统计完了,才会发送给reduce,也就是缓存层。
wordreducer类:继承reducer类<1,2,3,4,>定义4个泛型,表示数据输入输出格式
<Text key,Iterable<LongWritable> values,Content content>注意这里是迭代器!因为values是1个集合。
1.传递一个key,调用1次reduce方法。<hello,{1,1,1,1,1.....}>
2.遍历value,进行累加求和
3.输出统计结果context.write(key,new LongWritable(count) );
-------------------------------------------------------------------------------------------------------------
job描述
描述哪个mapper对应哪个reducer,指定要处理的数据路径,指定数据输出结果放在哪里。
hadoop:Job job=Job.getInstance(conf);
指定mapper和reduce
job.setMapperClass()
job.setReducerClass()
指定reduce的输出数据类型
job.setOutputKeyClass(Text.class)
指定rmapper的输出数据类型
指定原始数据在哪里
![]()
![]()
提交到集群运行
![]()
打成jar包,传到hadoop服务器,hadoop jar wc.jar (全路径包名)
查看结果 hadoop fs -cat (文件名)
切片
工作机制
计数器
shuffle机制
shuffle机制的缺陷
combiner函数何时被使用reduce函数如何知道从哪台机器获取map输出
yarn
applicationMaster 故障后如何处理
资源调度器
架构
APPmaster向resourcemanager申请资源的过程
container
hadoop文件读流程和写流程
读流程
1.客户端发起RPC请求访问NN;
2.NN查询元数据,找到这个文件的存储位置对应的数据块信息;
3.NN将文件对应的数据块节点地址放入1个队列中然后返回;
4.客户端收到数据块对应的节点地址;
5.客户端从队列中取出第一个数据块对应的节点地址,会从这些节点中选取一个最近的节点进行读取;
6.读取Block后,对block进行scheksum的验证,如果验证失败,说明数据块产生损坏,此时向NN发送信息进行说明,然后从其他节点读取数据块;
7.验证成功,则从队列中取出下一个block的地址,继续读取;
8.当把这一次的文件快全部读取完成之后,客户端向NN要下一批block的地址;
9.文件全部读取成功后,客户端向NN发送读取完毕的信号,NN关闭对应的文件。
写流程
1.客户端发送RPC请求给NN;
2.NN接收到请求后,对请求进行验证,例如请求的文件是否存在;
3.验证通过后,NN确定文件的大小以及分块的数量,确定对应的节点,将节点放入队列中返回;
4.客户端收到地址后,从队列中取出节点地址,然后数据块依次放入对应的节点地址上;
5.客户端在写完之后向NN发送写完数据的信号,NN会给客户端1个关闭文件的信号;
6.DN之间将会通过管道进行自动备份,保证副本数量。
Hive
只读不写
查询速度较慢
hive数据倾斜原因及处理办法
linux命令
在linux中找到满足下列条件的文件:
1.文件名包含字符串“profile”
find /path -name '*profile*'
2文件大小大于10MB
find . -type f -size +10M
3文件的修改时间在7天前
find . -type f -mtime +7;
以MR任务为例,yarn的整个过程
Hbase各个组成成分和作用
HBASE删除一条数据的过程
HA
SN
Mapreduece
框架和使用场景
API使用
运行机制
shuffle机制:map和reduce中间的数据调度机制,包含缓存,分区,排序。
reduce task数量决定机制
业务逻辑需要(有些场景只能有一个,比如统计某一个单词出现的次数)
数据量大小 job.setnumberReduceTsks(n)
如果重写了分区,就必须使任务数大于等于分区数。
map task数量决定
完全取决于数据量的大小
split
默认的切片机制:
Textinputformat.getsplit(“path”)做切片规划
1. 定义切片大小,可以通过参数调节,但是默认情况等于hdfs中的设置的blocksize
2. 获取数据目录下所有待处理文件list
3. 遍历文件list,逐个文件进行切片
For(file:list)
对file从0偏移量开始切,每128M构成一个切片
比如a.txt(200M),就会切成 a.txt0-128M,a.txt128M-256M
b.txt 切成1个 b.txt 0-80M
如果要处理的数据是大量的小文件???,使用上述切片机制导致大量的切片,但是每个切片非常小,导致map task进程多,但数据量很小,效率很低。
解决:将多个小文件划分为1和切片,自定义inputfoemat子类,重写split
Mapreduce自带实现类:combinefileinputformat
Yarn
框架和使用场景
Resourcemanager 主节点master 只需要1个来工作
Nodemanager 从节点 根据集群规模可以有很多个
心跳通信?
1. yarn只负责资源的分配,不参与job具体的运行机制
2. mapreduce有一个进程mrappmaster来负责程序的运行流程控制
3. yarn可以为各种应用程序提供资源服务(类似于操作系统平台)
4. 可以把各种分布式框架整合到hadoop集群

















 7721
7721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









