



 本文深入剖析Python中的编码原理,包括Python 2.x与3.x版本之间的差异、字符串编码处理方式的不同,以及Unicode与UTF-8编码的使用场景。通过实例演示如何正确处理不同编码的字符串,避免常见的编码错误。
本文深入剖析Python中的编码原理,包括Python 2.x与3.x版本之间的差异、字符串编码处理方式的不同,以及Unicode与UTF-8编码的使用场景。通过实例演示如何正确处理不同编码的字符串,避免常见的编码错误。
说起python编码,真是句句心酸。万幸的是,终于梳理清楚了。作为一个共产主义者,一定要分享给大家。如果你还在因为编码而头痛,那么赶紧跟着我咱们一起来揭开py编码的真相吧!

什么是编码?
计算机运行一个程序/软件的核心组件可以简单地分成三部分:硬盘,内存,cpu。毫无疑问,三者都是以基于二进制的方式工作的。一个软件本质就是一系列文件,下载软件指的就是将这些文件的数据以二进制形式写入磁盘以便永久保存,而当软件需要运行时,则需要从硬盘将与该软件相关的二进制数据读入到内存中,最后CPU又从内存中读取二进制数据解析成CPU指令并运行,此时我们看到的结果就是一个软件运行起来了。
让我们以文本编辑器,比如word,notepad++等软件为例,当文本编辑器运行时,该软件本身肯定是以二进制数字的形式存放在内存中的,而当我们使用文本编辑器时,我们则可以输入人类认识的字符(英文字母,汉字,日文等),这些输入的字符属于文本编辑器要处理的数据,因而在被文本编辑器接收后是先放在内存中的,而内存中保存数据全都是二进制的数字形式,这就就要求文本编辑器帮助我们完成把人类认识的字符翻译(编码)成内存认识的二进制数字,要完成这个翻译的过程必须事先准备好一个翻译的标准,这个标准称为字符编码表,表内明确地规定了一个字符唯一对应一个数字。
编码的历史
我们熟知的unicode,utf8,GBK等编码方式都是这样的一张张对应表,可是为什么需要这么多表呢,不是有一张明文对应二进制数字的表就够用了吗?讲到这就不得不提一下编码的历史。
众所周知,计算机起源于美国,英文只有26个字符,算上其他所有特殊符号也不会超过128个。字节是计算机的基本储存单位,一个字节(bytes)包括八个比特位(bit),能够表示出256个二进制数字,所以美国人在这里只是用到了一个字节的前七位即127个数字来对应了127个具体字符,而这张对应表就是ASCII码字符编码表,简称ASCII表。后来为了能够让计算机识别拉丁文,就将一个字节的最高位也应用了,这样就多扩展出128个二进制数字来对应新的符号。这张对应表因为是在ASCII表的基础上扩展的最高位,因此称为扩展ASCII表。到此位置,一个字节能表示的256个二进制数字都有了特殊的符号对应。
但是,当计算机发展到东亚国家后,问题又出现了,像中文,韩文,日文等符号也需要在计算机上显示。可是一个字节已经被西方国家占满了。于是,我中华民族自己重写一张对应表,直接生猛地将扩展的第八位对应拉丁文全部删掉,规定一个小于127的字符的意义与原来相同,即支持ASCII码表,但两个大于127的字符连在一起时,就表示一个汉字,这样就可以将几千个汉字对应一个个二进制数了。而这种编码方式就是GB2312,也称为中文扩展ASCII码表。再后来,我们为了对应更多的汉字规定只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。这样能多出几万个二进制数字,就算甲骨文也能够用了。而这次扩展的编码方式称为GBK标准。当然,GBK标准下,一个像”苑”这样的中文符号,必须占两个字节才能存储显示。
与此同时,其它国家也都开发出一套编码方式,即本国文字符号和二进制数字的对应表。而国家彼此间的编码方式是互不支持的,这会导致很多问题。于是ISO国际化标准组织为了统一编码,统计了世界上所有国家的字符,开发出了一张万国码字符表,用两个字节即六万多个二进制数字来对应。这就是Unicode编码方式。这样,每个国家都使用这套编码方式就再也不会有计算机的编码问题了。Unicode的编码特点是对于任意一个字符,都需要两个字节来存储。这对于美国人而言无异于吃上了世界的大锅饭,也就是说,如果用ASCII码表,明明一个字节就可以存储的字符现在为了兼容其他语言而需要两个字节了,比如字母I,本可以用01001001来存储,现在要用Unicode只能是00000000 01001001存储,而这将导致大量的空间被浪费掉。基于此,美国人创建了utf8编码,而utf8编码是一种针对Unicode的可变长字符编码方式,根据具体不同的字符计算出需要的字节,对于ASCII码范围的字符,就用一个字节,而且符号与数字的对应也是一致的,所以说utf8是兼容ASCII码表的。但是对于中文,一般是用三个字节存储的。
Unicode与Utf8
由于Unicode具有更好的包容性,可以与其它编码方式进行任意映射,即Unicode编码的数据可以很容易转换成utf8编码下的字节数据,也可以很方便转换成GBK编码下的字节数据。所以在内存中Unicode是有更好的编码方案。但内存中的数据无法永久保存,内存中的数据只有两个去向,一个是基于网络传输,另外一个就是存放到硬盘上。无论网络还是硬盘也都是以二进制的形式发送数据的。内存的特性与功能决定了内存中使用Unicode编码更好,但基于网络传输或存放到硬盘上需要重视空间和流量问题,因此需要将Unicode二进制数转换成utf8或者GBK的二进制数据。而utf-8计算带来的延迟此时是可以忽略不计的,因为计算带来的延迟要远远低于网络I/O或硬盘I/O带来的延迟。简言之,Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
python解释器
python解释器本质上和notepad++等编辑器一样,都是一个软件,python解释器的功能是可以运行python程序,这中间主要分为两个过程:
(1)存储在磁盘上的程序一定是按某种编码保存的,比如utf8,GBK等。解释器首先需要将这些二进制数据按着对应的编码方式解码成Uniocde二进制数存到内存中。
(2)解释器通过操作系统调用CPU来执行存在内存的中的指令代码。
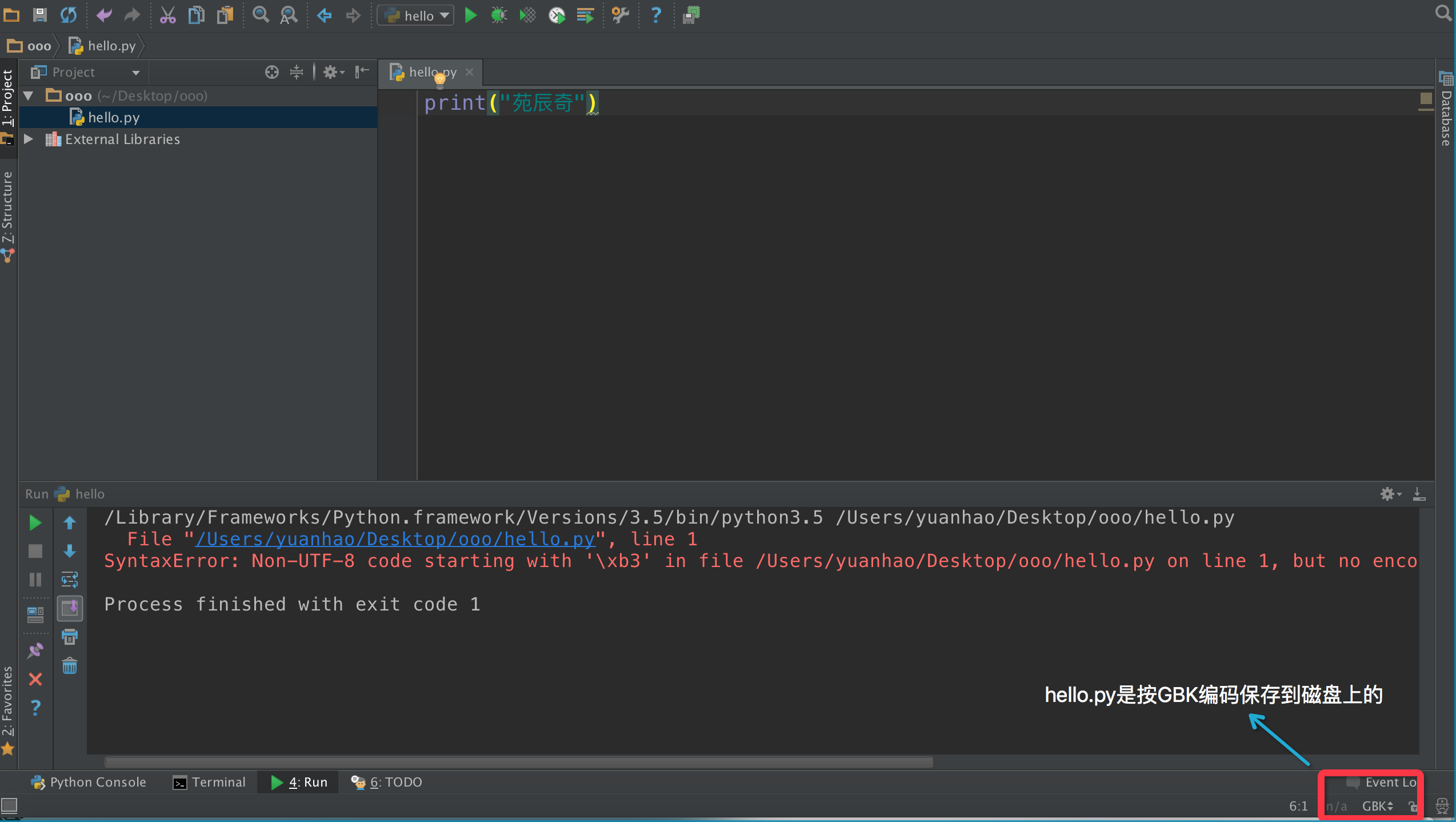
python2.0版本解释器默认的编解码方式是ASCII码,而python3.0版本则是utf8。对于步骤一,如果解码方式和编码方式不对应,一定会出现报错或者乱码的现象。如图所示,比如用GBK编码保存的程序,py3解释器按utf8去解码,报错。解决这个问题,可以在程序第一行加上:
|
1
|
#coding:GBK
|
这是再告诉解释器不要按默认的utf8去解码了,而是用指定的GBK去解。因为python解释器是逐行解释的,所以第一句解释完,解释器就会更换自己的解码方式。print(“苑辰奇”)这句代码如果是按utf8保存的,py3解释器就直接可以运行了,但是py2解释器因为默认的是ASCII码,用py2解释器去运行就会报错,解决办法是同样的道理,在首行声明一句 #coding:utf8即可。
字符串编码
解释器步骤一都是关于文件编码的,但当代码被执行的过程中,会涉及到字符串编码和解码。这个问题在py2和py3中是有所区别的。
py2的字符串编码:
python2.0版本中有两种字符串类型:str和unicode。
#coding:utf8 s="老男孩" print repr(s) #'\xe8\x80\x81\xe7\x94\xb7\xe5\xad\xa9' print type(s) #<type 'str'>
这是一个简单的赋值操作,执行时会申请一块内存空间存储数据,这种情况下存储的是utf8编码后的bytes字节数据(repr方法可以显示存储内容),数据类型名称是str。
#coding:utf8 s=u"老男孩" print repr(s) # u'\u8001\u7537\u5b69' print type(s) # <type 'unicode'>
如果字符串加一个前缀u,则存到内存中的数据是Unicode的十六进制的字节数据,数据类型名称为unicode。那unicode的字符串和具体编码(utf8,GBK)的字节串是否可以相互转换呢?当然是可以,这里是可以通过字符串的encode(编码)及decode(解码)进行转换的。

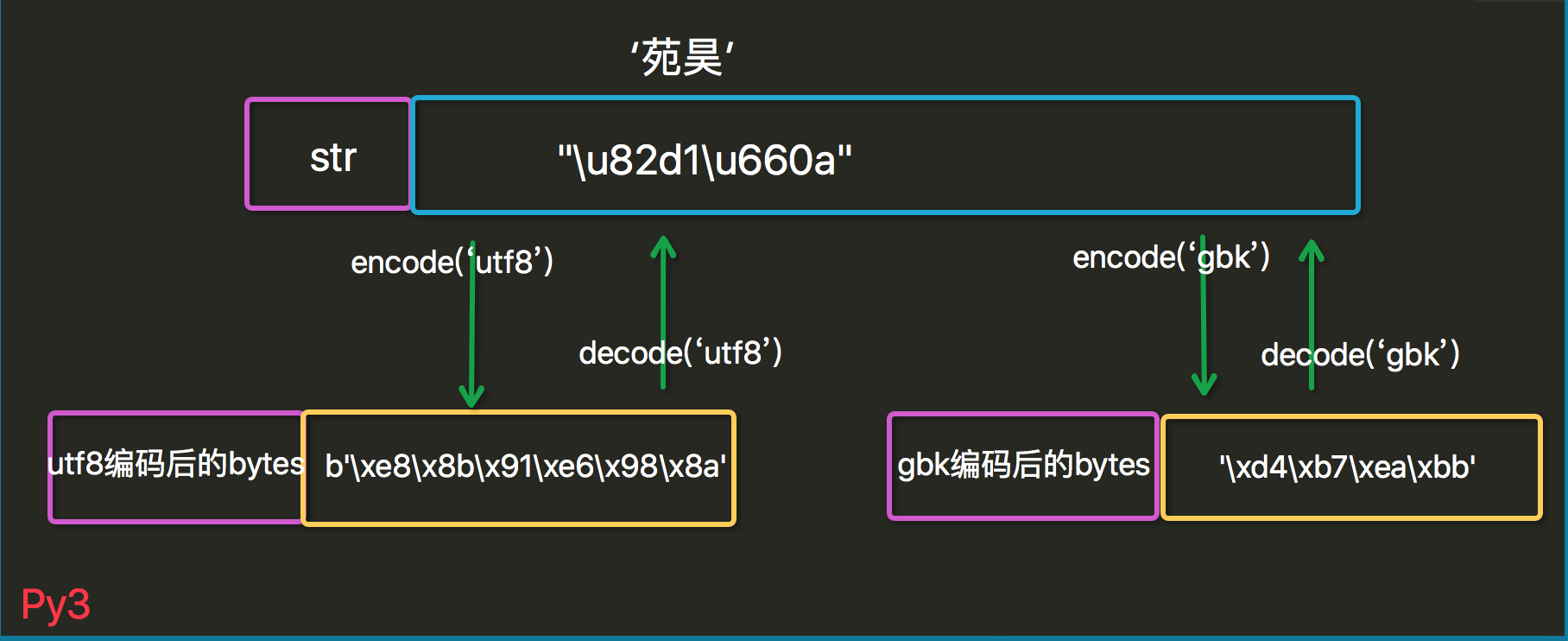
#coding:utf8 s=u"老男孩" sb1=s.encode("utf8") # 对uniocde数据按utf8编码成字节数据 sb2=s.encode("gbk") # 对uniocde数据按gbk编码成字节数据 print repr(sb1) # '\xe8\x80\x81\xe7\x94\xb7\xe5\xad\xa9' print repr(sb2) # '\xc0\xcf\xc4\xd0\xba\xa2' su1=sb1.decode("utf8") su2=sb2.decode("gbk") print repr(su1) # u'\u8001\u7537\u5b69' print repr(su2) # u'\u8001\u7537\u5b69'
对应转换图:

py3的字符串编码:
python3 renamed the unicode type to str ,the old str type has been replaced by bytes.py3也有两种数据类型:str和bytes; str类型存unicode数据,bytse类型存bytes数据,与py2比只是换了一下数据类型名称而已。
#coding:utf8 s="老男孩" # s存储的是unicode十六进制数据 print(type(s)) #<class 'str'> sb1=s.encode("utf8") sb2=s.encode("GBK") print(sb1) #b'\xe8\x80\x81\xe7\x94\xb7\xe5\xad\xa9' print(sb2) #b'\xc0\xcf\xc4\xd0\xba\xa2' su1=sb1.decode("utf8") # 如果按gbk解码则报错 su2=sb2.decode("gbk") # 如果按gbk解码则报错 print(su1) #老男孩 print(su2) #老男孩
对应转换图:
py2与py3的区别:
py2字符编码最大的特点是混用子节数据和unicode数据:
例1:
py2执行代码:
#coding:utf8 print (u"hello"+"yuan") #print (u'苑昊'+'最帅') #UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 # in position 0: ordinal not in range(128)
Python 2 悄悄掩盖掉了 byte 到 unicode 的转换,只要数据全部是 ASCII 的话,所有的转换都是正确的,一旦一个非 ASCII 字符偷偷进入你的程序,那么默认的解码将会失效,从而造成 UnicodeDecodeError 的错误。py2编码让程序在处理 ASCII 的时候更加简单。你复出的代价就是在处理非 ASCII 的时候将会失败。
py3执行:
print(b'alvin'+'yuan')#字节串和unicode连接 py3:报错 can't concat bytes to str
例2:
py2中执行代码:
#coding:utf8 s="苑辰奇" print(s) #苑辰奇
其中,s是一个utf8编码后的字节数据,打印s,却显示了明文,这是因为py2讲子节数据莫名地转成了unicode数据打印显示了。
在py3中没有这种暗转换,打印什么就是什么。
#coding:utf8 s="苑辰奇".encode("utf8") print(s) # b'\xe8\x8b\x91\xe8\xbe\xb0\xe5\xa5\x87'
所以,Python 3 最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分,不再会对bytes字节串进行自动解码。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
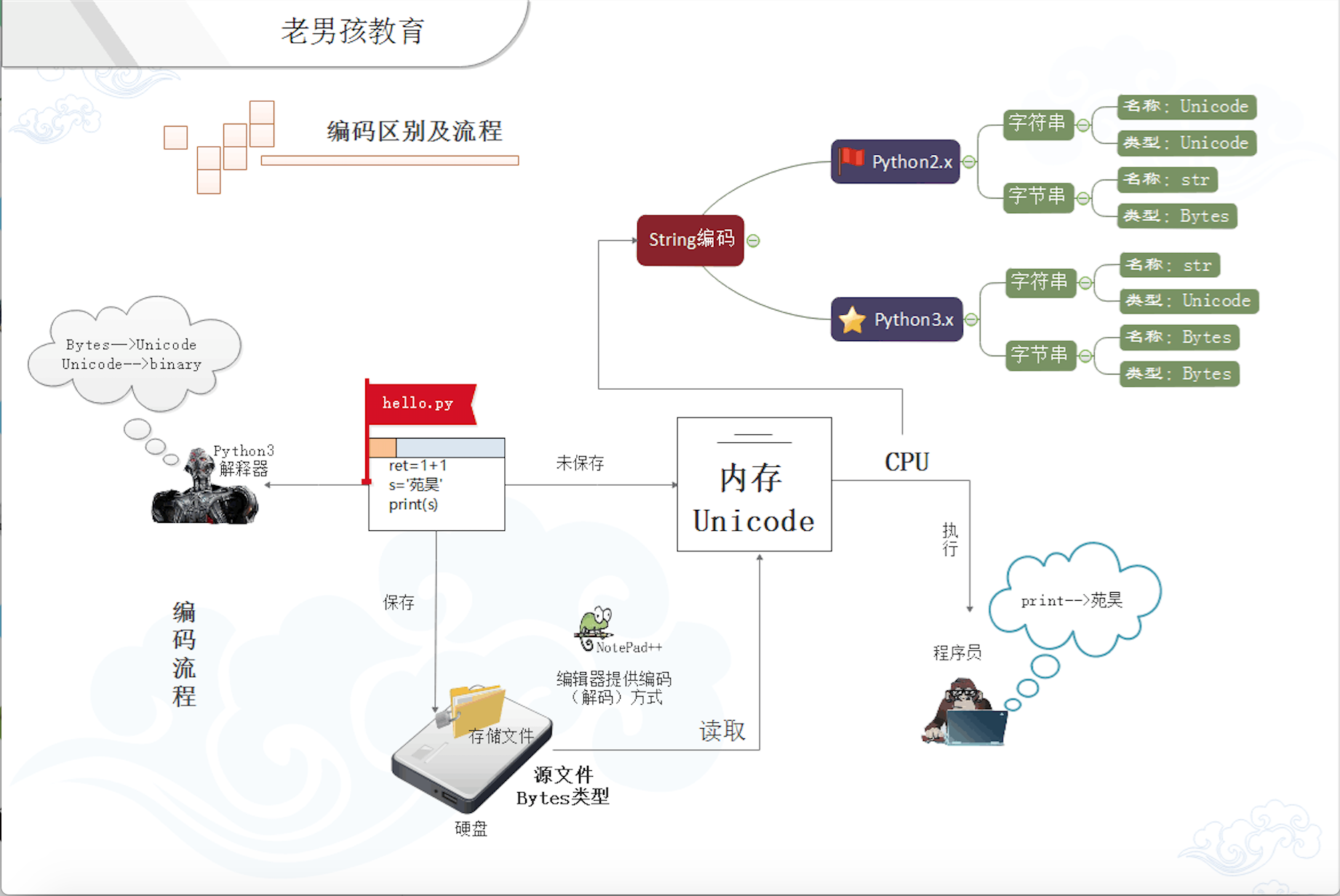
最后,我们通过一个图来描述整个解释器编码解码的全过程:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









