



这里有最专业的正则表达式详解:http://www.jb51.net/tools/zhengze.html
第一部分 如何去利用正则表达式描述一个字符串模式
你通常会如何去描述一个字符串模式呢
最常见的是:
以....开头的
以....结尾的
例如你构造文件名的时候用positive1.....positive100来表示100个属于正类的文档文件
那么首先介绍的就是两个很重要的符号:
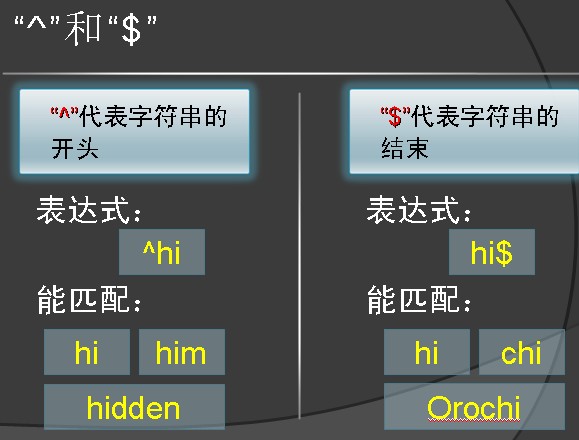
那么^hi$得到的结果是什么呢,是的,只能是hi
第二种非常重要的匹配是....的类型
例如“positive1.....positive100”就是positive开头+数字结尾
我们可以使用一个集合来简单地限制...的类型

所以上面的例子应该是^positive[0-10000]$
这里采用的是集合的形式,但其实可以利用一些元字符来代替:

那么如果我们碰见的是一个非常变态的人,他的概念里只有二进制,所以他是这么设计文件名的:
positive10101, positive0101, positive10111....即后面的数字用一个二进制表示
我们可以这么来表示:positive开头,结尾的是一个由1或0的任意多个组合而成的字符串
1或0可以用集合[01]来表示,那么如何来表示重复呢
这里要介绍定义重复的符号:"+" and "*"


所以,positive开头,结尾的是一个由1或0的任意多个组合而成的字符串可以被表示为:^positive[01]+$
当然,也存在限制重复个数的符号:

读到这里,或许你会发现可读性有点不好,为什么,因为就像公式,没加(),总是觉得读起来费劲
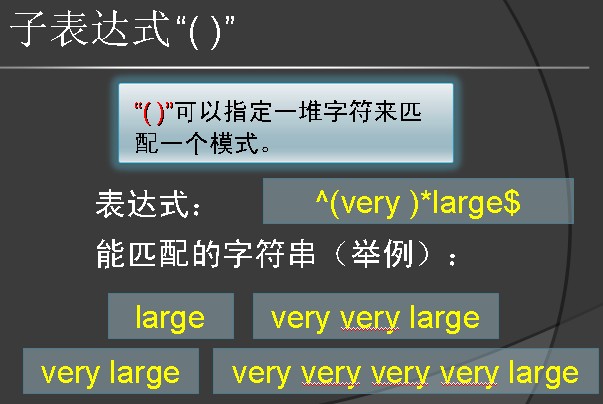
那么其实上面的模式规则都是默认的与操作,是不是?
其实规则肯定也可以实现或这个操作的,这利用分支符号来实现:

接下来介绍如果模式中出现了需要转义的符号如何做:

第二部分 如何在Java中使用正则表达式来处理文本数
首先我们检查一下是否学习好了前面的内容:
如下面的几个字符串:a98b c0912d c10b a12345678d ab
我们发现是字母和数字的任意组合,但要保证开头为数字,如何描述呢
^[a-z]([a-z]*|[0-9]*)*
我们仔细分析上面五个字符串,可以看出它们有一个共同特征,就是第一个字符必须是'a'或'c',最后一个字符必须是'b'或'd',而中间的字符是任意多个数字组成(包括0个数字)。因此,我们可以将这五个字符串的共同特点抽象出来,这就产生了一个正则表达式:[ac]\\d*[bd]。而根据这个正则表达式,我们可以写出无穷多个满足条件的字符串。
在Java中使用正则表达式的方法非常多,最简单的就是和字符串一起使用。在String中有四个方法可以使用正则表达式,它们是matches、split、replaceAll和replaceFirst。
一、matches方法
matches方法可以判断当前的字符串是否匹配给定的正则表达式。如果匹配,返回true,否则,返回false。
matches方法的定义如下:public boolean matches(String regex)
如上面给出的正则表达式我们可以用如下程序验证。
String[] ss = new String[]{"a98b", "c0912d", "c10b", "a12345678d", "ab"};
for(String s: ss)
System.out.println(s.matches("[ac]\\d*[bd]"));
输出结果:truetruetruetruetrue
下面简单解释一下这个正则表达式的含义。如果我们学过编译原理的词法分析,就会很容易理解上面的正则表达式(因为正则表达式的表示方法和词法分析中的表达式类似)。如在 [...]中的相当于或"|",如[abcd]相当于a|b|c|d,也就是a或b或c或d。如上面的正则表达式的开头部分是[ac],就代表着字符串的开头只能是a或c。[bd]表达字符串结尾只能是b或d。而中间的\d表达0-9的数字,由于\在正则表达式中有特殊含义,所以用\\来表示\。而*表示有0或无穷多个(这在词法分析中叫*闭包),由于*跟在\d后面,因此表达有0或无穷多个数字。
二、split方法split方法使用正则表达式来分割字符串,并以String数组的形式返回分割结果。
split有两种重载形式,它们定义如下:public String[] split(String regex)
public String[] split(String regex, int limit)
如下面的代码将使用split的第一种重载形式来分割HTTP请求头的第一行,
代码如下:String s = "GET /index.html HTTP/1.1";
String ss[] = s.split(" +");%按照空格来分割
for(String str: ss)
System.out.println(str);
输出结果:
GET
/index.html
HTTP/1.1
在使用split的第一种重载形式时应注意,如果分割后的字符串最后有空串,将被忽略。如使用正则表达式\d来分割字符串a0b1c3456时,得到的数组的长度为3,而不是7。
在split的第二种重载形式中有一个limit参数,要分三种情况讨论:
1. 大于0: 如limit的值为n,那么将对正则表达式使用n-1次,
下面的代码:
String s = "a0b1c3456";
String ss[] = s.split("\\d", 3);
for(String str: ss)
System.out.println(str);
输出结果:abc3456
从输出结果可以看出,程序只对" a0b1c3456"使用了两次正则表达式,也就是在少扫描完字符'1'后,不管后面有没有满足条件的字符串,都将后面的字符串作为一个整体来作为返回数组的最后一个值。
2. 小于0: 不忽略结尾的空串。也就是上面的例子返回数组的长度应该是7,而不是3。
3. 等于0:这是默认值,相当于split的第一种重载形式。
三、replaceAll 和 replaceFirst方法为两个方法的定义如下:
public String replaceAll(String regex, String replacement)
public String replaceFirst(String regex, String replacement)
这两个方法用replacement替换当前字符串中和regex匹配的字符串。使用方法很简单,这里不再详述,感兴趣的读者可以参考相关的文档。
对于Java中正则表达式的详细内容,请参考JDK文档。
==========================================================
想批量从一批格式相同的TXT文档里选择出两个特定字符串之间的内容,如下: XXXXXXX Reference: 1XXX 2XXX ..... About the author, ..... ....

















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









