






 本文深入探讨CUDA编程的基础概念,包括设备查询、并行编程模型、线程协作机制、内存管理技术如共享内存、常量内存及纹理内存的应用,以及原子性和流的概念。通过详细解释和示例代码帮助读者掌握高效利用GPU资源的方法。
本文深入探讨CUDA编程的基础概念,包括设备查询、并行编程模型、线程协作机制、内存管理技术如共享内存、常量内存及纹理内存的应用,以及原子性和流的概念。通过详细解释和示例代码帮助读者掌握高效利用GPU资源的方法。
将cpu及系统的内存称为主机, gpu及内存称为设备。
3.2、查询设备
1 int count; 2 3 cudaGetDeviceCount ( &count ); // 获取设备数目 4 5 6 7 int i; 8 9 cudaDeviceProp prop; 10 11 for( i = 0; i < count; i ++ ) { 12 13 cudaGetDeviceProperties( &prop, i ); //遍历设备信息 14 15 } 16 17 18 19 cudaChooseDevice( &dev, &prop ); //选择最匹配prop属性的设备
4、cuda并行编程
4.1、kernel<<<N, 1>>>
尖括号中内容是告诉运行时如何启动核函数。
第一个参数表示在执行核函数时使用的并行线程快的数量。第二个参数表示cuda运行时在每个线程块中创建的线程数。
4.2、例子add 函数:
1 __global__ void add ( int *a, int *b, int *c ) { 2 3 int tid = blockIdx.x; 4 5 if ( tid < N ) 6 7 c[ tid ] = a[ tid ] + b [ tid ]; 8 9 }
blockIdx.x 为当前执行设备代码的线程块的索引。
事实上, cuda支持二维的线程块数组。对于二维空间的计算问题,例如矩阵数学运算或者图像处理,使用二维索引往往会带来很大的比阿尼, 因为它可以避免将线性索引转换为矩形索引。在某些情况下,使用二维索引比使用一维索引要更为方便。
在线程块并行执行时,将用相应的线程块索引来替换blockIdx.x。
即: 将 int tid = blockIdx.x 替换为 int tid = 0(或其他索引值, 如 N-1)
判断 tid < N 核函数中都是这么假设的(线程块索引为[1... N-1]), 但是可能会发生人为破坏代码, 为了防止内存非法访问所以要进行判断
注意:启动线程块数组时, 数组每一维的最大数值不能超过65635, 这是硬件限制。
4.2.2 Julia 集
? 画图 offset * 4 + 0|1|2|3
结果
双重循环时定义 dim3 grid(DIM, DIM); 将grid 传入kernel函数。
虽然我们实际上只需要二维线程格, 但是cuda运行时仍然希望得到一个dim3类型的参数,只不过最后一维的大小为1, 当仅用两个值来出书画dim3类型的变量时, cuda运行时将自动把第三维的大小指定为1。 目前NVIDIA并不支持3维的线程格。
声明为__device__的函数, 只能从其他__device__函数或者从__global__函数中调用它们。
总结:
GPU上启动的线程块集合称为一个线程格, 可以是一维也可以是二维的。核函数的每个副本都可以通过内置变脸blockIdx 来判断哪个线程块正在执行它。同样,可以通过内置变量gridDim来获取线程格的大小。
5、线程协作
5.1 目标
1、了解cuda c中的线程
2、了解不同线程之间的通信机制
3、了解并行执行线程的同步机制
5.2 并行线程块的分解
5.2.1 将实现方式由并行线程块改为并行线程时, 需要修改两个地方
1、add<<<N, 1>>>() 改为 add<<<1, N>>>() // 将n个线程块 改为 1个线程块 n个线程
2、int tid = blockIdx.x 改为 int tid = threadIdx.x; //只有1个线程块, 不需要线程块索引。
通常每个线程块不能超过512个线程
多个线程块并且每个线程块中包含了多个线程时
![]()
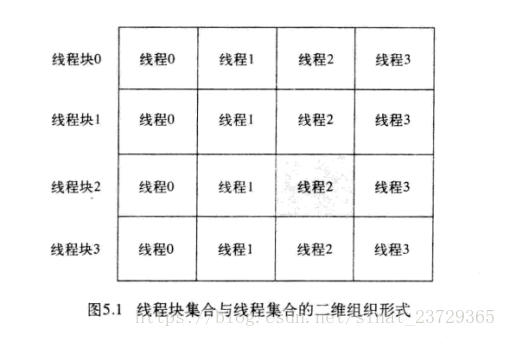
![]()
int tid = threadIdx.x + blockIdx.x * blockDim.x; // 因为线程块中线程为一维, 所以只要blockDim.x 即可 (线程块中线程支持二维和三维) blockDim 保存的是线程块中线程的值
设置每个线程块大小为固定值, 例如128:
add<<<(N + 127)/128, 128>>>()
当N不是128的整数倍时, 将启动过多的线程。所以在核函数中必须检查线程的偏移是否位于0-N之间。
if(tid < N)
c [ tid ] = a [ tid ] + b [ tid ];
因此, 当索引越过数组的边界时, 例如当启动的并行线程数量不是128的整数倍时就会出现这种情况, 那么核函数将自动停止执行计算。 更重要的是, 核函数不会对越过数组边界的内存进行读取或者写入。
对于主机代码来说是“全局的”变量, 设备代码要调用时要当参数传入。
1 dim3 blocks(DIM/16, DIM/16) //线程块 2 3 dim3 threads(16, 16) //线程
如何为48 * 32 的像素的图像, 线程块和线程的关系图如下:
![]()
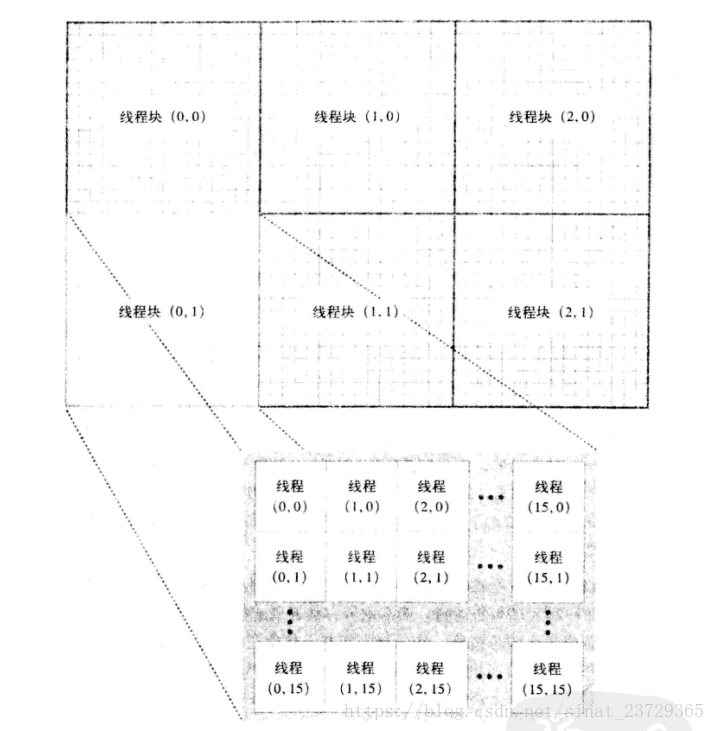
![]()
求出线程的偏移量:
1 int x = threadIdx.x + blockIdx.x * blockDim.x; 2 3 int y = threadIdx.y + blockIdx.y * blockDim.y; 4 5 int offset = x + y * blockDim.x * blockIdx.x;
5.3 共享内存和同步
cuda c支持共享内存。可以将cuda c的关键字__share__添加到变量生命中, 这将使这个 变量驻留在共享内存中。
共享内存缓冲区驻留在物理GPU上, 而不是驻留在GPU之外的系统内存中。 因此, 在访问共享内存时的延迟要远远低于访问普通缓冲区的延迟
归约运算(点积运算):
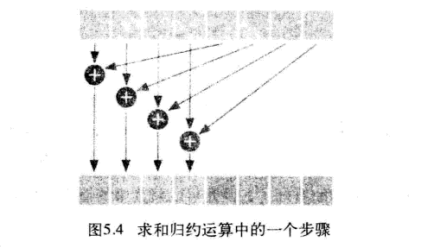
![]()
GPU 大规模并行机器在执行最后的归约步骤是, 通常会浪费计算资源, 因为此时的数据集往往非常小。 例如, 当时用480个数学处理单元将32个数值相加时,将难以充分使用每一个数学处理单元。 因此, 将执行控制返回给主机, 并且有cpu来完成最后一加法步骤。
当一段非常短的代码选择32个线程块并且每个线程块包含256个线程,
有N个元素, const int blocksPerGrid = imin( 32, (N + threadsPerBlock - 1) / threadsPerBlock );
线程发散:某些线程需要执行一条指令, 而其他线程不需要执行时。
正常环境中, 发散的分支只会使得某些线程处于空闲状态, 而其他线程将执行分支中的代码。
__syncthreads() 不能写入发散分支中。
但在__syncthreads() 情况中, 线程发散造成的结果有些糟糕。 cuda 架构将确保, 除非线程块中每个线程都执行了__syncthreads(), 否则没有任何线程能执行__syncthreads()之后的指令。遗憾的是, 如果__syncthreads() 位于发散分支中, 那么一些线程将永远都无法执行__syncthreads()。 一次, 犹豫要确保在每个线程执行完__syncthreads()后才能执行后面的语句, 因此硬件将使致谢线程保持等待。 一直等下去。
如果线程中需要读取共享内存中的数据, 要确保之前对共享内存的写入操作均已经完成。 此时, 在读取数据前使用__syncthreads(), 确保线程块中所有对共享内存的写入操作完成。
6、常量内存与事件
6.1 本章目标
1、了解如何在cuda c中使用常量内存。
2、了解常量内存的性能特征。
3、学习如何使用cuda事件来测量应用程序的性能。
6.2 常量内存
由于在图行处理器上包含了非常多的数学逻辑单元(alu), 因此有时输入数据的速率甚至无法维持如此高的计算速率。 因此, 有必要研究一些手段来减少计算问题时的内存通信量。
cuda c程序中可以使用全局内存和共享内存, 还有一种常量内存。
常量内存用于保存在核函数执行期间不会发生变化的数据。 NVIDIA硬件提供了64KB的常量内存, 并且对常量内存采取了不同于标准全局内存的处理方式。在某些情况下, 用常量内存来替换全局内存能有效地减少内存带宽。
声明常量内存时, 要将这个声明修改为在常量内存中静态地分配空间。不能使用cudaMalloc() 和 cudaFree() , 而是在编译时为这个数组提价哦一个固定的大小。
将 Sphere *s;
修改为 __constant__ Sphere s[20];
cudaMemcpyToSymbol()会复制到常量内存中, cudeMemcpy()会复制到全局内存中。
线程束 :线程束是指一个包含32个线程的集合, 这个线程集合被“编织在一起”, 并且以“步调一致(Lockstep)”的形式执行。 在程序中的每一行,线程束中的每一个线程都将在不同的数据上执行相同的指令。
常量内存如何减少内存流量?
1、处理常量内存时, NVIDIA硬件将把单词内存读取操作广播到每个半线程束(Half-Wrarp)。在半线程束中包含了16个线程, 即线程束中线程数量的一半。如果在版相城束中的每个线程都从常量内存的相同地址上读取数据, 那么GPU只会产生一次读取请求并在随后将数据广播到每个线程。如果从常量内存中读取大量的数据, 那么这种方式产生的内存流量只是使用全局内存时的1/16(大约6%)。
(必须是从相同地址上读取数据, 如果是从不同地址读取的话, 则会变成串行命令, 需要16倍的时间来发出请求。但如果是从全局内存中读取则会同时发出命令)
2、读取常量内存时, 所节约的并不仅限于减少了94%的宽带。犹豫这块内存的内容是不会发生变化的, 因此硬件将主动把这个常量数据缓存在GPU上。在第一从常量内存的某个低智商读取后, 当其他半线程束请求同一个地址是, 那么将命中缓存, 这同样减少了额外的内存流量。
总结:
1、线程将在半线程束的广播中收到这个数据。
2、从常量内存缓存中收到数据。
6.3 使用时间来测量性能()
cuda事件是直接在GPU上实现的, 因此它们不适用于同事包含设备代码和主机代码的混合代码计时, 也就是说, 如果你试图通过cuda时间对核函数和设备内存复制之外的代码进行计时时, 将得到不可靠的结果
使用:
1 cudaEvent_t start, stop; 2 3 cudaEventCreate(&start); 4 5 cudaEventCreate(&stop); 6 7 cudaEventRecord( start, 0 ); 8 9 10 11 cudaEventRecord( stop, 0 ); 12 13 cudaEventSynchronize( stop); // 告诉运行阻塞后面的语句, 知道GPU执行到达stop时间。(执行异步函数时, GPU执行完之前, CPU会继续执行程序中的下一行代码。导致计时不正确) 14 15 float elapsedTime; 16 17 cudaEventElapsedTime(&elapsedTime, start, stop); //计算两个事件之间经历的时间, 单位为毫秒。 18 19 20 21 cudaEventDestroy(start); //用完销毁事件 22 23 cudaEventDestroy(stop);
7、纹理内存(Texture Memory)
1、了解纹理内存的性能特性
2、了解如何在cuda c中使用一维纹理内存
3、了解如何在cuda c中使用二维纹理内存
纹理内存为只读内存, 和常量内存类似的是, 同样缓存在芯片上
![]()
7.1 一维纹理内存
使用:
1、声明纹理内存
texture<float> texIn;
2、在GPU申请全局内存。
codaMalloc((void**)&data.dev_inSrc, imageSize);
3、将内存绑定到之前声明的纹理引用上。
cudaBindTexture(NULL, texIn, data.dev_inSrc, imageSize);
4、读取使用时
tex1Dfetch(texIn, top)
有in和out两个使用内存时, 不要复制内存, 通过标志 flag 来选择访问哪一块内存。
写入时仍然写入到全局内存中。
5、使用完清除与纹理的绑定
cudaUnbindTexture(texIn);
7.2 二维纹理内存
1、声明二维纹理
texture<float, 2> texIn;
2、在GPU申请全局内存。
codaMalloc((void**)&data.dev_inSrc, imageSize);
3、将内存绑定到之前声明的纹理引用上。
cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>(); //通道格式描述符, 为浮点描述符
cudaBindTexture2D( NULL, texIn, data.dev_inSrc, desc, DIM, DIM, sizeof(float)*DIM);
4、读取使用时
tex2D(texIn, x, y) //如果x 或 y小于0, 那么将返回0处的值;如果大于宽度, 将返回位于宽度处的值
5、使用完清除与纹理的绑定
cudaUnbindTexture(texIn);
如果使用纹理采样器( Texture Sampler) 自动执行的某种转换, 那么纹理内存还能带来额外的加速
9、原子性
当多个线程对同一地址同时进行读写操作时, 只有原子性操作才能得到真正的结果。
atomicAdd( addr, y)
将生成原子操作, 这个操作序列包括读取地址addr处的值, 将y增加到这个值, 以及将结果保存回地址addr。底层赢家将确保当执行这些操作时, 其他任何线程都不会读取或写入地址addr上值,这样就能确保得到预计的结果。
然而, 当核函数中只包含了非常少的计算工作, 当数千个线程尝试访问少量的内存位置时, 将发生大量的竞争。 为了确保递增操作的原子性, 对相同内存位置的操作都将被硬件串行化,这可能会导致保存未完成操作的队列非常长, 因此会抵消通过并行运行线程而获得的性能提升。
此时可以使用共享内存原子操作和全局内存原子操作的方法进行改善。
10、流(并行性)
1、了解如何分配页锁定(Page-Locked)类型的主机内存。
2、了解cuda流的概念。
3、了解如何使用cuda流来加速应用程序。
10.2、 页锁定主机内存
用cudaHostAlloc 函数分配的内存都需要分配物理内存。
缺点:这些内存不能交换到磁盘上, 与使用malloc调用相比, 系统将更快的耗尽内存。
优点:由于gpu知道内存的物理地址,因此可以通过“直接内存访问(Direct Memory Access DMA)”技术来在GPU和主机之间复制数据。当可分页内存进行复制时, cuda驱动程序仍然会通过DAM把数据传输给GPU。因此, 复制操作将执行两遍, 第一遍从可分页内存复制到一块“临时的”页锁定内存, 然后再从这个页锁定内存复制到GPU上。
这种差异会使页锁定主机内存的性能比标准可分页内存的性能要高大约2倍。
综合,一般仅对cudaMemcpy()调用的源内存或者目标内存, 才使用页锁定内存。
10.4 使用单个cuda流
10.5 使用多个cuda流
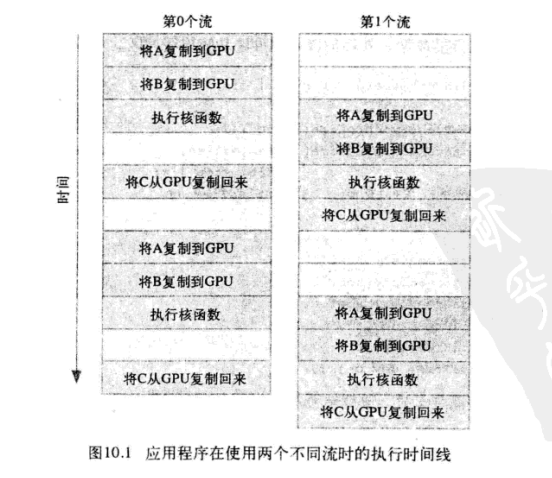
10.6 gpu的工作调度机制
![]()
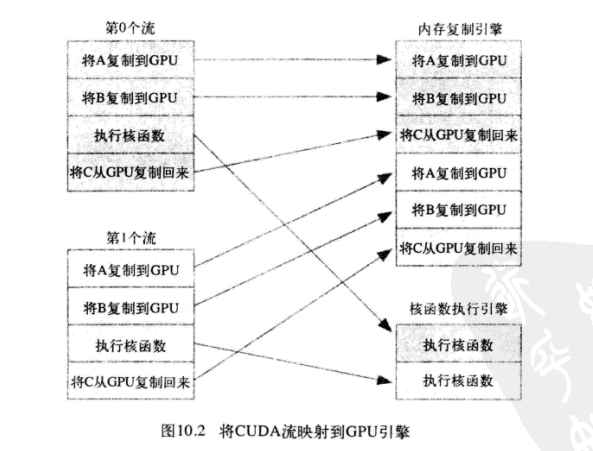
![]()
![]()
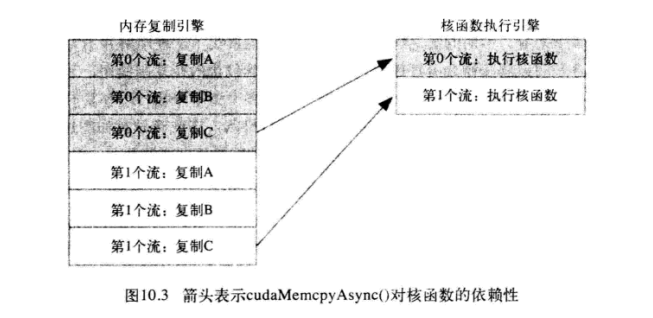
![]()
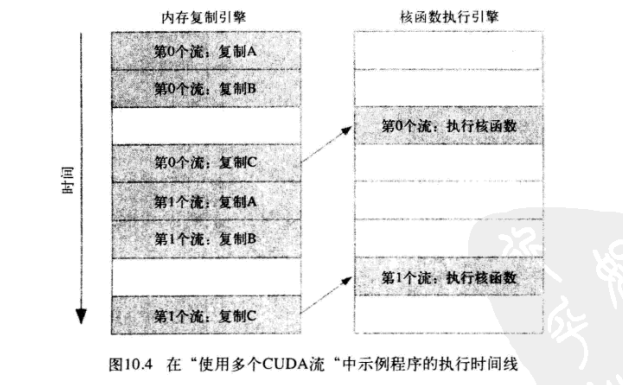
由于第0个流中将c复制回主机的操作要等待核函数执行完成, 因此第一个流中将a 和 b复制到GPU的操作虽然是完全独立的, 但却被阻塞了, 这是因为GPU引擎是按照指定的书序来执行工作。 这种情况很好得说明了为什么在程序中使用了两个流却无法获得加速的窘境。(gpu中流任务的执行顺序与代码中任务的先后顺序有关。)
更改后正确的顺序应该是:
![]()
注:
应为要通过cudaMemcpyAsync()对内存复制操作进行排序, 所以需要通过cudaHostAlloc()来分配主机内存。

















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









