



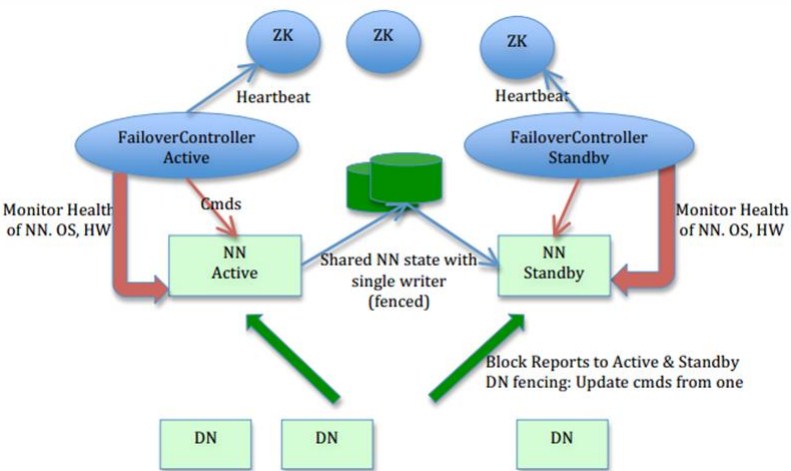
1. HDFS (2.0)架构:
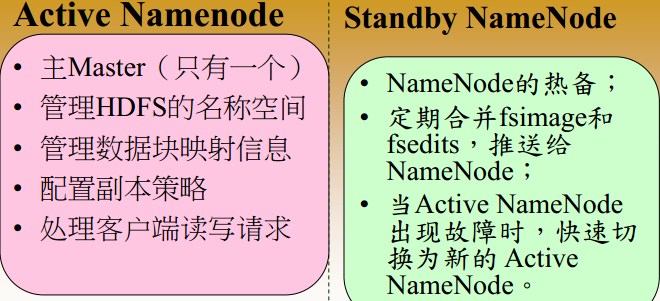
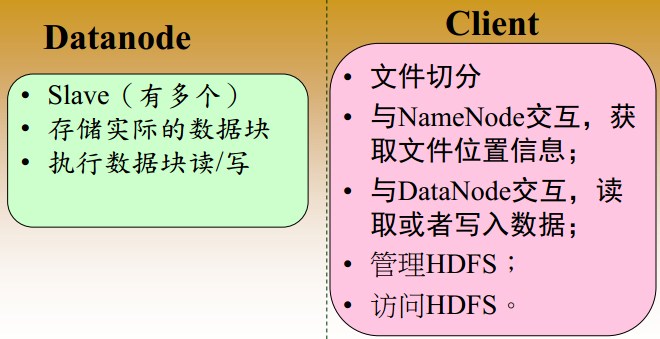
2. HDFS 设计思想:
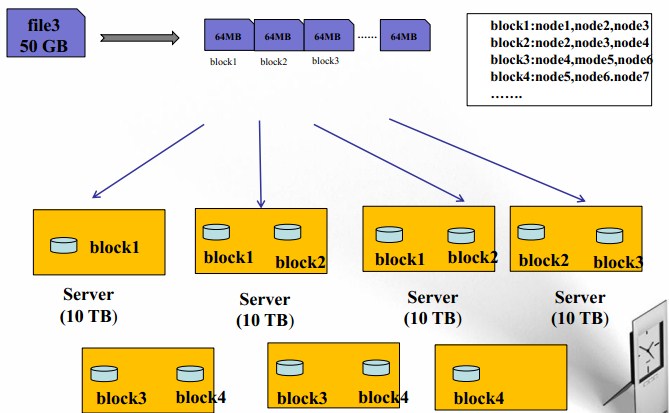
HDFS数据块(block):
- 文件被切分成固定大小的数据块
- 默认数据块大小为64MB,可配置
- 若文件大小不到64MB,则单独存成一个block
- 为何数据块如此之大
- 数据传输时间超过寻道时间(高吞吐率)
- 一个文件存储方式
- 按大小被切分成若干个block,存储到不同节点上
- 默认情况下每个block有三个副本
3. HDFS优缺点:
优点:
- 高容错性
- 数据自动保存多个副本
- 副本丢失后,自动恢复
- 适合批处理
- 移动计算而非数据
- 数据位置暴露给计算框架
- 适合大数据处理
- GB、TB、甚至PB级数据
- 百万规模以上的文件数量
- 10K+节点规模
- 流式文件访问
- 一次性写入,多次读取
- 保证数据一致性
- 可构建在廉价机器上
- 通过多副本提高可靠性
- 提供了容错和恢复机制
缺点:
- 低延迟数据访问
- 比如毫秒级
- 低延迟与高吞吐率
- 小文件存取
- 占用NameNode大量内存
- 寻道时间超过读取时间
- 并发写入、文件随机修改
- 一个文件只能有一个写者
- 仅支持append
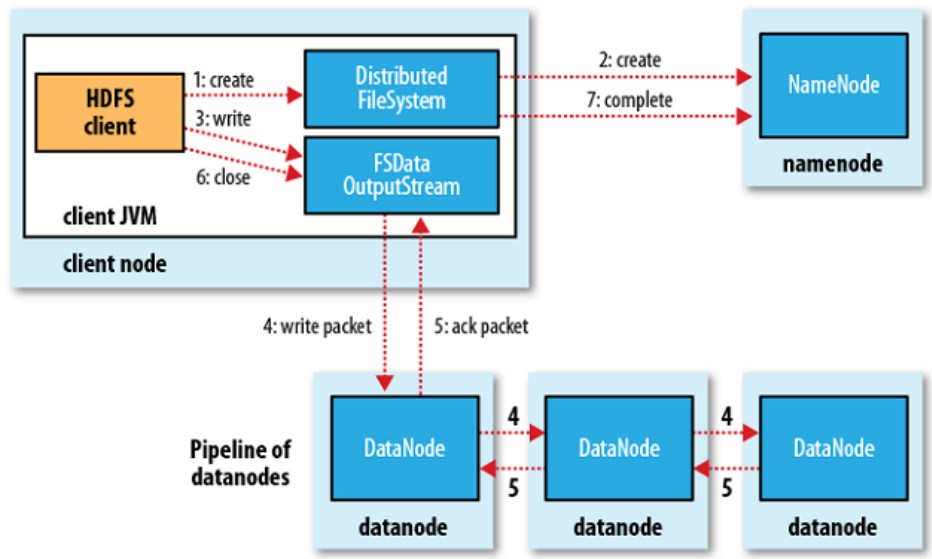
4. HDFS 写流程:
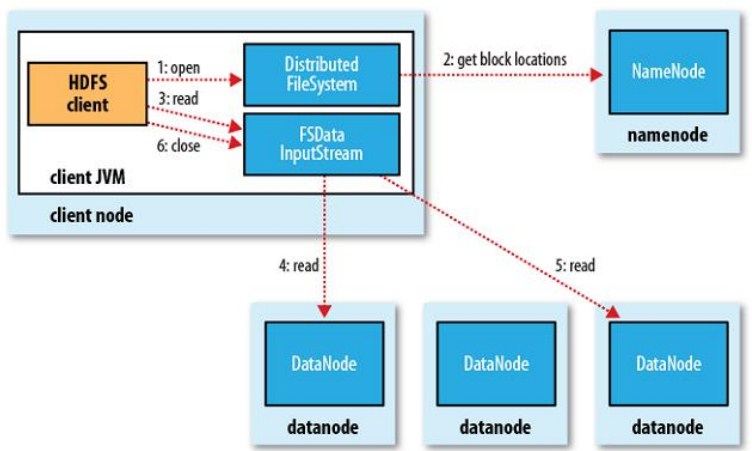
5. HDFS 读流程:
6. HDFS副本放置策略:
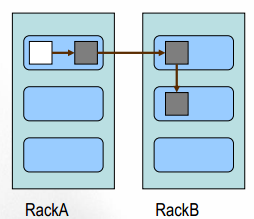
问题:
一个文件划分成多个block,每个block存多份,如何为每个block选择节点存储这几份数据?
Block副本放置策略:
- 副本1: 同Client的节点上
- 副本2: 不同机架中的节点上
- 副本3: 与第二个副本同一机架的另一个节点上
- 其他副本:随机挑选
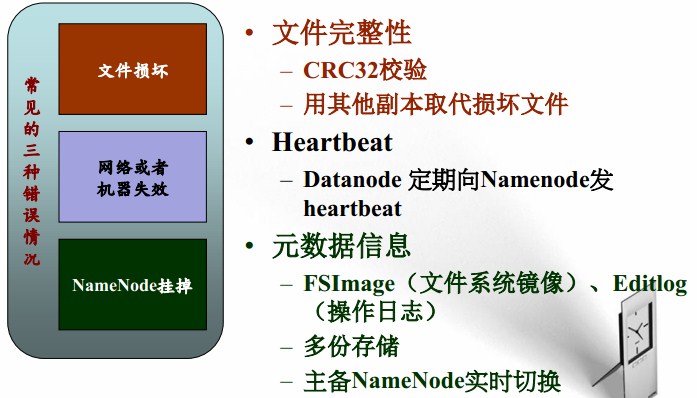
HDFS可靠性策略:
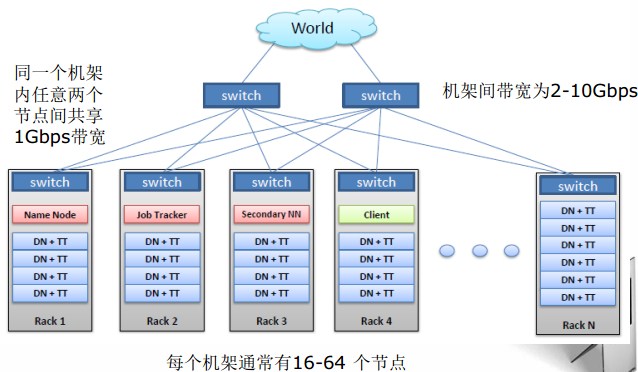
7. HDFS典型物理拓扑:

















 8547
8547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









