



 本文探讨了使用Python3.5访问特定chunked编码网站时出现的乱码问题,并通过调整请求头中的Accept-Encoding字段成功解决了该问题。
本文探讨了使用Python3.5访问特定chunked编码网站时出现的乱码问题,并通过调整请求头中的Accept-Encoding字段成功解决了该问题。
ython3.5,requests遇到链接 http://app.cnmo.com/android/233888/history.html,抓取出现乱码,发现是chunked编码的,指定编码也不行,自动检测到编码为None。
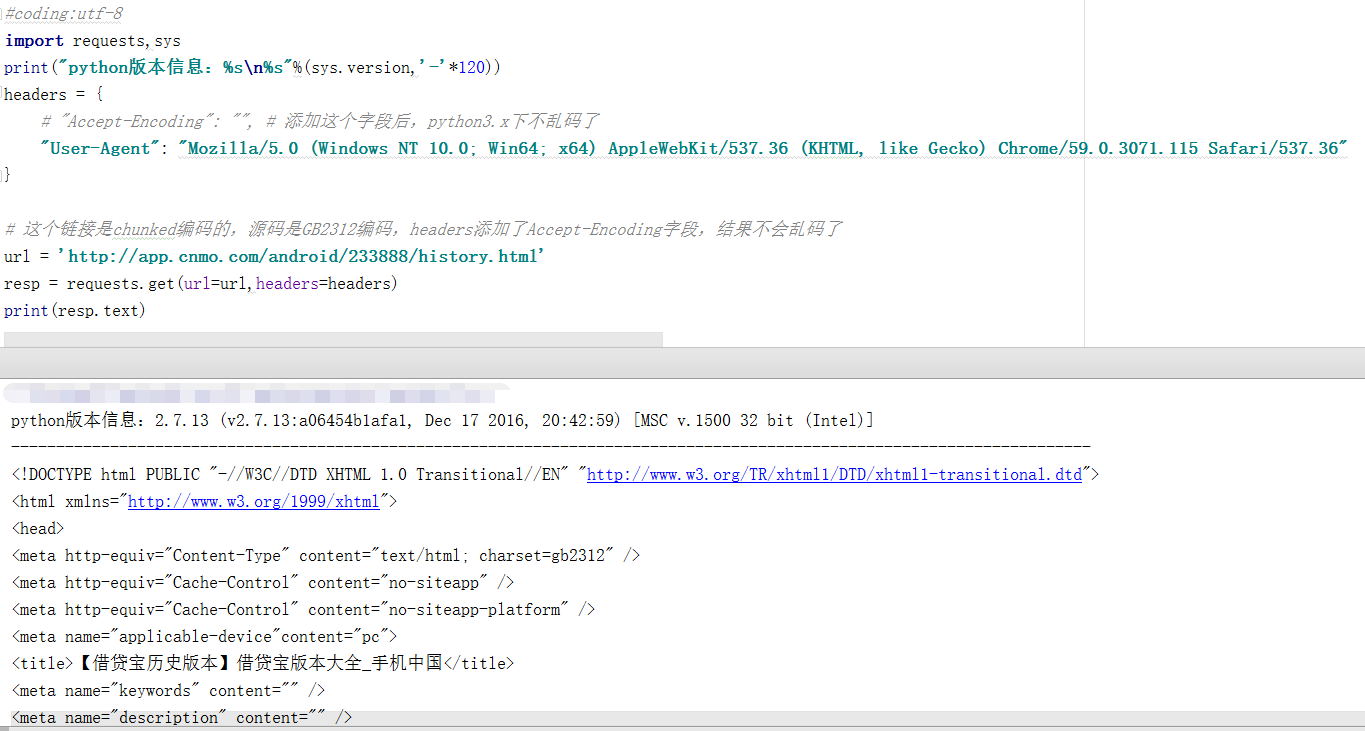
QQ群里问群友,群友用python2.x的,同样的代码,不乱码。我也切换python2.x验证,确实不出现乱码。
1 #coding:utf-8 2 import requests 3 headers = { 4 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36" 5 } 6 7 # 这个链接是chunked编码的,源码是GB2312编码,python3.x乱码,python2.x正常 8 url = 'http://app.cnmo.com/android/233888/history.html' 9 resp = requests.get(url=url,headers=headers) 0 print(resp.text)
python3.5.2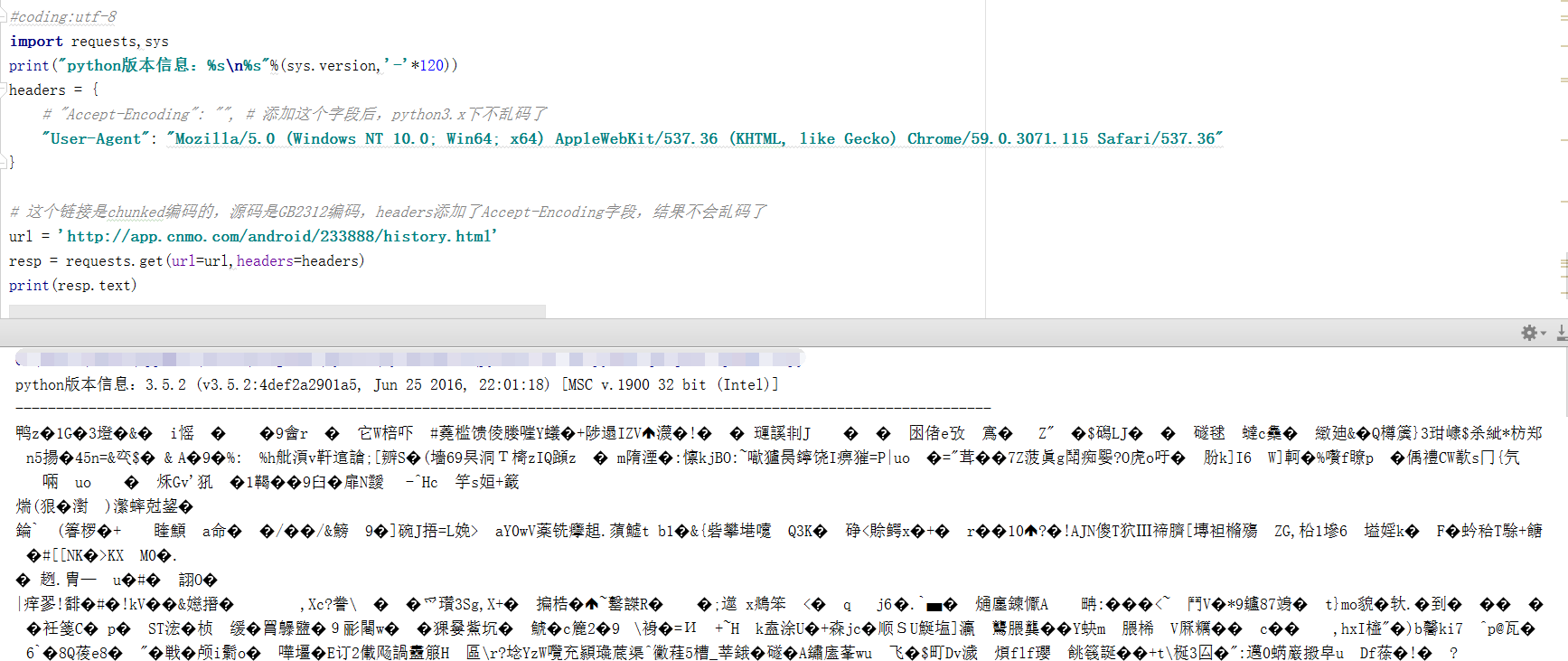
python2.7.13
这个问题百思不得其解,百度、谷歌、360、搜狗、必应,能搜的都搜一遍,还是没搞定。
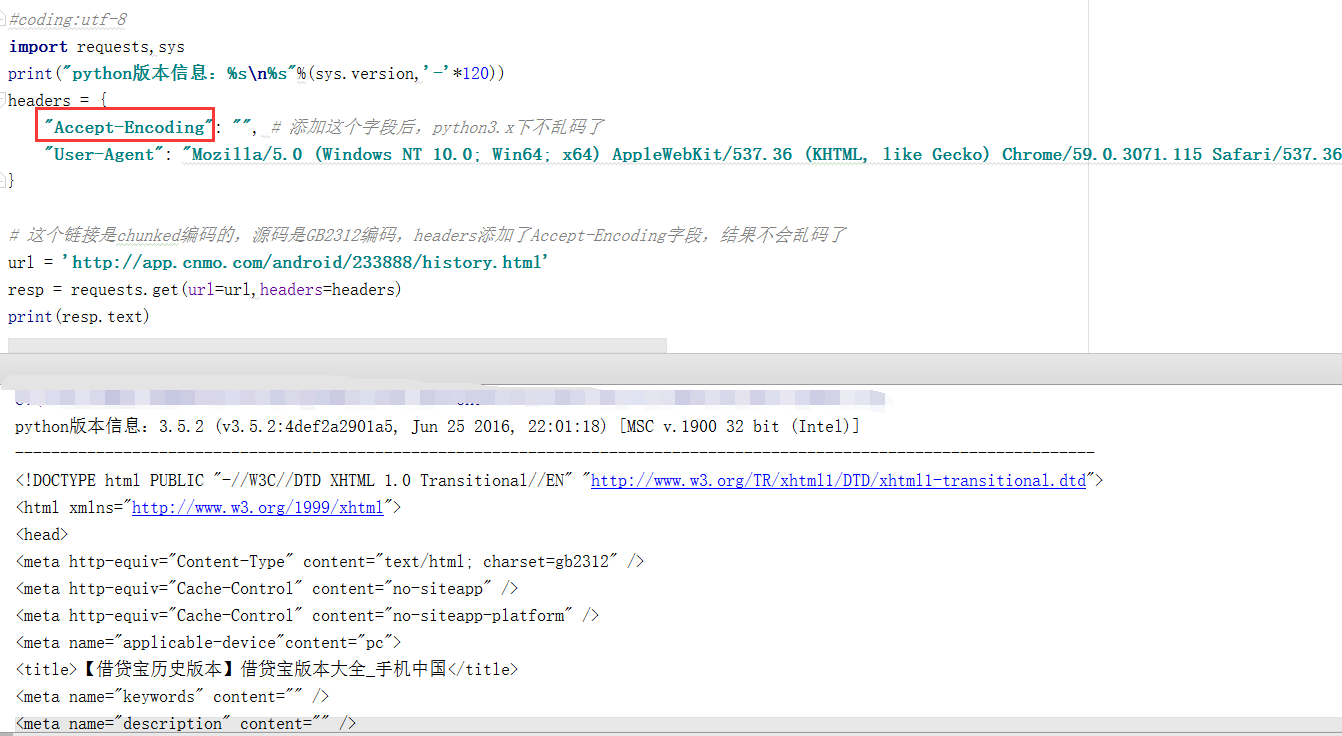
晚上再看了一遍网页请求头,干脆全部添加进去,结果不乱码了。后面只保留"Accept-Encoding"、"User-Agent"字段,不乱码,"Accept-Encoding"的值可以为空或任意编码,好像都不乱码。至于为什么我不清楚,可能需要开发者解答了
1 #coding:utf-8 2 import requests 3 headers = { 4 "Accept-Encoding": "", # 添加这个字段后,python3.x下不乱码了 5 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36" 6 } 7 8 # 这个链接是chunked编码的,源码是GB2312编码,headers添加了Accept-Encoding字段,结果不会乱码了 9 url = 'http://app.cnmo.com/android/233888/history.html' 10 resp = requests.get(url=url,headers=headers) 11 print(resp.text)
python3.5.2已经不乱码了

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









