






 本文介绍使用Scrapy爬取安居客房产信息,并利用PyEcharts和MongoDB进行数据可视化的过程,包括新房分布、房价平均值、户型比例及全国新房地理热力图。
本文介绍使用Scrapy爬取安居客房产信息,并利用PyEcharts和MongoDB进行数据可视化的过程,包括新房分布、房价平均值、户型比例及全国新房地理热力图。
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~
先看看保存的数据吧~
本人之前都是习惯把爬到的数据保存到本地json文件,
这次保存到数据库后发现使用mongodb的聚合统计省去了好多自己用python写计算逻辑的步骤,好方便啊~~

第一张图柱状图
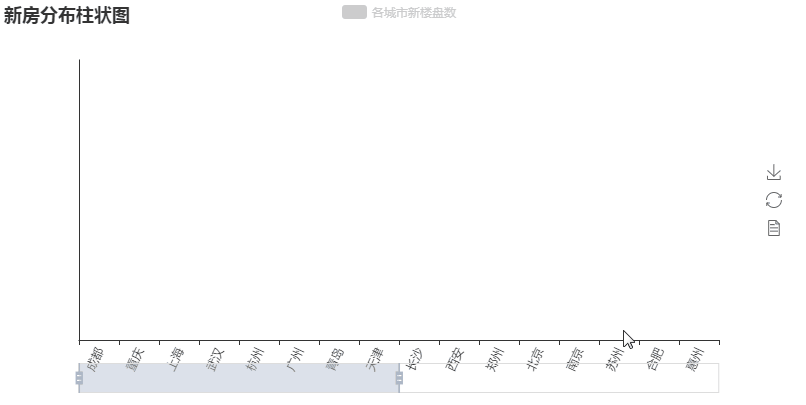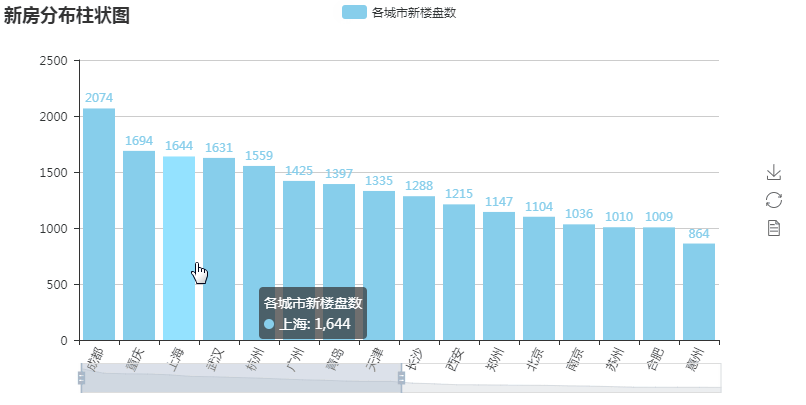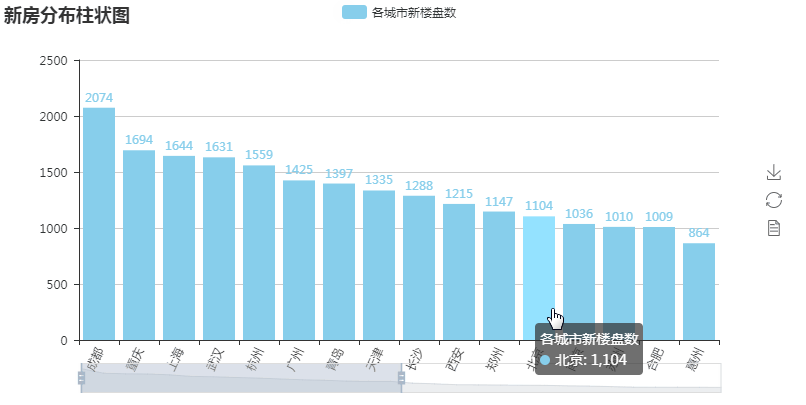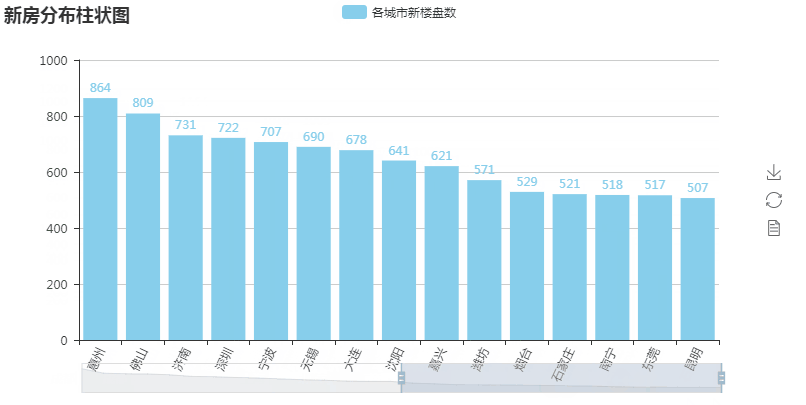
第一张图代码解析:
#encoding:utf-8 import random from pyecharts import Bar from pymongo import MongoClient conn = MongoClient('127.0.0.1',27017) #创建于MongoDB的连接 db = conn.anjuke #选择数据库 collection=db.AnjukeItem #选择数据库下的集合 all = [] res = collection.aggregate([ {'$group':{'_id':'$city', 'count':{'$sum':1}}}, {'$sort':{'count':-1}},]) conn.close() #上面是mongodb聚合统计的语句 #$group:按照给定表达式组合结果,这里的_id字段表示你要基于哪个字段来进行分组,这里的$city就表示要基于city字段来进行分组 #下面的count字段的值$sum: 1表示的是获取--满足city字段相同的这一组的数量--乘以后面给定的值(本例为1,那么就是同组的数量)。 #$sort:按照给定的字段排序结果,即按计算好的count排序,-1为降序来排列 for i in res: #print(i) #{'_id': '成都', 'count': 2074} all.append((i['_id'].strip(),i['count'])) attr = [i[0] for i in all[:30] ] #取前三十城市的名字 v1 = [i[1] for i in all[:30]] #取前三十城市的值 print(attr) bar = Bar('新房分布柱状图') #柱状图 bar.add('各城市新楼盘数',attr,v1,is_label_show=True,is_datazoom_show=True,xaxis_rotate=65, label_color=['#87CEEB',]) #attr 下面的城市名 #v1 数值 #is_label_show -> bool 是否正常显示标签,默认不显示。即各柱上的数字 #is_datazoom_show -> bool 是否使用区域缩放组件,默认为 False #xaxis_rotate -> int x 轴刻度标签旋转的角度,默认为 0,即不旋转。旋转的角度从 -90 度到 90 度。 #label_color 柱的颜色 bar.render('bar.html') #html生成
第二张图柱状图 :
:
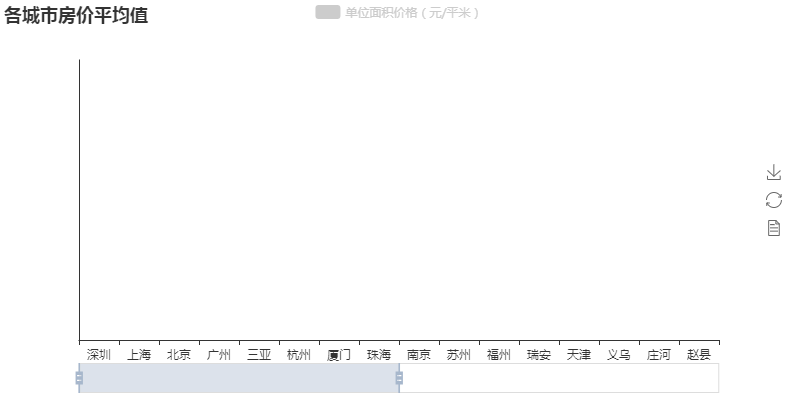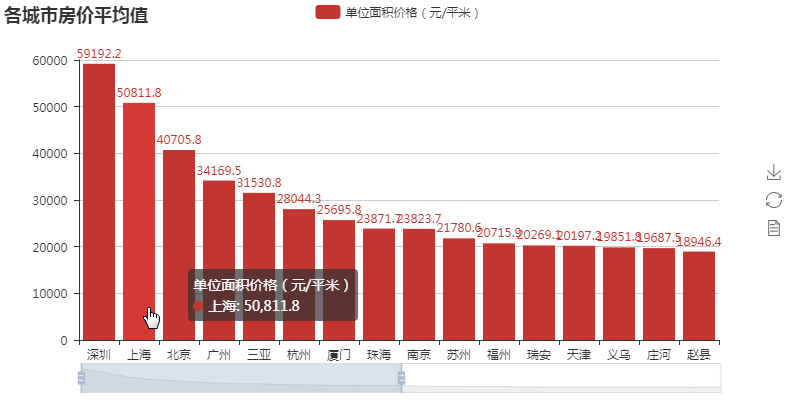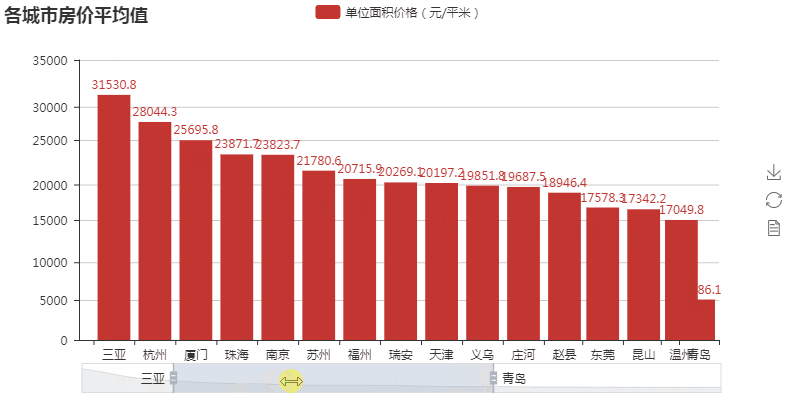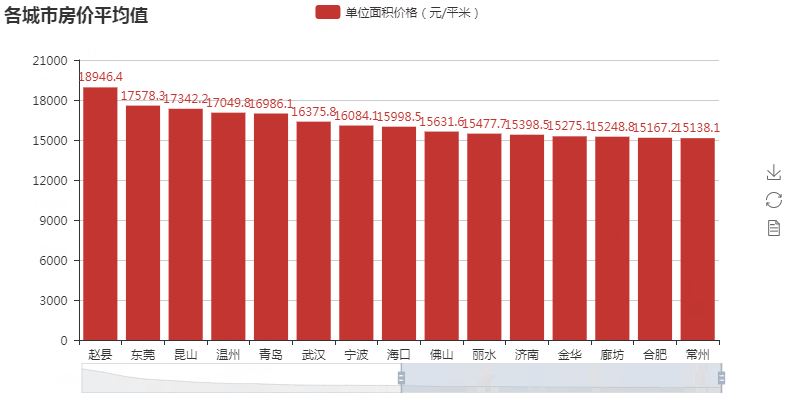
第二图代码解析:
#encoding:utf-8 from pymongo import MongoClient from pyecharts import Bar conn = MongoClient('127.0.0.1',27017) db = conn.anjuke collection=db.AnjukeItem res = collection.find() conn.close() #连接mongodb的逻辑,同上~ all = {} for i in res: city = i['city'] #获取城市名 try: if i['price'][1].isdecimal(): #判断i['price'][1]是不是数字型的价格 price_type = i['price'][0] #获取价格类型 price = i['price'][1] price = int(price) #str价格转int价格 elif i['price'][2].isdecimal(): #判断i['price'][2]是不是数字型的价格 price_type = i['price'][1] #获取价格类型 price = i['price'][2] price = int(price) #str价格转int价格 except: continue if '均价' in price_type: #只取均价 if city in all: all[city].append(price) else: all[city] = [price,] print(all) #{'_id': '黑河', 'count': 17} #{'_id': '甘南', 'count': 17} #{'_id': '陇南', 'count': 16} all_avg = [] for city,prices in all.items(): all_avg.append((city,sum(prices)/len(prices))) #计算所有的城市房价平均值,all_avg里的元素为元组(城市名,均价) all_avg = sorted(all_avg,key=lambda x:x[1],reverse=True) #降序排序 print(all_avg) #[('深圳', 59192.21692307692), ('上海', 50811.7504091653), ... attr = [i[0] for i in all_avg[:30] ] #获取前30城市名 v1 = ['{:.1f}'.format(i[1]) for i in all_avg[:30]] #获取前30名的值 bar = Bar('各城市房价平均值') bar.add('单位面积价格(元/平米)',attr,v1,is_label_show=True,is_datazoom_show=True) #画图逻辑,同上 bar.render('bar2.html')
第三张图玫瑰图
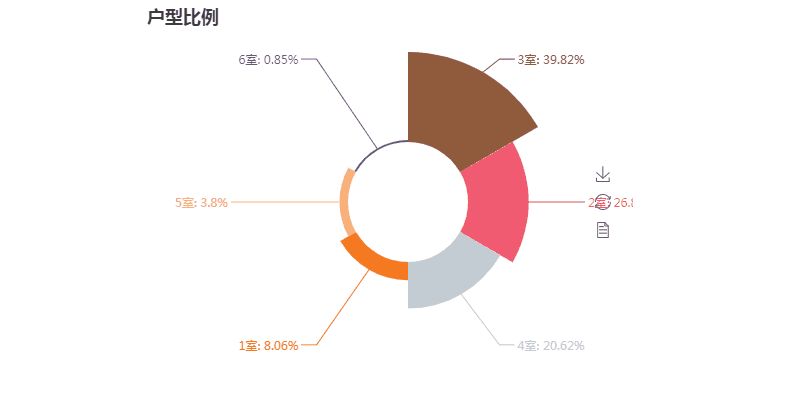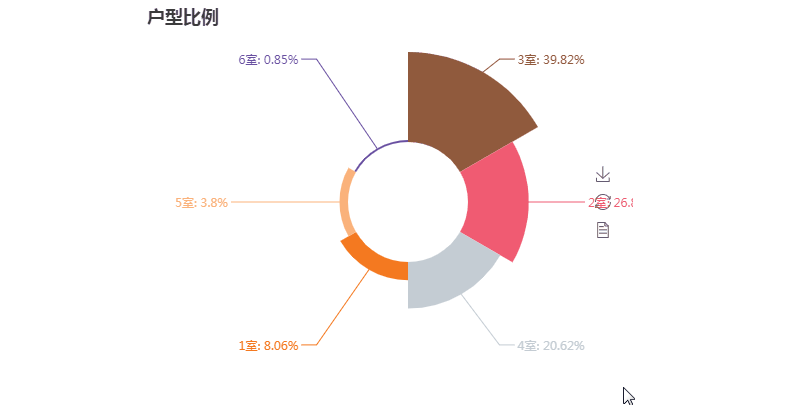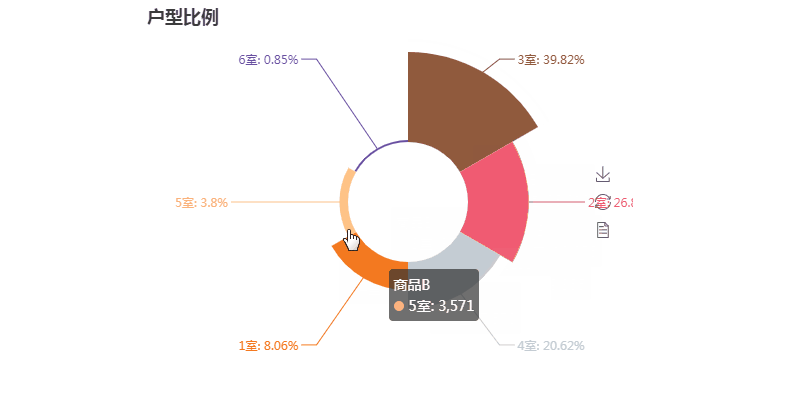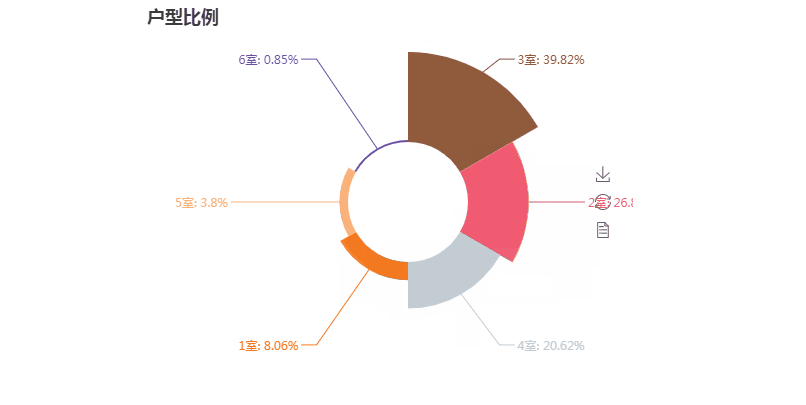
第三张图代码解析:
from pyecharts import Pie from pymongo import MongoClient conn = MongoClient('127.0.0.1',27017) db = conn.anjuke collection=db.AnjukeItem #Mongodb的连接 all = [] res = collection.aggregate( [ { '$unwind': '$type_' },{ '$group': { '_id': '$type_', 'count': {'$sum': 1} } } ] ) #上面是mongodb聚合统计的语句 #'$unwind': '$type_'因为type_是一个列表这里是将type_拆分了,用以下面的计算 #$group:按照给定表达式组合结果,这里的_id字段表示你要基于哪个字段来进行分组,这里的$type_就表示要基于type_字段来进行分组 #下面的count字段的值$sum: 1表示的是获取--满足type_字段相同的这一组的数量--乘以后面给定的值(本例为1,那么就是同组的数量)。 conn.close() all = [] for i in res: print(i) #{'_id': '商业', 'count': 337} #{'_id': '商办', 'count': 158} #{'_id': '8室', 'count': 76} if '室' in i['_id']: #只取有'室'关键字的数据 all.append((i['_id'],i['count'])) all = sorted(all,key=lambda x:x[1],reverse=True) #以数量进行排序 print(all) attr = [i[0] for i in all][:6] #取前六的类型名 v1 = [i[1] for i in all][:6] #取前六的数值 pie =Pie("户型比例", title_pos='center', width=900) #pie.add("商品A", attr, v1, center=[25, 50], is_random=True, radius=[30, 75], rosetype='radius') pie.add("商品B", attr, v1, is_random=True, radius=[30, 75], rosetype='area', is_legend_show=False, is_label_show=True) #is_random为是否随即排列颜色列表 #radius为半径,第一个为内半径,第二个是外半径; #rosetype为是否展示成南丁格尔图( 'radius' 圆心角展现数据半分比,半径展现数据大小;'area' 圆心角相同,为通过半径展现数据大小) #is_label_show为是否显示标签(各个属性的数据信息) #is_legend_show:是否显示图例 pie.render('pie.html')
第四张图地理热力图
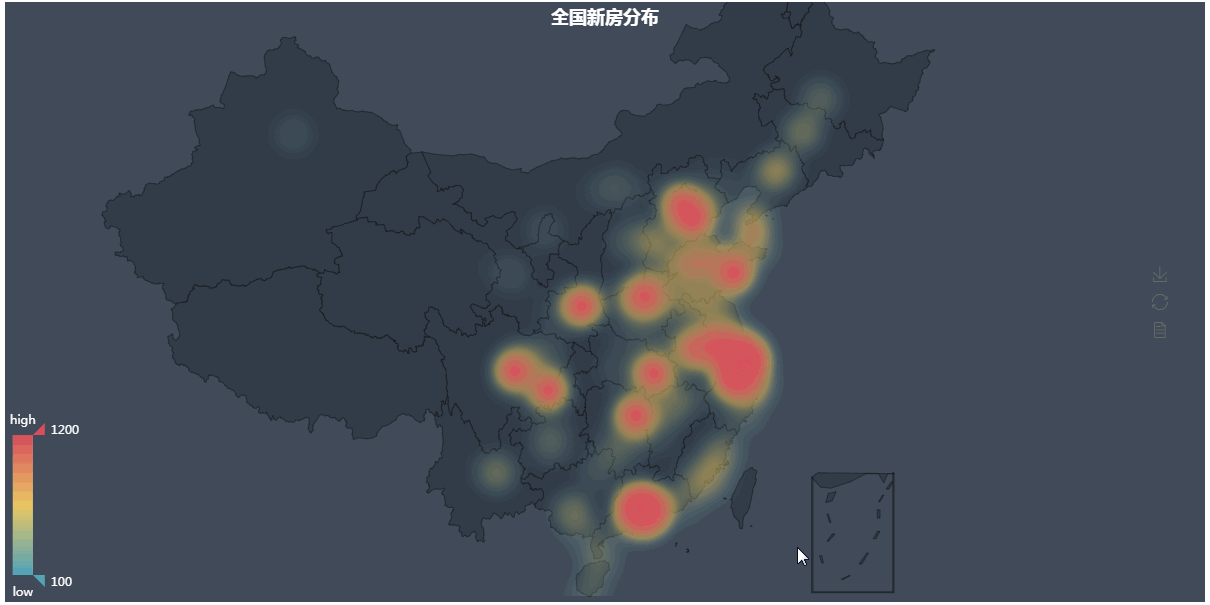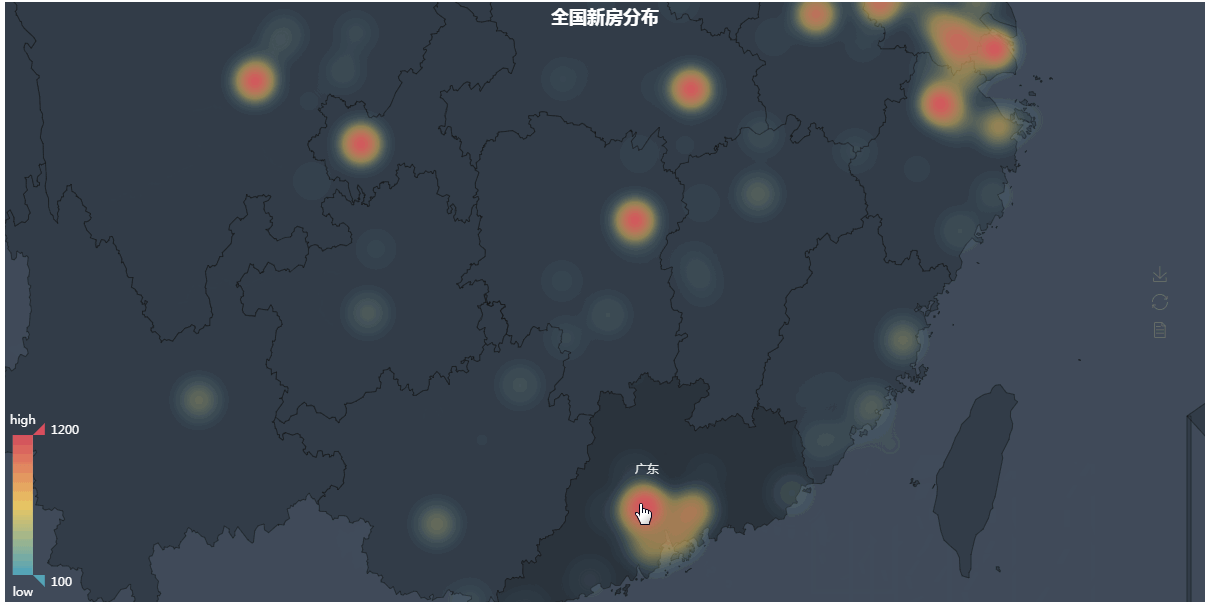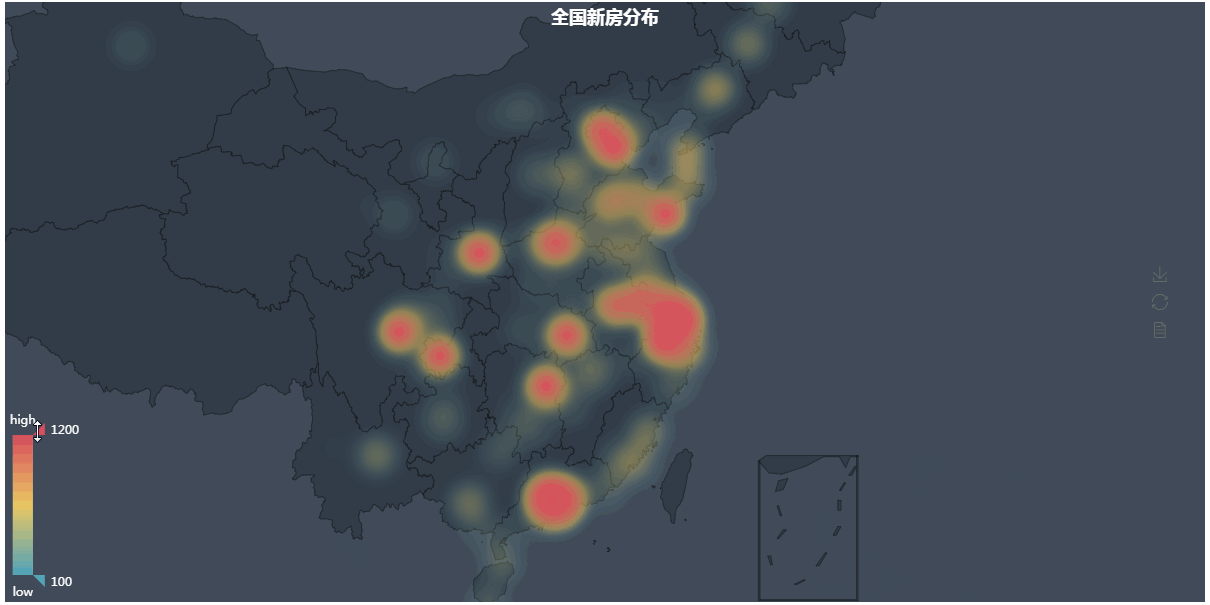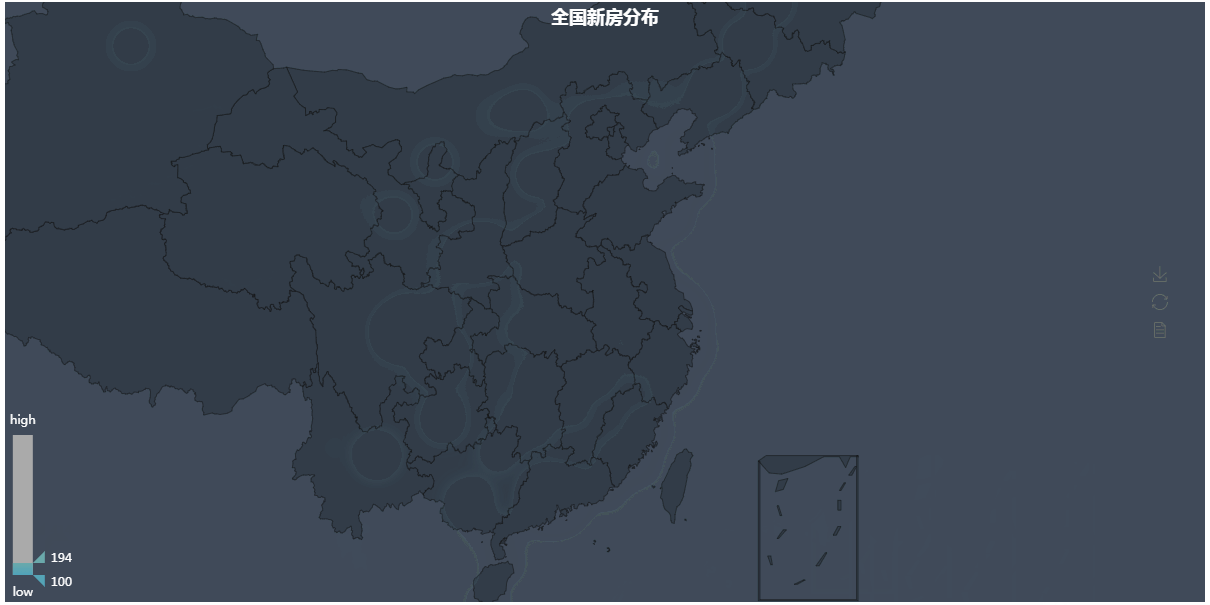
第四张图代码解析:
#coding=utf-8 from pymongo import MongoClient from pyecharts import Geo import json conn = MongoClient('127.0.0.1',27017) db = conn.anjuke collection=db.AnjukeItem #res=collection.distinct("city") all = [] res = collection.aggregate([ {'$group':{'_id':'$city', 'count':{'$sum':1}}}, {'$sort':{'count':-1}},]) for i in res: all.append((i['_id'].strip(),i['count'])) conn.close() #连接查询,和图一一样 new_all =[] with open('city_coordinates.json','r',encoding='utf-8') as f: #这里是复制到pyecharts的地理json数据和爬到的城市名对比,因为好多爬到的城市其实在pyecharts是没有记录的,直接绘图会报错 #位置在\Python36\Lib\site-packages\pyecharts\datasets\city_coordinates.json all_city = json.loads(f.read(),encoding='utf-8') for i in all: if i[0] in all_city: new_all.append(i) geo = Geo( "全国新房分布", #图标题 "", #副标题 title_color="#fff", #标题颜色 title_pos="center", #标题位置 width=1200, #图宽 height=600, #高 background_color="#404a59", #背景颜色 ) attr, value = geo.cast(new_all) #分开城市名和数值 geo.add( "", attr, value, visual_range=[100, 1200], #显示的数值范围 visual_text_color="#fff", #鼠标放上去后显示的文字颜色 symbol_size=15, #标记的大小 type='heatmap', #类型为热力图 is_visualmap=True, ) geo.render()
End...

















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









