



中文分词一直都是中文自然语言处理领域的基础研究。目前,网络上流行的很多中文分词软件都可以在付出较少的代价的同时,具备较高的正确率。而且不少中文分词软件支持Lucene扩展。但不管实现如何,目前而言的分词系统绝大多数都是基于中文词典的匹配算法。
本篇文章主要介绍一下中文分词的一个最基础算法:最大匹配算法 (Maximum Matching,以下简称MM算法) 。MM算法有两种:一种正向最大匹配,一种逆向最大匹配。
● 算法思想
正向最大匹配算法:从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。但这里有一个问题:要做到最大匹配,并不是第一次匹配到就可以切分的 。我们来举个例子:
待分词文本: content[]={"中","华","民","族","从","此","站","起","来","了","。"}
词表: dict[]={"中华", "中华民族" , "从此","站起来"}
(1) 从content[1]开始,当扫描到content[2]的时候,发现"中华"已经在词表dict[]中了。但还不能切分出来,因为我们不知道后面的词语能不能组成更长的词(最大匹配)。
(2) 继续扫描content[3],发现"中华民"并不是dict[]中的词。但是我们还不能确定是否前面找到的"中华"已经是最大的词了。因为"中华民"是dict[2]的前缀。
(3) 扫描content[4],发现"中华民族"是dict[]中的词。继续扫描下去:
(4) 当扫描content[5]的时候,发现"中华民族从"并不是词表中的词,也不是词的前缀。因此可以切分出前面最大的词——"中华民族"。
由此可见,最大匹配出的词必须保证下一个扫描不是词表中的词或词的前缀才可以结束。
● 算法实现
词表的内存表示: 很显然,匹配过程中是需要找词前缀的,因此我们不能将词表简单的存储为Hash结构。在这里我们考虑一种高效的字符串前缀处理结构——Trie树《Trie Tree 串集合查找 》。这种结构使得查找每一个词的时间复杂度为O(word.length),而且可以很方便的判断是否匹配成功或匹配到了字符串的前缀。
下图是我们建立的Trie结构词典的部分,(词语例子:"中华","中华名族","中间","感召","感召力","感受")。
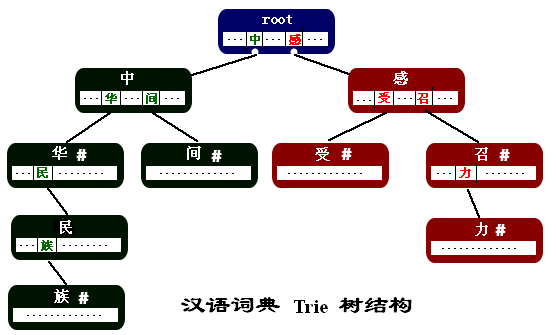
(1) 每个结点都是词语中的一个汉字。
(2) 结点中的指针指向了该汉字在某一个词中的下一个汉字。这些指针存放在以汉字为key的hash结构中。
(3) 结点中的"#"表示当前结点中的汉字是从根结点到该汉字结点所组成的词的最后一个字。
TrieNode源代码如下:
import java.util.HashMap; /** * 构建内存词典的Trie树结点 * * @author single(宋乐) * @version 1.01, 10/11/2009 */ public class TrieNode { /**结点关键字,其值为中文词中的一个字*/ public char key=(char)0; /**如果该字在词语的末尾,则bound=true*/ public boolean bound=false; /**指向下一个结点的指针结构,用来存放当前字在词中的下一个字的位置*/ public HashMap<Character,TrieNode> childs=new HashMap<Character,TrieNode>(); public TrieNode(){ } public TrieNode(char k){ this.key=k; } }
这套分词代码的优点是:
(1) 分词效率高。纯内存分词速度大约240.6ms/M,算上IO读取时间平均1.6s/M。测试环境:Pentium(R) 4 CPU 3.06GHZ、1G内存。
(2) 传统的最大匹配算法需要实现确定一个切分的最大长度maxLen。如果maxLen过大,则大大影响分词效率。而且超过maxLen的词语将无法分出来。但本算法不需要设置maxLen。只要词表中有的词,不管多长,都能够切分。
(3) 对非汉字的未登录词具备一定的切分能力。比如英文单词[happy, steven],产品型号[Nokia-7320],网址[http://www.sina.com]等。
缺点也很明显:
(1) 暂时无词性标注功能,对中文汉字的未登录词无法识别,比如某个人名。
(2) 内存占用稍大,目前词表为86725个词。如果继续扩展词表,很有可能内存Trie树将非常庞大。
源代码:mmsegger_src_1.0.rar (333.3 KB)

















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









