



 本文探讨了压缩感知理论中离散信号的获取与重构过程。介绍了如何通过测量离散信号的少量投影来获取信号,并利用稀疏表示进行信号重构。重点讨论了信号的稀疏表示、测量矩阵的选择及重构过程。
本文探讨了压缩感知理论中离散信号的获取与重构过程。介绍了如何通过测量离散信号的少量投影来获取信号,并利用稀疏表示进行信号重构。重点讨论了信号的稀疏表示、测量矩阵的选择及重构过程。
This is adapted from tuorial notes by Wusheng Lu, 2010.
Now let us consider a discrete signal \(x\in R^n\) which itself may or may not be sparse in the canonical basis
but is sparse or approximately sparse in an appropriate basis \(\Psi \in R^{n\times n}\)(often othognormal) . That is,
\[x=\Psi \theta \tag{1}\]
where \(\theta\) is sparse or approximately sparse.
A central idea in the current CS theory is about how a (discrete) signal is acquired: the acquisition of signal \(x\) of length \(n\) is carried out by measuring \(m<< n\) projections of \(x\) onto sensing (also known as testing) vectors \(\{\phi_i^T,i=1,2,\cdots,m\}: y_i=\phi_i^Tx\) for \(i = 1,2, \cdots, m.\) Using this notation, the sensing process is decribed by
\[y=\hat{\Phi}\cdot x =\hat{\Phi}\Psi \cdot x:=A\theta \tag{2}\]
where
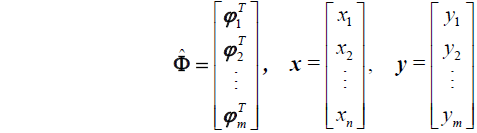 (3)
(3)
and \(\phi_i\) have unit length.
The task now is to recover sparse reparesenation \(\theta\in R^n\) given \(y\in R^m\) and \(A\in R^{m\times n}\).
Once the solution \(\theta^*\) is found, the signal \(x\) is reconstructed as \(x^*=\Psi\theta^*\).
[Note] We use \(\hat{\Phi}\in R^{m\times n}\) rather than \(\Phi\in R^{n\times n}\), to empasize we are selecting randomly from the implicite complete measurement devices.
Here are two questions that naturally arise from signal model (3).





$\textbf{In practice, we oftern choose row selection matrix as $\Phi=[e_{k1},e_{k2},\cdots, e_km]^T $ }$
About the definition of incoherence \(\mu\):



















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









