






 本文详细介绍了Oracle中instr和substr函数的使用方法及应用案例,包括如何判断字符串中是否包含特定字符、如何从字符串中提取指定字符,并通过实例展示了它们在模糊查询和判断包含关系中的应用。
本文详细介绍了Oracle中instr和substr函数的使用方法及应用案例,包括如何判断字符串中是否包含特定字符、如何从字符串中提取指定字符,并通过实例展示了它们在模糊查询和判断包含关系中的应用。
在oracle中,可以使用instr函数对某个字符串进行判断,判断其是否含有指定的字符。在一个字符串中查找指定的字符,返回被查找到的指定字符的位置。
语法:
Instr(sourceString,destString, start,appearPosition)
Instr('源字符串' , '目标字符串' ,'开始位置','第几次出现')
appearPosition代表想从源字符中查找出第几次出现的destString,这个参数也是可选的, 默认为1,如果start的值为负数,则代表从右往左进行查找,但是位置数据仍然从左向右计算。--也就是查找从右往左,但查找到的数据位置是从左往右数的位置。
返回值为:查找到的字符串的位置。
举例:
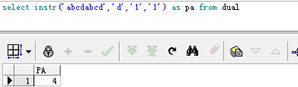
instr用法:
select instr('abcd','a') from dual; --返回1
select instr('abcd','c') from dual; --返回3
select instr('abcd','e') from dual; --返回0
该函数可以用于模糊查询以及判断包含关系:
例如:
① select code, name, dept, occupation from staff where instr(code, '001') > 0;
等同于
select code, name, dept, occupation from staff where code like '%001%' ;
② select ccn,mas_loc from mas_loc where instr('FH,FHH,FHM',ccn)>0;
等同于
select ccn,mas_loc from mas_loc where ccn in ('FH','FHH','FHM');
Substr()函数:用于从给定的字符串中返回一个子字符串。
语法:substr(cExpression,nStartPostion,[, nCharactersReturned])
Substr(字符串,截取开始位置,截取长度)//返回截取的字
其中截取位置(nStartPostion)默认为1,与0一致。
举例:
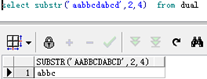
substr('Hello World',-3,3)//返回结果为 'rld' *负数(-i)表示截取的开始位置为字符串右端向左数第i个字符。
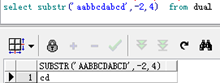
-----
Postgresql有相同substr函数,功能相同,但是在0位置返回不同,且存在负数位置,如:
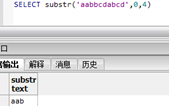
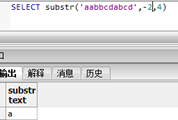
但正数位置是相同的:
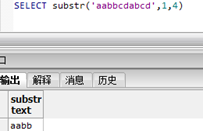
Postgresql对此俩函数的改造可分别用:postion() substring()。
---------
本系列为最近一段时间学习oracle的学习笔记,记录于此作为自身回顾,其中有的来的网络,有的来的书籍,但时间已久,记不清哪些是引用,如是转载但没标注出,特意致歉。

















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









