 Flume日志收集配置
Flume日志收集配置




 本文介绍如何使用Flume进行日志数据收集的过程,包括FlumeAgent的配置详情,通过HTTP源接收数据,并利用HDFS作为目标存储。此外还演示了如何通过curl命令模拟发送HTTP请求,以及验证数据是否正确存储到了HDFS。
本文介绍如何使用Flume进行日志数据收集的过程,包括FlumeAgent的配置详情,通过HTTP源接收数据,并利用HDFS作为目标存储。此外还演示了如何通过curl命令模拟发送HTTP请求,以及验证数据是否正确存储到了HDFS。
1、目标场景
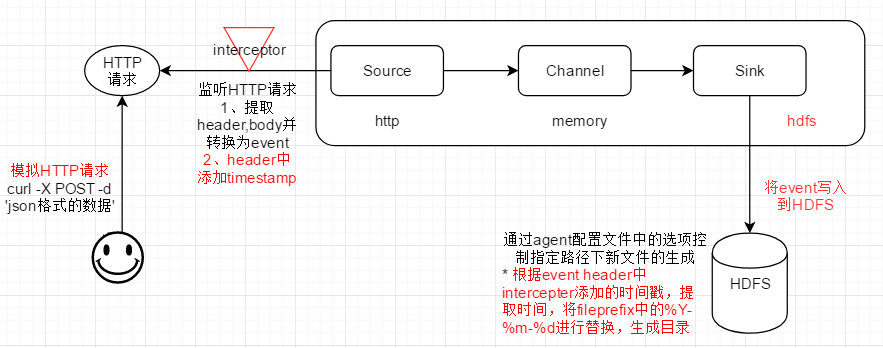
2、Flume Agent配置
# specify agent,source,sink,channel a1.sources = r1 a1.sinks = k1 a1.channels = c1 # handler将根据JSON规则,提取出header、body,然后生成flume event的header、body a1.sources.r1.type = http a1.sources.r1.bind = master a1.sources.r1.port = 6666 a1.sources.r1.handler = org.apache.flume.source.http.JSONHandler # interceptor将在flume event的header中增加时间戳 # 该interceptor将在flume event的header中增加当前系统时间 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = timestamp
# 如果flume event的header中已经有timestamp,是否保留;False表示不保留 a1.sources.r1.interceptors.i1.preserveExisting= false # hdfs sink a1.sinks.k1.type = hdfs # sink将会基于flume event头部的时间戳来提取年月日信息,在HFDS上创建目录 a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/%Y-%m-%d/ # 如果event的header中没有时间戳,就要打开下面的配置 # a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.filePrefix = interceptor- a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.wirteFormat = Text a1.sinks.k1.hdfs.rollSize = 102400000 a1.sinks.k1.hdfs.rollCount = 5 a1.sinks.k1.hdfs.rollInterval = 0 # channel, memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # bind source,sink to channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
3、curl命令,模拟发送HTTP请求(POST方法)
# curl -X POST -d '[{"headers":{}, "body":"timestamp teset 001"}]' http://master:6666
说明: -X POST 表示使用HTTP POST方法,将 -d 指明的 json格式的数据,发送给master的6666端口

4、检查HDFS上基于event时间戳信息的目录是否成功创建
1)第一个curl命令运行后,flume aget打印日志,提示基于时间戳的HDFS目录正在创建

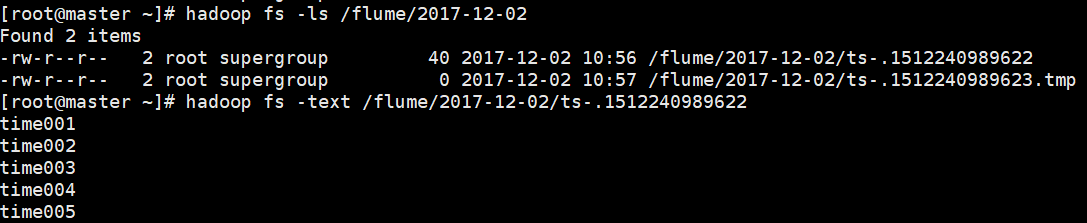
2)HDFS上的目录

3)flume event body中的数据,被保存到该目录在的HDFS文件中

















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









