



 本文详细介绍了多进程的使用方法、进程间通信手段、进程池的管理方式以及协程的基本概念与实现方式。通过示例代码,展示了多进程与协程在实际应用中的优势与局限。
本文详细介绍了多进程的使用方法、进程间通信手段、进程池的管理方式以及协程的基本概念与实现方式。通过示例代码,展示了多进程与协程在实际应用中的优势与局限。
一、多进程
进程就是一堆资源的集合,进程中至少包含一个线程。多进程的使用方法和线程类似,来看代码:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- import multiprocessing,time,threading def threading_run(): print(threading.get_ident()) def run(n): print("name: " , n) t = threading.Thread(target=threading_run) t.start() time.sleep(2) for i in range(10): p = multiprocessing.Process(target=run,args=("tom",)) p.start()
上述代码中可以看到,创建进程,启动进程等用法和多线程类似,多进程使用的包是multiprocessing,创建一个进程是multiprocessing.Process(target="目标函数",args=(参数列表,)),每个进程都有父进程,每个进程都由父进程创建,我们来看一下程序的进程号:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from multiprocessing import Process import os def info(title): print(title) print('module name:', __name__) print('parent process:', os.getppid()) #获取父进程的进程号 print('process id:', os.getpid()) #获取子进程的进程号 print("\n\n") def f(name): info('\033[31;1mcalled from child process function f\033[0m') print('hello', name) if __name__ == '__main__': info('\033[32;1mmain process line\033[0m') p = Process(target=f, args=('bob',)) p.start() 运行结果: main process line module name: __main__ parent process: 18775 process id: 19221 called from child process function f module name: __main__ parent process: 19221 process id: 19222 hello bob
二、进程间通信
进程使用的内存空间等资源都是独立的,如果需要进程间通信,那就需要借助第三方来实现。所以,进程间通信有如下几种方式。
1、进程队列
使用队列可以实现进程间通信,但是此处的队列和多线程中的队列是不一样的,需要单独从multiprocessing模块中单独的导入一个Queue模块,这是线程队列,看代码:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from multiprocessing import Process,Queue def f(qq): qq.put([1,2,3,4,5,6]) #2、子进程中向队列中添加一个值 if __name__ == "__main__": q = Queue() p = Process(target=f,args=(q,)) #1、启动一个进程,将生成的队列传递给该进程。 p.start() print("主进程获取子进程存的数据:",q.get()) #3、主进程中取队列中的值 运行结果: 主进程获取子进程存的数据: [1, 2, 3, 4, 5, 6]
2、管道--Pipe
除了上述使用队列的方式来实现数据传递外,还可以使用管道的方式在进程间实现数据通信,初始化一个管道对象,会生成两个实例,进程间通信就使用这两个实例来完成,就好像生成了两个电话,两个进程各自拿一个电话,然后就可以打电话了,这种方式类似于socket中发送数据和接收数据的形式,进程发一条,对方就收一条,收发关系都是一一对应的,来看代码:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, 'hello from child']) conn.send([42, None, 'hello from child2']) print("from parent:",conn.recv()) conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() #生成管道实例,生成后产生两个实例 p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) print(parent_conn.recv()) parent_conn.send("hello") p.join() 运行结果: [42, None, 'hello from child'] [42, None, 'hello from child2'] from parent: hello
3、数据共享--Manager
上述方法中,都是实现了数据的传递,但是如果需要不同进程间修改同一份数据,那又该怎么实现呢?此时就需要使用Manager方法来实现,该方法可以允许不通进程之间修改列表、字典、锁、递归锁等等数据结构,来看代码:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from multiprocessing import Process,Manager import os def f(d,l): d[os.getpid()] = os.getpid() #每个进程都将自己的进程号作为key和value写入字典 l.append(os.getpid()) #每个进程都把自己的进程号加入列表 print(l) if __name__ == "__main__": with Manager() as manager: d = manager.dict() #生成一个允许多进程间共享数据的字典 l = manager.list(range(5)) #生成一个多进程间允许共享数据的列表 p_list = [] for i in range(10): p = Process(target=f,args=(d,l)) p.start() p_list.append(p) for item in p_list: item.join() print(d) print(l) 运行结果: [0, 1, 2, 3, 4, 21769] [0, 1, 2, 3, 4, 21769, 21770] [0, 1, 2, 3, 4, 21769, 21770, 21771] [0, 1, 2, 3, 4, 21769, 21770, 21771, 21772] [0, 1, 2, 3, 4, 21769, 21770, 21771, 21772, 21773] [0, 1, 2, 3, 4, 21769, 21770, 21771, 21772, 21773, 21774] [0, 1, 2, 3, 4, 21769, 21770, 21771, 21772, 21773, 21774, 21775] [0, 1, 2, 3, 4, 21769, 21770, 21771, 21772, 21773, 21774, 21775, 21776] [0, 1, 2, 3, 4, 21769, 21770, 21771, 21772, 21773, 21774, 21775, 21776, 21777] [0, 1, 2, 3, 4, 21769, 21770, 21771, 21772, 21773, 21774, 21775, 21776, 21777, 21778] {21776: 21776, 21777: 21777, 21778: 21778, 21769: 21769, 21770: 21770, 21771: 21771, 21772: 21772, 21773: 21773, 21774: 21774, 21775: 21775} [0, 1, 2, 3, 4, 21769, 21770, 21771, 21772, 21773, 21774, 21775, 21776, 21777, 21778]
从上述结果中我们可以看到,不同进程间实现了对同一份数据的修改。
4、进程锁
进程中也有锁的概念,但是每个进程中数据都是独立的,那为什么还要加锁呢?原因很简单,所有的进程都要共享同一块屏幕,如果所有进程同时向屏幕上输出内容,就可能出现一个进程输出了一半,另一个进程就抢占了屏幕,最终导致输出结果错乱,所以我们需要加一把锁来防止这种事情发生,接下来我们就看下具体的使用方法:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from multiprocessing import Process,Lock def run(l,n): l.acquire() print("child process:",n) l.release() if __name__ == "__main__": lock = Lock() #生成一把锁 for i in range(10): p = Process(target=run,args=(lock,i)) p.start() 运行结果: child process: 0 child process: 1 child process: 2 child process: 3 child process: 4 child process: 5 child process: 6 child process: 7 child process: 8 child process: 9
三、进程池
每个进程在启动的时候都会向系统申请一份独立的资源,这就导致多进程对资源的需求特别大,所以我们有必要限制一下同时启动的进程数,这就用到了进程池的概念,这样可以有效的防止同时启动大量进程导致硬件资源被耗尽。
进程池有两个方法:
apply:同步执行,串行
apply_async:异步执行,并行
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from multiprocessing import Process,Pool import os,time def Foo(n): time.sleep(2) print("in process:",os.getpid()) return n + 100 def Bar(arg): print("exec -->" , arg,os.getpid()) if __name__ == "__main__": pool = Pool(3) for i in range(10): #pool.apply(func=Foo,args=(i,)) #同步执行,串行 pool.apply_async(func=Foo,args=(i,),callback=Bar) #异步执行,并行,callback表示回调函数,如果Foo执行完成后就调用callback回调函数 pool.close() #先执行close()关闭进程池,再执行join()等待所有进程执行完成 pool.join() 运行结果: in process: 23887 in process: 23888 in process: 23889 exec --> 100 23886 exec --> 102 23886 exec --> 101 23886 in process: 23887 in process: 23889 in process: 23888 exec --> 103 23886 exec --> 104 23886 exec --> 105 23886 in process: 23887 in process: 23889 in process: 23888 exec --> 106 23886 exec --> 108 23886 exec --> 107 23886 in process: 23887 exec --> 109 23886
上述代码中使用了回调函数,如果Foo执行完成后就调用callback回调函数,这个回调函数是由主进程调用的,如果所有进程在执行完成后都需要连接数据库写一条数据的话,那么如果进程数太多的话会导致数据库连接数过多,所以此时可以使用回调函数来连接数据库,这样只需要有一个数据库连接就可以完成了。
在上述代码中,我们还需要注意一下,在写join()方法等待所有进程结束的时候,应该先关闭进程池,然后再join()。
四、协程
我们知道,在多线程中,之所以可以进行多线程的并发执行,是因为系统对我们的多线程做了上下文的切换,这种切换是操作系统替我们完成的。
那同样,什么是协程呢?协程就是一种用户态的线程。这句话的意思就是表示,协程的控制是由用户来完成的,也就是说,在协程中,协程自己记录了自己的上下文信息,这些信息就不是存在CPU的寄存器里,也就不受操作系统的直接管理,而是由用户自行定义切换的时机。这也就是说,协程其实还是单线程,只不过协程程序在运行到一个用户自己定义的切换的点时自动由一个任务切换到另一个任务,从而使得程序中多个任务之间看起来像是一种并发执行的状态。但是在操作系统角度来看,这个程序还是一个单线程的程序。
协程的优点:
a、无需线程上下文切换的开销(因为所有的切换过程不是操作系统完成的,是程序自身完成的)
b、无需原子操作锁定及同步的开销(协程还是一个单线程程序,这也就意味着同一时间只能有一个操作在修改数据,也就无需加锁)
c、方便切换控制流,简化编程模型(协程切换可以用户自己来决定)
d、高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。(综上所述)
1、greenlet
使用greenlet模块就可以手动控制程序的切换,这个模块在安装gevent模块时会依赖安装上。来看代码:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from greenlet import greenlet def test1(): print(12) gr2.switch() print(34) gr2.switch() def test2(): print(56) gr1.switch() print(78) gr1.switch() gr1 = greenlet(test1) #启动一个协程 gr2 = greenlet(test2) gr1.switch() #协程切换 运行结果: 12 56 34 78
上述代码中我们可以看到,通过switch()方法,我们可以手动切换任务,此时程序就是在单线程中来回切换任务,从而让test1和test2的执行看起来是并发的,这就是协程,但是如果一旦在执行某个任务的过程中,出现了阻塞,而且又没有在此处添加切换,那么这个阻塞就会把整个程序阻塞掉,比如上述代码,我们改一下:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from greenlet import greenlet import time def test1(): print(12) time.sleep(4) gr2.switch() print(34) gr2.switch() def test2(): print(56) gr1.switch() print(78) gr1.switch() gr1 = greenlet(test1) #启动一个协程 gr2 = greenlet(test2) gr1.switch()
我们在test1切换前让程序阻塞,在其他程序中此处可能是I/O操作,也可能是等待链接等,此时我们可以看到,整个程序在执行时都阻塞在了sleep处,这也就是协程在遇到阻塞时会阻塞掉整个程序。而且,由于协程实际上是在一个单线程中,所以协程并不能利用多个CPU或者多核CPU,其只能在一核上运行,这也是协程的一大劣势。
2、gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
#!/usr/bin/env python3 # -*- coding:utf-8 -*- import gevent,time def foo(): print("start running func foo!") #time.sleep(2) #非I/O操作,不会触发切换 gevent.sleep(2) #I/O操作,会触发切换 print("back to func foo!") def bar(): print("start running func bar!") #time.sleep(3) gevent.sleep(3) print("back to func bar!") gevent.joinall( #将协程以列表的形式交给gevent去调度 [ gevent.spawn(foo),#启动一个协程 gevent.spawn(bar) ] ) 运行结果: start running func foo! start running func bar! back to func foo! back to func bar!
从上述过程我们可以看到,当程序执行时遇到gevent.sleep()方法时就会触发协程的切换。
有了上述的知识,我们来写一个小程序,去爬一个网页下来,看看串行和协程的方式程序的效率:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from urllib import request #导入request模块方法 import gevent,time def f(url): print("GET: %s" % url) res = request.urlopen(url) #请求一个url data = res.read() #将接收到的数据读出来 print("recv: %s" % len(data)) url_list = ["http://github.com","http://www.yahoo.com","http://www.163.com"] start_time = time.time() for i in url_list: f(i) #串行执行 fin_time = time.time() print("serial cost:" , fin_time - start_time,"\n") on_time = time.time() gevent.joinall([ gevent.spawn(f,"http://github.com"), gevent.spawn(f,"http://www.yahoo.com"), gevent.spawn(f,"http://www.163.com") ]) f_time = time.time() print("parallel cost:" , f_time - on_time) 运行结果: GET: http://github.com recv: 25484 GET: http://www.yahoo.com recv: 530160 GET: http://www.163.com recv: 741003 serial cost: 6.114256858825684 GET: http://github.com recv: 25484 GET: http://www.yahoo.com recv: 529501 GET: http://www.163.com recv: 741003 parallel cost: 4.224908113479614
上述代码中我们可以看到,串行和并行的执行时间似乎差不多,而且协程貌似也是串行执行的,并没有切换,这是为什么呢?原因在于gevent对于urllib的I/O操作并不能识别出来,所以就没法切换,我们可以通过一个模块来解决这个问题,那就是monkey模块,来看代码:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from urllib import request import gevent,time from gevent import monkey #导入monkey模块 monkey.patch_all() #给程序中所有的I/O操作做标记,供gevent模块抓取 def f(url): print("GET: %s" % url) res = request.urlopen(url) data = res.read() print("recv: %s" % len(data)) url_list = ["http://github.com","http://www.yahoo.com","http://www.163.com"] start_time = time.time() for i in url_list: f(i) fin_time = time.time() print("serial cost:" , fin_time - start_time,"\n") on_time = time.time() gevent.joinall([ gevent.spawn(f,"http://github.com"), gevent.spawn(f,"http://www.yahoo.com"), gevent.spawn(f,"http://www.163.com") ]) f_time = time.time() print("parallel cost:" , f_time - on_time) 运行结果: GET: http://github.com recv: 25484 GET: http://www.yahoo.com recv: 535277 GET: http://www.163.com recv: 740922 serial cost: 7.930154085159302 GET: http://github.com GET: http://www.yahoo.com GET: http://www.163.com recv: 740922 recv: 535064 recv: 25484 parallel cost: 2.0000741481781006
从程序运行结果看,卧槽,老牛逼了,果然厉害!
五、事件驱动与异步I/O
通常,我们写服务器处理模型的程序时,有以下几种模型:
(1)每收到一个请求,创建一个新的进程,来处理该请求;
(2)每收到一个请求,创建一个新的线程,来处理该请求;
(3)每收到一个请求,放入一个事件列表,让主进程通过非阻塞I/O方式来处理请求
上面的几种方式,各有千秋,
第(1)中方法,由于创建新的进程的开销比较大,所以,会导致服务器性能比较差,但实现比较简单。
第(2)种方式,由于要涉及到线程的同步,有可能会面临死锁等问题。
第(3)种方式,在写应用程序代码时,逻辑比前面两种都复杂。
综合考虑各方面因素,一般普遍认为第(3)种方式是大多数网络服务器采用的方式
看图说话讲事件驱动模型
在UI编程中,常常要对鼠标点击进行相应,首先如何获得鼠标点击呢?
方式一:创建一个线程,该线程一直循环检测是否有鼠标点击,那么这个方式有以下几个缺点:
1. CPU资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的CPU资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
2. 如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
3. 如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以,该方式是非常不好的。
方式二:就是事件驱动模型
目前大部分的UI编程都是事件驱动模型,如很多UI平台都会提供onClick()事件,这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;
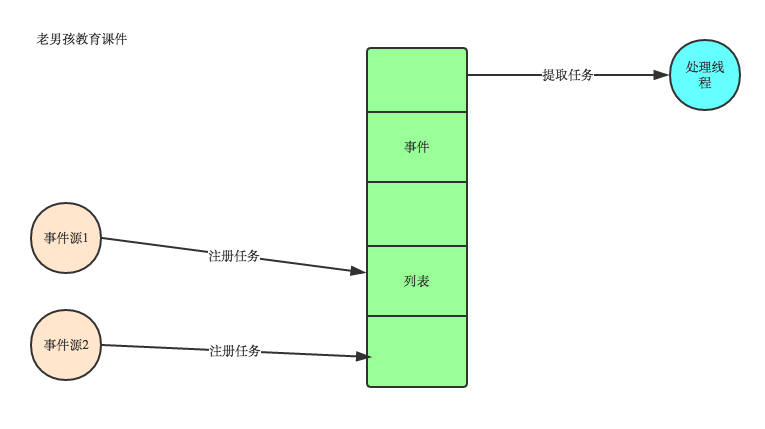
事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。另外两种常见的编程范式是(单线程)同步以及多线程编程。
让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。
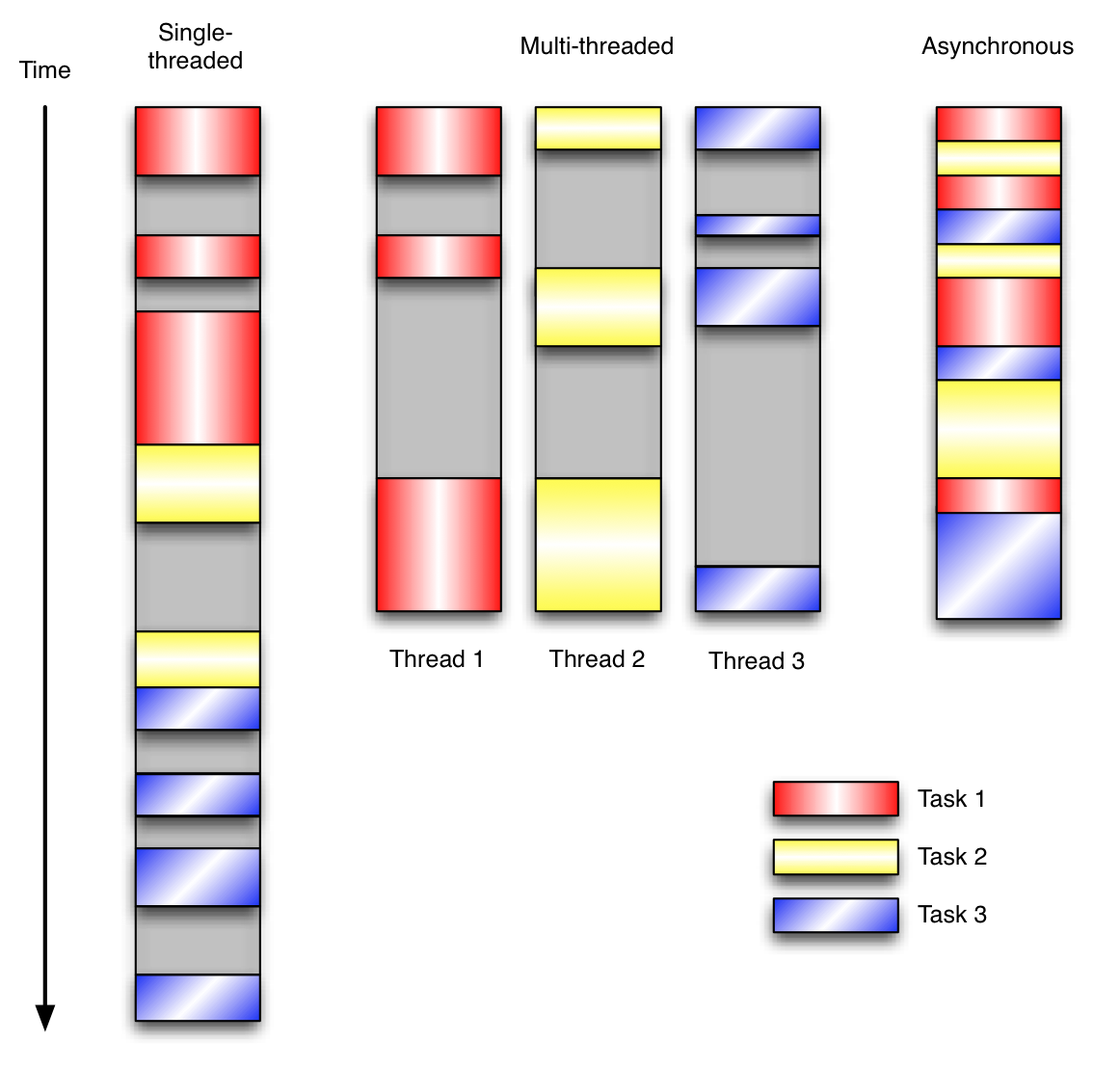
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
- 程序中有许多任务
- 任务之间高度独立(因此它们不需要互相通信,或者等待彼此)
- 在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。
六、Select\Poll\Epoll异步IO
http://www.cnblogs.com/alex3714/articles/5876749.html
http://www.cnblogs.com/alex3714/p/4372426.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









