






 本文介绍了一种区分中英文及数字的文章字数统计方法,并提供了具体的代码实现细节,包括中文、英文和数字的统计方式。
本文介绍了一种区分中英文及数字的文章字数统计方法,并提供了具体的代码实现细节,包括中文、英文和数字的统计方式。
因为功能需求,需要实现对于文章字数统计的一个方法编写.此处就不多说.直接进行代码讲解.
先来看看功能实现的字数统计要求: 字数统计区分中英文,一个英文单词为一个字,一个汉字为一个字,一个数字计为一个字.数字算在汉字字数中.简单的描述可以同work中的计算方式相同.
我们先来看看,word中对于字数统计的实现方式.
中文:中文不管连续还是分开,都是以一个字为一个计算单位.这个比较简单.贴个示意图.
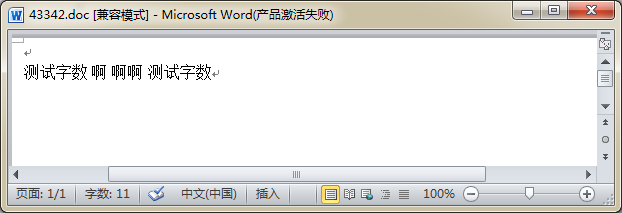
英文:在word中,英文的单词就是看你中间是否有分隔符来统计的.一般都是以空格来分割,不会校验你的单词是否正常.我觉得可以理解为一个英文字符串.有分隔符就算2个,没有连一起就算一个.
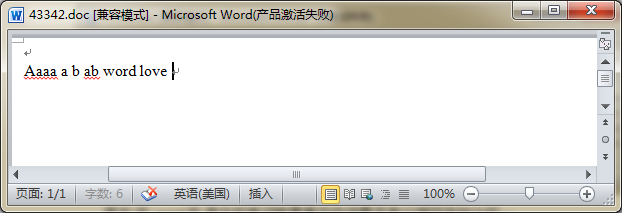
数字:数字的计算方式同英文的一样的.就不做过多的解释,上个示意图,看看效果.
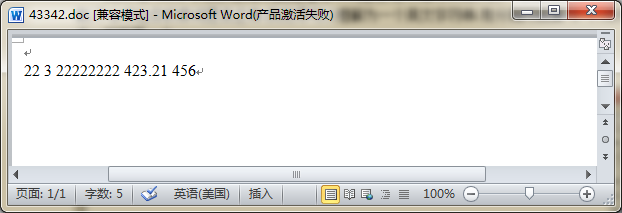
那么在看过word的统计结果之后,我们来看看代码层面的方法应该怎么编写.
中文:中文字数需要加上数字统计.代码实现如下.


1 public int GetChineseLeng(string StrContert) 2 { 3 if (string.IsNullOrEmpty(StrContert)) 4 return 0; 5 //此处进行的是一些转义符的替换,以免照成统计错误. 6 StrContert = StrContert.Replace("\n", "").Replace("\r", "").Replace("\t", ""); 7 //替换掉内容中的数字,英文,空格.方便进行字数统计. 8 int iChinese = getByteLengthByChinese(Regex.Matches(StrContert, @"[A-Za-z0-9][A-Za-z0-9'\-.]*").ToString().Replace(" ", "").Replace(" ", "")); 9 return Regex.Matches(StrContert, @"[0-9][0-9'\-.]*").Count + iChinese;//中文中的字数统计需要加上数字统计. 10 } 11 /// <summary> 12 /// 返回字节数 13 /// </summary> 14 /// <param name="s"></param> 15 /// <returns></returns> 16 private int getByteLengthByChinese(string s) 17 { 18 int l = 0; 19 char[] q = s.ToCharArray(); 20 for (int i = 0; i < q.Length; i++) 21 { 22 if ((int)q[i] >= 0x4E00 && (int)q[i] <= 0x9FA5) // 汉字 23 { 24 l += 1; 25 } 26 } 27 return l; 28 }
(可能有人会问我为什么中文字数统计需要进行字节数组的code码比对.因为我试验过几个正则,发现不是那么有效.这种在计算上是可以有效匹配的,字符集也比较大.如果大家有更好的方式可以留言给我.)
英文:英文则可以直接使用正则表达式来计算.代码实现如下:
1 public int GetEnglishLeng(string StrContert) 2 { 3 if (string.IsNullOrEmpty(StrContert)) 4 return 0; 5 StrContert = StrContert.Replace("\n", " ").Replace("\r", " "); 6 7 return Regex.Matches(StrContert, @"[A-Za-z][A-Za-z'\-.]*").Count; 8 9 }
这个就是直接根据正则表达式来匹配英文,是否存在分开或者间隔性的进行字数的统计.英文的计算方式在上文中也做了介绍.这里就不多描述.
这里还有一个问题需要说明一下.英文计算时,按照案例上来说.我们给的是纯文本的内容.那么不需要进行任何转义符的替换.而当传递过来的是整个HTML的话,在存储和显示上就要进行一道转义操作.而在计算中,我们则需要将这些转义符进行替换.因为照成错误的字数计算.
我们来看看带有转义符的计算在word中是个什么效果.
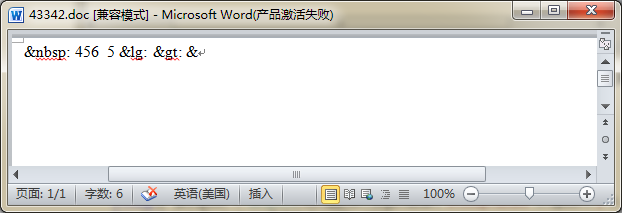
Word中对于这种标示符都记录为一个字数.所以为了在做数据比对时,字数统计要达到正常的情况.则需要进行一次转义符的替换.
代码如下:
1 public static int GetEnglishLeng(string StrContert) 2 { 3 if (string.IsNullOrEmpty(StrContert)) 4 return 0; 5 StrContert = StrContert.Replace("&", " "); 6 string[] arrSplit = Helpers.GetAppSettingsValue("strRepValues").Split(','); 7 for (int i = 0; i < arrSplit.Length; i++) 8 { 9 StrContert = StrContert.Replace(arrSplit[i], " "); 10 } 11 return Regex.Matches(StrContert, @"[A-Za-z][A-Za-z'\-.]*").Count; 12 13 }
这里取的是web.config中的配置字符串,进行循环替换. 先替换掉&的原因就是为了防止计算错误.
1 <appSettings> 2 <add key="strRepValues" value="\n,\r,nbsp;,lt;brgt;"/> 3 </appSettings>
因为首次进行博客园的文章发布,文章格式就不做特别的处理.便于大家快速阅读使用为主.如有因为或者更好的解决方案.欢迎留言.

















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









