



 本文介绍了如何使用SQL中的GROUP BY子句对数据进行分组,并利用HAVING子句进行高级过滤。通过实例展示了如何结合WHERE子句和ORDER BY子句进行数据筛选与排序。
本文介绍了如何使用SQL中的GROUP BY子句对数据进行分组,并利用HAVING子句进行高级过滤。通过实例展示了如何结合WHERE子句和ORDER BY子句进行数据筛选与排序。
本文将介绍如何分组数据,以便能汇总表内容的子集,这涉及两个新SELECT语句子句,分别是 GROUP BY 子句和HAVING子句。
1.1 创建分组
分组是在SELECT语句的GROUP BY子句中建立的。
输入:
SELECT vend_id,COUNT(*) AS num_prods
FROM products
GROUP BY vend_id输出:
| vend_id | num_prods |
|---|---|
| 1001 | 3 |
| 1002 | 2 |
| 1003 | 7 |
| 1005 | 2 |
分析:上面的SELECT语句指定了两个列,vend_id包含产品供应商ID,num_prods为计算字段(**用COUNT(*)函数建立**)GROUP BY 子句指示MySQL按vend_id排序并分组数据。这导致对每个vend_id而不是整个表计算num_prods一次。从输出看出,供应上1001有3个产品,供应商1002有2个产品,供应商1003有7个产品,而供应商1005有2个产品。
使用GROUP BY子句之前,需要知道一些重要规定:
- GROUP BY 子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有类都一起计算(所以不能从个别的列取回数据)。
- GROUP BY 子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECGT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外,在SELECT中的每个列都必须在GROUP BY子句中给出。
- 如果分组类中具有NULL值,则NULL将最为一个分组返回。如果类中有多行NULL值,他们将分为一组。
- GROUP BY 子句必须出现在WHERE子句之后,ORDER BY 子句之前。
? 使用ROLLUP 使用WITH ROLLUP 关键字,可以得到每个分组以及每个分组汇总级别(针对每个分组)的值,如下所示:
SELECT prod_id ,COUNT(*) AS num
FROM ACTIVITY20180508—UUUser
GROUP BY prod_id WITH ROLLUP输出:
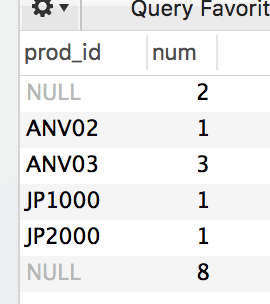
分析:
解释一下出现的两个null,第一个null 是prod_id的值为null的行数有2行,
最后一个null,是每个行数量的总和为8。
1.2 过滤分组
HAVING类似与WHERE,之前所有的类型的WHERE子句都可以用HAVING来替代,唯一的差别是WHERE过滤行,而HAVING过滤分组。
输入:
SELECT cust_id,COUNT(*) AS orders
FROM orders
GROUP BY cust_id
HAVUNG COUNT(*) >= 2;输出:
| cust_id | orders |
|---|---|
| 1000 | 2 |
分析:HAVING子句,它过滤COUNT(*)>=2(两个以上的订单)的那些分组。
✏️ HAVING和WHERE的差别 这里有另一种理解方法,WHERE数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中给予这些值过滤掉的分组。
HAVING和WHERE一起使用的例子:
列出具有2个(含)以上、价格为10(含)以上的产品的供应商:
输入:
SELECT vend_id ,COUNT(*) AS num_prods
FROM products
WHERE prod_price >= 10
GROUP BY vend_id
HAVING COUNT(*) >= 2
输出:
| vend_id | num_prods |
|---|---|
| 1003 | 4 |
| 1005 | 2 |
分析:WHERE子句过滤所有prod_price至少为10行。然后按vend_id分组数据,HAVING子句过滤计数2或2以上的分组。
不加HAVING过滤的结果是:
输入:
SELECT vend_id ,COUNT(*) AS num_prods
FROM products
WHERE prod_price >= 10
GROUP BY vend_id输出:
| vend_id | num_prods |
|---|---|
| 1001 | 3 |
| 1002 | 2 |
| 1003 | 4 |
| 1005 | 2 |
1.3分组和排序
ORDER BY 和 GROUP BY
| ORDER BY | GROUP BY |
|---|---|
| 排序产生的输出 | 分组行。但输出可能不是分组的顺序 |
| 任意列都可以使用(甚至非选择的列也可以使用) | 只可能使用选择列或表达式列,而且必须使用每个选择列表达式 |
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
?不要忘记ORDER BY 一般在使用GROUP BY子句时,应该也给出ORDER BY子句,以保证数据正确的排序。
例子:检索总计订单价格大于等于50的订单的订单号和总计订单价格:
输入:
SELECT order_num,SUN(quantity*item_price) AS ordertotal
FROM orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price ) >= 50
输出:
| order_num | ordertotal |
|---|---|
| 20005 | 149.87 |
| 20006 | 55 |
| 20007 | 1000.0 |
| 20008 | 125.0 |
为按总计订单价格排序输出,需要添加ORDER BY子句,如下所示:
输入:
SELECT order_num,SUM(quantity*item_price) AS ordertotal
FROM orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price ) >= 50
OREDER BY ordertotal输出:
| order_num | ordertotal |
|---|---|
| 20005 | 149.87 |
| 20006 | 55 |
| 20007 | 1000.0 |
| 20008 | 125.0 |
分析:在这个例子中,GROUP BY 子句用来按订单号(order_num列)分组数据,以便使用SUM(*)函数能够返回总计订单价格。HAVING子句过滤数据,使得只返回总计订单价格大于等于50的订单。最后,用ORDER BY 子句排序输出。
1.4 SELECT 子句顺序
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELET | 要返回的列或表达式 | 是 |
| FROM | 从检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
1.5 小结
本章讲述了如何使用GROUP BY子句对数据组进行汇总计算,返回每个组的结果。我们看到了如何使用HAVING子句过滤特定的组,还知道了ORDER BY 和GROUP BY 之间以及WHERE 和HAVING 之间的差异。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









