






 本文介绍了一种通过Shingling和MinHash技术计算文档相似度的方法。首先利用k-shingle提取文档特征,然后采用MinHash算法减少计算复杂度,进而快速评估两篇文档的相似性。该方法广泛应用于推荐系统、论文查重等领域。
本文介绍了一种通过Shingling和MinHash技术计算文档相似度的方法。首先利用k-shingle提取文档特征,然后采用MinHash算法减少计算复杂度,进而快速评估两篇文档的相似性。该方法广泛应用于推荐系统、论文查重等领域。
1.Shingling+MinHash
2. Learning to Hash
1.Introduction
很多的网页挖掘问题都可以表述为寻找相似集合:
- 论文查重;
- 推荐系统;
2.Finding Similar Documents
流程: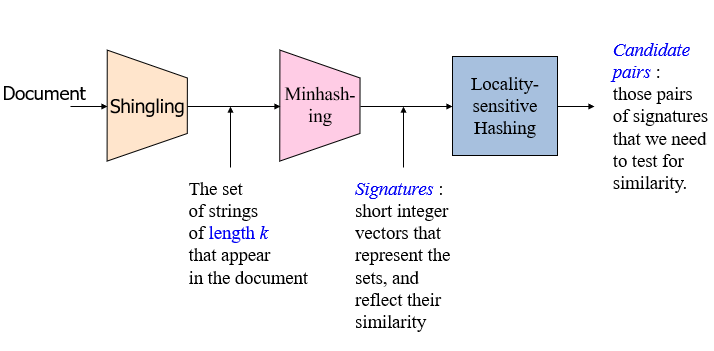
2.1 Shingles
k-shingle(or k-gram)是文件中出现的k个字。通常使用一个文件的k-shingle集合来表示这个文件。
举例:k =2, doc = abcab。Set of 2-shingles = {ab, ac, bc, ca}
注意:k要尽量取的大一些,否则大多数的文档会产生很多shingles。
-k=5适用于小文档;k=10适用于大文档。
2.2 Min-Hashing
2.2.1
基础数据模型:集合
Jaccard Similarity of sets
杰卡德相似性是集合的交集除以他们的并集。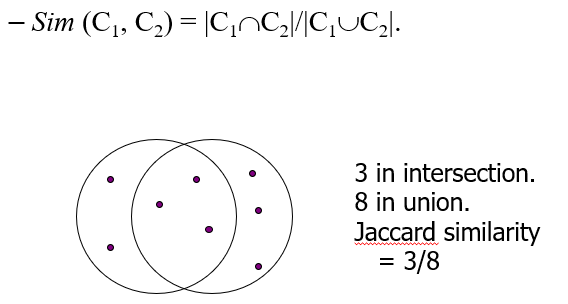

2.2.2 Outline of Min-Hashing
- 计算每一列的签名 = 对每一列进行总结;
- 发现成对签名;
检查具有相似签名的列的确是相似的。


签字
- 每一列是随机置换的;
- 定义hash函数为h(C)=the number of the first(in the permuted order) row in which column C has 1.
用几个独立的hash函数构建签名。
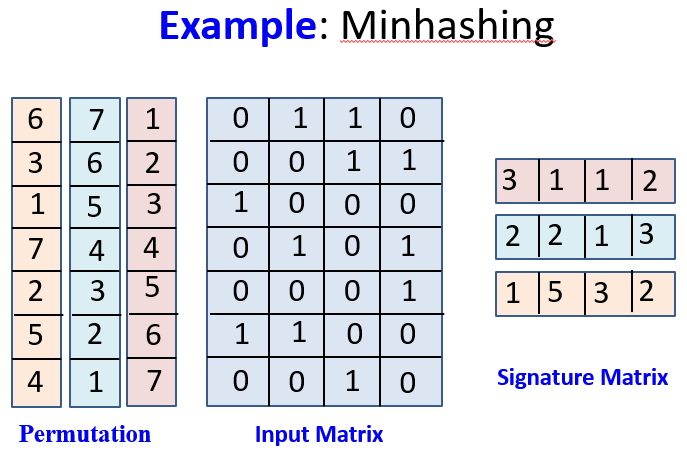
特性
h(C1)=h(C2)的概率与Sim(C1, C2) = a/(a+b+c)
Implementation
如果有10000行数据的话,要进行随机置换也是很困难的。可以使用不同的函数来代替每一次的置换。
Notation:
M(i, C) the smallest value of hi(r) for which column c has 1 in row r
hi(r) gives order of rows for ith permuation
---
伪代码:
Initialize M(i,c) to \infity for all i and c
for each row r
for each column c
if c has 1 in row r
for each hash function hi do
if hi(r) is a smaller value than M(i, c)
then
M(i, c) := hi(r);Example:

















 4270
4270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









