






 本文介绍了数据处理中的几种关键模式,包括简单随机抽样、布隆过滤、Top10及去重等,这些模式有助于从大数据集中提取有价值的信息,提高机器学习算法的效率。
本文介绍了数据处理中的几种关键模式,包括简单随机抽样、布隆过滤、Top10及去重等,这些模式有助于从大数据集中提取有价值的信息,提高机器学习算法的效率。
简单随机抽样
:是过滤的一个常见应用,比如提取某字段最高记录,或者随机抽取几条。 抽样可以用来得到
更小的,更具有代表性的数据子集
。
很多机器学习算法在大数据集上运行不够高效,所以需要为提取较小的数据子集
创建新的模式。
当选取的比例是一个很小值的时候,你会在输出结果中发现大量的小文件,如果遇到这种情况
1
可以设置 reduce 数目为1, 并且不指定 reduce 类。 这就是要求 MapReduce 框架使用一个 identity reduce 简单的手机输出并写到一个文件中。
2 hdfs dfs -cat 将输出文件收集到一起。
布隆过滤
: 对每一条记录抽取其中一个特征,如果特征是布隆过滤器集合中的成员或非成员就保存或丢弃。 作用是预先判定值列表成为热门值的集合( hot values);
使用步骤:1 布隆过滤器训练,2 使用布隆过滤器
布隆过滤使用场景1:
给定一个用户评论列表,过滤掉声望值小于1500的用户 发出的评论。
Mapper.setup(){ bloomFilter()} : 在所有 mapper() 执行之前,会先执行 setup()。 在 setup() 中用 布隆过滤器 过滤不属于bloomFilter方法过滤 1500 的用户ID。 bloomFilter 初始化后,setup 会产生一个 HBase 表的连接。
Mapper.mapper() : 数据通过 bloomFilter() 过滤后 继续使用 ID 到 HBase 进行查询。。
布隆过滤使用场景2:
需要一个全量的两个百亿级文件的对比 A 文件百亿行 B 文件百亿行。 每行字符串大小在50KB。
Mapper.setup(){ bloomFilter } 这里的 bloom 过滤器作用是 将每行 50KB的数据进行压缩 变成一个 shar1 或者 MD5 这样便于存储在内存内,而不至于撑爆内存。
Top10
:
Top10场景:
异类分析、
热点分析
特性: 1 Top 方式的分界线是模糊的。 优势 不必全部排序。 如 hive select x from xxx desc limit 10.
2 需要配置 作业为 一个
reduce
。
Map code :
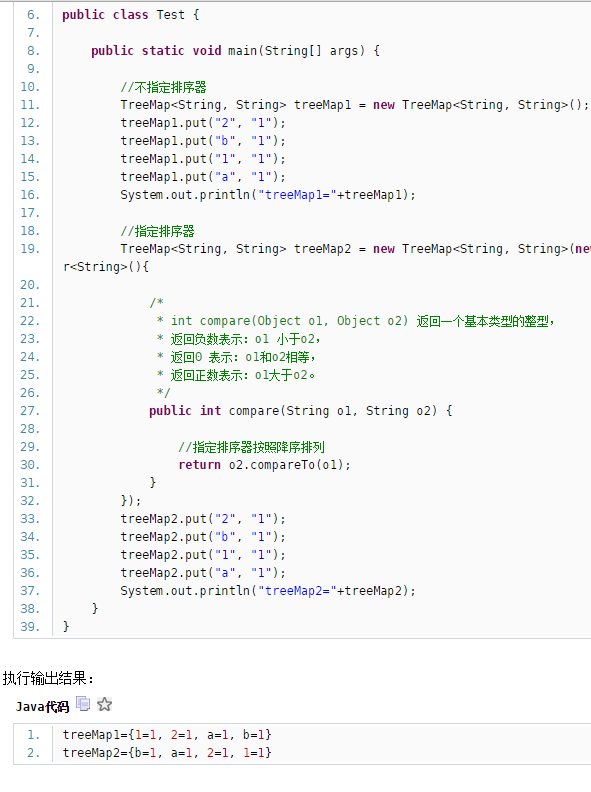
1 map() 创建一个 TreeMap
2
map()
添加数据进入 TreeMap。 每次判断是否大于10 大于10 则 treeMap.remove(treeMap.firstKey());
3 cleanup() 中遍历 TreeMap数据。 循环写出。 等待 Reduce shuffer
去重
:
这个不难理解,就是去除重负记录,MR结构式 M 做数据转换,利用 combiner 做去重,reduce
使用场景:
1 数据去重 2 抽取重复值 3 规避内连接的数据膨胀。(如果你在两个数据集之间做一个内连接,并且外检不唯一, 数据A 3000个 数据B 2000 个 最终将是 6 百万记录。 这么多的记录将会集中发给 reduce。 通过使用去重。可以减轻数据膨胀)。
性能:
主要考虑 reduce 数目。 从 map 过来的字节数取决于 conbiner 可以消除多少数据。 如果重复记录少见,差不多所有数据都会发送到 reduce 端。 最好的情况是每个 reduce 收到的记录量不小于一个 block 大小。 对于非常大的数据集,可以考虑两倍于集群 reduce 槽容量的大小。
MR code:
比如一个只关心用户ID去重。 用户ID 做键, null 作为值。
M
: 将数据读取,ID左键, null 做值。
job中 设置 combiner。 重复键移除
R : 得到去重 ID 后的操作。

















 7556
7556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









