






 本文介绍了一个简单的Python爬虫项目,该项目旨在抓取好大学排行网站上的大学排名数据,并将其保存为CSV文件。爬虫利用了HTTP请求、BeautifulSoup库解析HTML,从网页中提取了大学名称、位置等信息。
本文介绍了一个简单的Python爬虫项目,该项目旨在抓取好大学排行网站上的大学排名数据,并将其保存为CSV文件。爬虫利用了HTTP请求、BeautifulSoup库解析HTML,从网页中提取了大学名称、位置等信息。
简单的了解了一下python爬虫的知识:HTTP协议、robots协议、requests库、beautifulsoup库、提取信息的方法。
爬取好大学排行的大学排名数据,并存储到csv文件中。
数据所在的结构如下:
<tr class="alt"> <td>1 #网页中缺少了td,生成数据的时候补上
<td><div align="left">清华大学</div></td>
<td>北京</td><td>94.0 </td>
<td class="hidden-xs need-hidden indicator5">100.0 </td>
<td class="hidden-xs need-hidden indicator6" style="display:none;">97.70%</td>
<td class="hidden-xs need-hidden indicator7" style="display:none;">40938</td>
<td class="hidden-xs need-hidden indicator8" style="display:none;">1.381</td>
<td class="hidden-xs need-hidden indicator9" style="display:none;">1373</td>
<td class="hidden-xs need-hidden indicator10" style="display:none;">111</td>
<td class="hidden-xs need-hidden indicator11" style="display:none;">1263428</td>
<td class="hidden-xs need-hidden indicator12" style="display:none;">613524</td>
<td class="hidden-xs need-hidden indicator13" style="display:none;">7.04%</td>
</tr>
获取网页数据(使用request)---->使用BeautifulSouup处理网页,并写入列表中存储------->写入CSV文件;
import requests from bs4 import BeautifulSoup import bs4 import csv def getHTML(url): try: r = requests.get(url) print(r.status_code) r.raise_for_status() r.encoding = r.apparent_encoding with open('aaa.html', 'wb') as f: f.write(r.content) f.close() return r.text except: return ''
这个函数遇到的问题挺多的:
在提取首行标题的时候,Tag对象还是字符串没有搞清楚;
创建csv加入newline = ‘’,不会产生空行
def fillUniverList(ulist,HTML): rank = 0 ulistFirst = [] soup = BeautifulSoup(HTML,'html.parser') thead = soup.find('thead') tr = thead.find('tr') # print(tr) for th in tr('th'): # if th['style'] == "text-align:center;": # ulistFirst.append(th.string) if isinstance(th,bs4.element.Tag): if th['style'] == "text-align:center;": ulistFirst.append(th.string) else: for select in th('option'): ulistFirst.append(select.string) # print(ulistFirst) ulist.append(ulistFirst) for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): rank += 1 tds = tr('td') ulist.append([rank, tds[1].string, tds[2].string, tds[3].string, \ tds[4].string, tds[5].string, tds[6].string, tds[7].string, tds[8].string, \ tds[9].string, tds[10].string, tds[11].string, tds[12].string]) def printUniverList(ulist): for univer in ulist: print(univer) def storeInCSV(ulist): with open('univer.csv','w',newline = '') as csvfile: writer = csv.writer(csvfile) writer.writerow([1,2,3,4]) for univer in ulist: writer.writerow(univer) csvfile.close() def main(): ulist = [] url = 'http://zuihaodaxue.cn/zuihaodaxuepaiming2017.html' HTML = getHTML(url) fillUniverList(ulist,HTML) # printUniverList(ulist) storeInCSV(ulist) main()
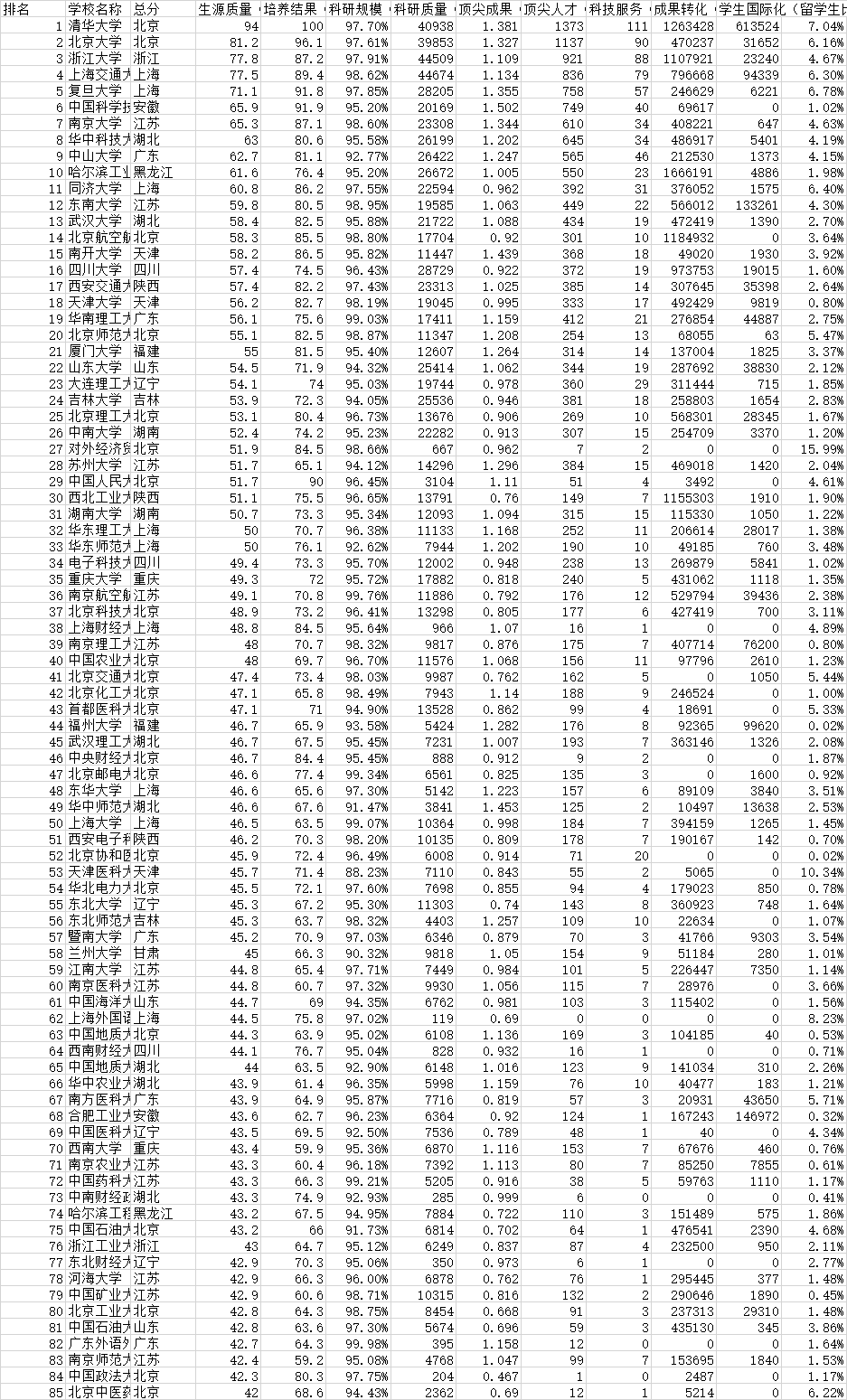
结果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









