






 本文通过实例比较了在SQL查询中使用IN关键字与INNER JOIN在处理大量数据时的不同性能表现,尤其是在I/O操作方面。
本文通过实例比较了在SQL查询中使用IN关键字与INNER JOIN在处理大量数据时的不同性能表现,尤其是在I/O操作方面。
在以逗号拼接而成的字符串,传入给IN字句的元素字符串中包涵了1400多个元素
两种做法分别为
AND e.ssPfCityId IN (
SELECT
CAST(value AS INT)
FROM STRING_SPLIT('110000,310000,120000,210100,210200,210400,210800,211200,350100,350500,350200,350800,350700,350900,441200,441300,440500,445100,450100,451000,450800,450300,451100,450200,450900,450500,450400,450600,460100,510100,...'
,',')
)
INNER JOIN (SELECT DISTINCT CAST(value AS INT) AS VALUE FROM STRING_SPLIT('110000,310000,120000,210100,210200,210400,210800,211200,350100,350500,350200,350800,350700,350900,441200,441300,440500,445100,450100,451000,450800,450300,451100,450200,450900,450500,450400,450600,460100,510100,...',',') T) T ON e.ssPfCityId = T.VALUE
对比看出如果用IN字句会用一个HASH MATCH的聚合操作符,而用INNER JOIN则用DISTINCT SORT。
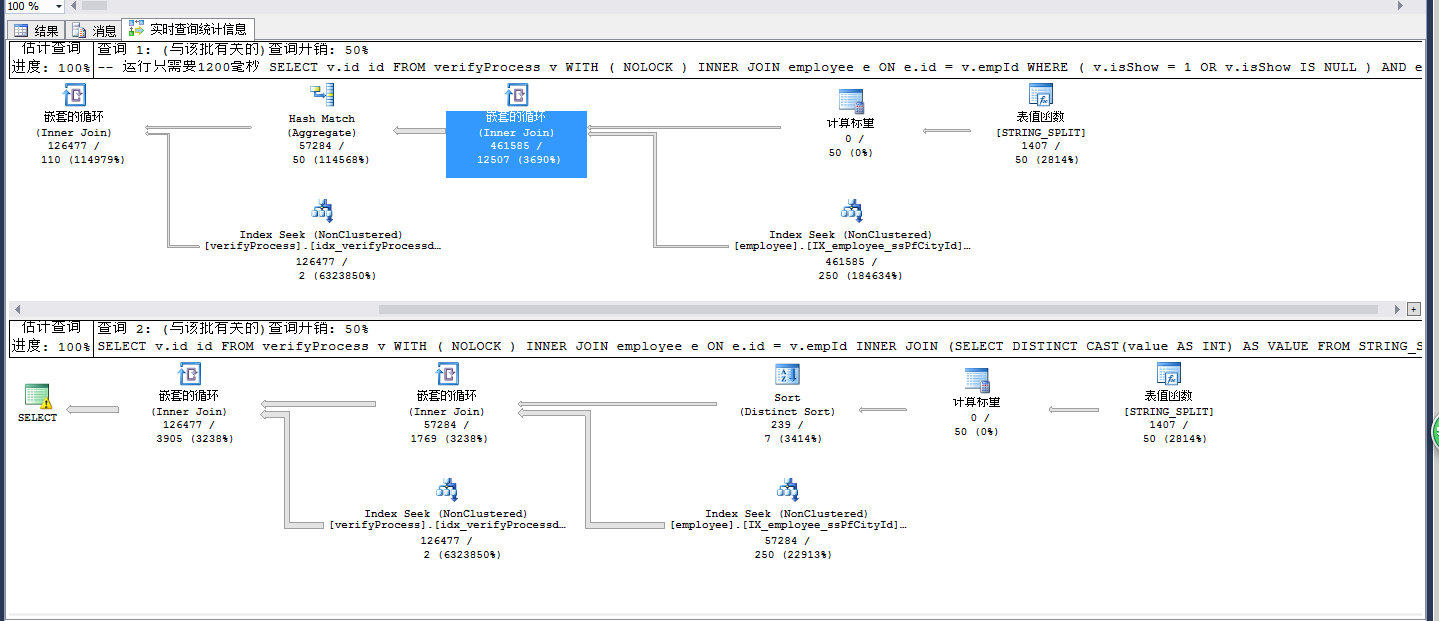
而如果对比IO统计数据可以发现IN字句的做法多出了许多Workfile产生的IO
(128478 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 577 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Workfile'。扫描计数 70,逻辑读取 2424 次,物理读取 172 次,预读 2268 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'employee'。扫描计数 9,逻辑读取 4559 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'verifyProcess'。扫描计数 9,逻辑读取 3136 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
而用INNER JOIN则么有Workfile产生的IO
(128478 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Workfile'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'employee'。扫描计数 9,逻辑读取 4559 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'verifyProcess'。扫描计数 9,逻辑读取 3136 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这个例子的性能看上去总时间开销差别并不是很明显,因为连接的表数量少,而如果连接的表数量多起来,可能整个执行计划会是另一回事,那个时候IN字句的弊端就显现了。

















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









