



一、基本信息
1.本次作业的地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
2.项目 Git地址:https://gitee.com/ntucs/PairProg
3.结对同学:1613072053李俊杰 1613072054政路航
二、项目分析
1.读文件到缓冲区
def process_file(dst): # 读文件到缓冲区 try: # 打开文件 f = open(dst, "r") except IOError as s: print(s) return None try: # 读文件到缓冲区 bvffer = f.read() except: print("Read File Error!") return None f.close() return bvffer
2.统计行数
def process_line(dst): # 统计行数 count = 0 for line in open(dst, 'r').readlines(): if line != '' and line != '\n': count += 1 return 'lines:', count
3.用正则表达式筛选合格单词并统计
def process_buffer(bvffer): if bvffer: word_freq = {} # 将文本内容都小写 bvffer = bvffer.lower() # 用空格消除文本中标点符号 words = bvffer.replace(punctuation, ' ').split(' ') # 正则匹配至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写 regex_word = "^[a-z]{4}(\w)*" # 停词表模块 txtWords = open("stopwords.txt", 'r').readlines() # 读取停词表文件 stopWords = [] # 存放停词表的list for i in range(len(txtWords)): txtWords[i] = txtWords[i].replace('\n', '') stopWords.append(txtWords[i]) for word in words: if word not in stopWords: # 当单词不在停词表中时,使用正则表达式匹配 if re.match(regex_word, word): # 数据字典已经存在该单词,数量+1 if word in word_freq.keys(): word_freq[word] = word_freq[word] + 1 # 不存在,把单词存入字典,数量置为1 else: word_freq[word] = 1 return word_freq, len(words)
4.输出出现频率前十的单词并保存到文件
def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print("<%s>:%d " % (item[0], item[1])) f = open("result.txt", 'w') print("<%s>:%d " % (item[0], item[1]), file=f) f.close()
5.主函数main()
def main(): parser = argparse.ArgumentParser() parser.add_argument('dst') args = parser.parse_args() dst = args.dst bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
6.调用主函数
if __name__ == "__main__": import cProfile import pstats cProfile.run("main()", filename="wordcount.out") p = pstats.Stats('wordcount.out') # 创建Stats对象 p.sort_stats('calls').print_stats(10) p.strip_dirs().sort_stats("cumulative", "name").print_stats(10) # 按执行时间次数排序 p.print_callers("process_file") # 想知道有哪些函数调用了process_file p.print_callers("process_buffer") # 想知道有哪些函数调用了process_buffer p.print_callers("output_result") # 想知道有哪些函数调用了output_result
三、程序运行截图及性能分析
1.运行截图

2.耗时最多、运行次数最多的函数
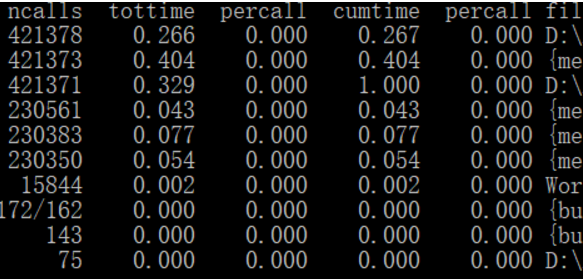
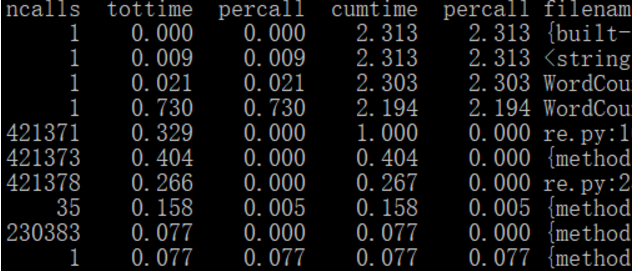
3.时间复杂度O(N+n),空间复杂度O(2n)
四、其他
1.因为我们两个人的基础都并不是很好,所以所花的时间也比较多,基本每天花费三四个小时查找资料,然后写程序
2.结对编程照片

五、事后分析与总结
1.一开始并不知道怎么做,后经过参考并学习了正则表达式。
2.政路航对李俊杰评价:虽然对Python语言不熟悉,理解力也不强,但积极查阅资料,帮助我完成代码的编写。希望以后还能一起努力学习帮助。
李俊杰对政路航评价:两个人的基础都比较薄弱,但他对语言的学习力和理解力较强,主动承担起困难代码的编写。这次结对编程也加深了我们之间的交流。
3.关于结对编程的建议
两个人合作永远要比一个人单干要轻松,但由于我们两个人的基础都相对薄弱,所以在查阅学习的功夫上花了不少时间。但也能起到相互督促的作用
总之,希望以后也能多多合作,相互协助,一起努力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









