 Hadoop集群配置与启动
Hadoop集群配置与启动




 本文介绍了Hadoop集群的配置步骤,包括公钥与私钥的分发、配置文件的修改、环境变量的设置及配置文件的分发。此外还详细讲解了如何格式化namenode、启动Hadoop集群以及常用的HDFS命令。
本文介绍了Hadoop集群的配置步骤,包括公钥与私钥的分发、配置文件的修改、环境变量的设置及配置文件的分发。此外还详细讲解了如何格式化namenode、启动Hadoop集群以及常用的HDFS命令。
上次已经在集群的各个节点生成了公钥、私钥,然后将公钥发放到了其他所有节点。
接下来将要修改hadoop的配置文件以下7个:
hadoop2.7/etc/hadoop/hadoop-env.sh
hadoop2.7/etc/hadoop/yarn-env.sh
hadoop2.7/etc/hadoop/core-site.xml
hadoop2.7/etc/hadoop/hdfs-site.xml
hadoop2.7/etc/hadoop/mapred-site.xml
hadoop2.7/etc/hadoop/yarn-site.xml
hadoop2.7/etc/hadoop/slaves
在目录/home/hadoop下面。
1.修改配置文件
a)hadoop-env.sh 和 yarn-env.sh
vim etc/hadoop/hadoop/hadoop-env.sh
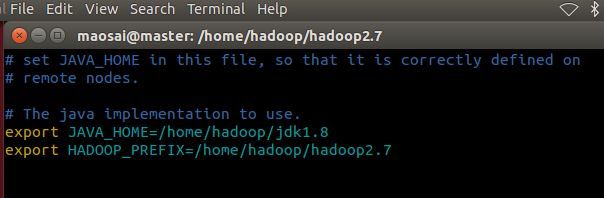
vim etc/hadoop/yarn-env.sh
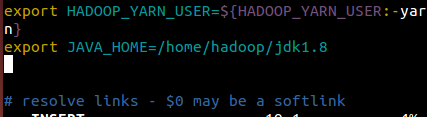
b)core-site.xml
vim etc/hadoop/core-site.xml
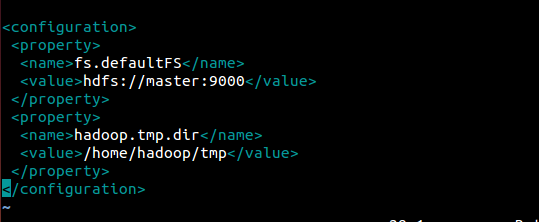
其中hdfs://master:9000是必要部分,其他为默认值,可以不用写。
c)hdfs-site.xml
vim etc/hadoop/hdfs-site.xml
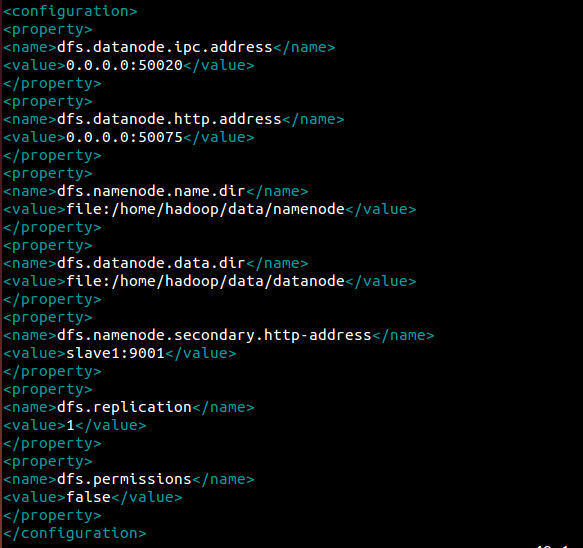
其中dfs.replication
<value> 1 </value>
是必要的,其他为默认配置,也可以不用写。
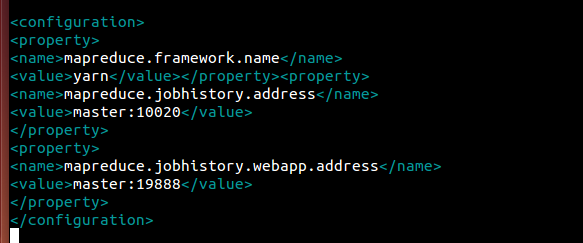
d)mapred-site.xml (有mapred-site.xml)
vim etc/hadoop/mapred-site.xml
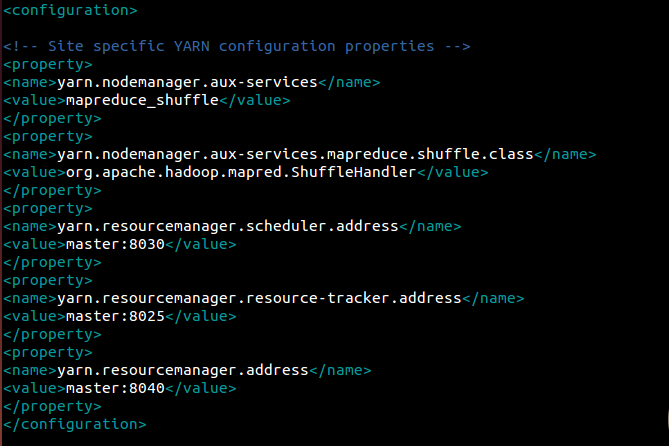
e)yarn-site.xml
vim etc/hadoop/yarn-site.xml
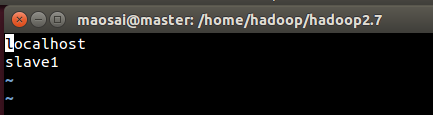
f)slaves
vim etc/hadoop/slaves
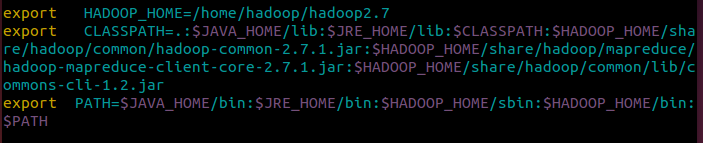
g)修改/etc/profile设置环境变量
vim /etc/profile
h)分发到集群的其他机器
使用scp命令,将hadoop2.7文件夹连同修改后的配置文件,通过scp拷贝到slave1机器上。
$scp -r hadoop2.7/ maosai@slave1:hadoop2.7
2.格式化namenode
$hdfs namenode -format
有出现has been successfully formatted表示格式化ok
3.启动hadoop集群
$HADOOP_HOME/sbin/start-dfs.sh
启动完成后,使用jps查看进程:$jps
在master上:
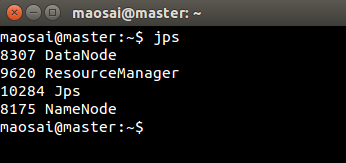
在slave1上:
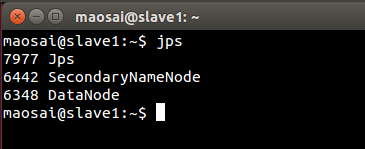
因为数据分布的原因,并没有规定哪台机器上必须有哪个进程出现,只要两台机器上一共存在这些进程就可以了。
使用start-dfs.sh和stop-dfs.sh就可以启动和停止hdfs文件系统。
HDFS命令:
在启动HDFS 之后,start-dfs.sh,
使用命令hadoop fs -<原Linux命令> 就可以在hdfs上进行操作,可以实现Linux与HDFS进行交互操作。
常用的HDFS命令:
(1)上传文件put(将Linux本地系统上传到HDFS上)
hadoop fs -put <Linux本地文件> <HDFS文件>
例如:hadoop fs -put /tmp/test /test/two
(2)下载文件get(将HDFS上的文件复制到Linux本地系统上)
hadoop fs -get <HDFS文件> <Linux本地文件>
例如:hadoop fs -get /test/one /tmp/testget
(3)显示目录下的文件ls
hadoop fs -ls <HDFS目录>
例如:hadoop fs -ls /test
(4)新建目录mkdir
hadoop fs -mkdir <目录>
例如:hadoop fs -mkdir /test/three
(5)删除文件rm
hadoop fs -rm <目录>
例如:hadoop fs -rm /test/three


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









