






设计策略
我这三次作业在设计策略上基本没有区别,都是设置输入线程InputHandler、电梯线程Elevator,然后将调度器Dispatch作为输入线程和电梯线程的共享对象。

第一次作业:傻瓜电梯
在调度器中设置一个保存请求的ArrayList,每当InputHandler中获取到了一个新的请求,就将其保存到调度器的ArrayList中。每当电梯空闲,就从调度器的请求队列中取一条直接执行,若请求队列为空则反复循环请求。
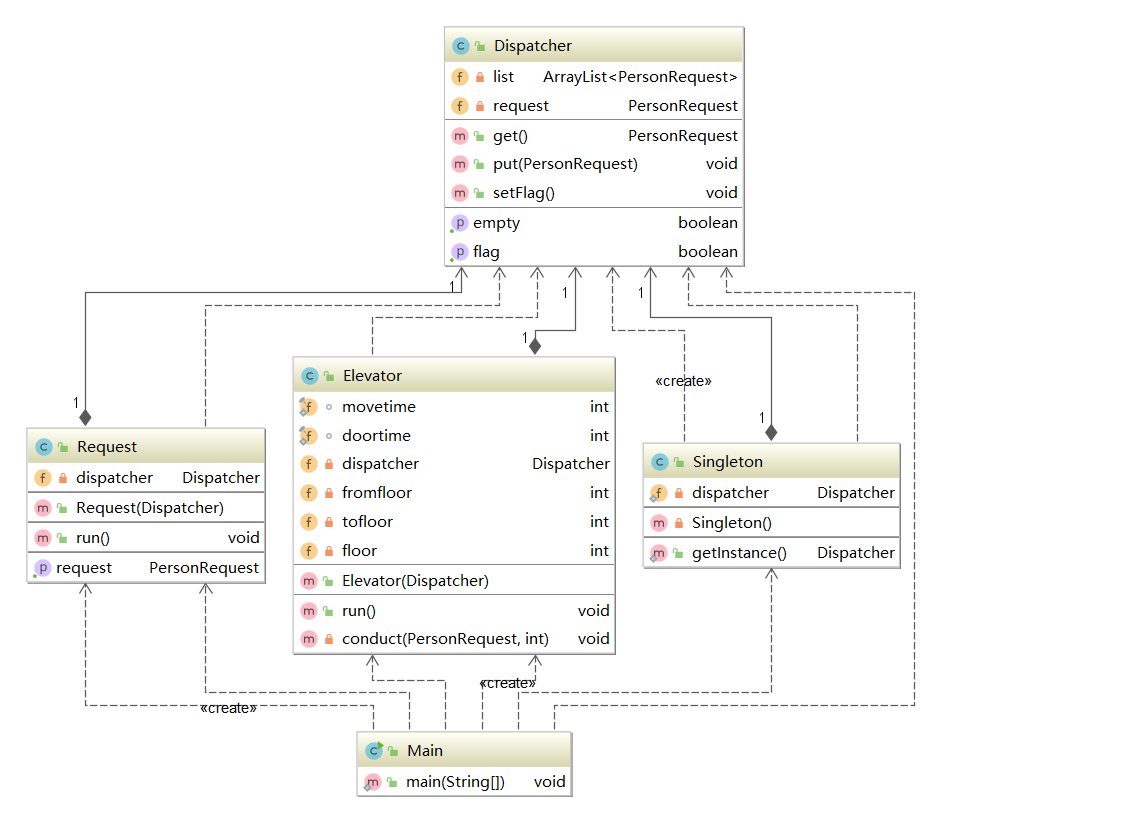
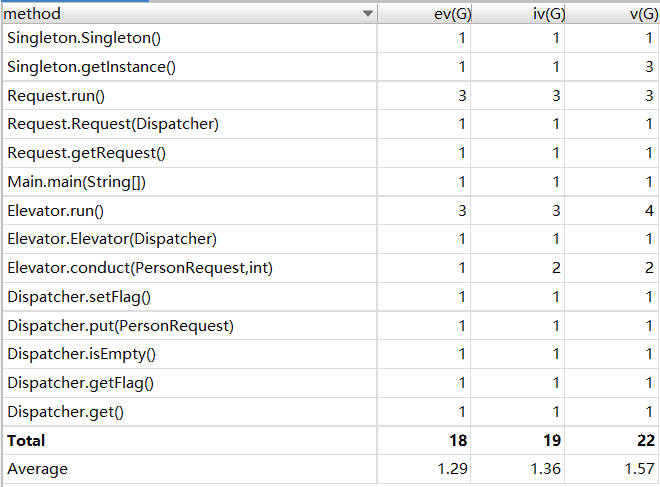
第二次作业:捎带电梯
电梯内部设置一个待执行队列,每次电梯空闲时,从调度器请求队列中取出队头请求放到电梯队列里作为电梯的主请求。每次电梯停靠到一层楼,就查找本层是否有能捎带的请求,如果有在目的地为本层的人就让他下电梯,如果是主请求的乘客下了电梯,就让之后的捎带请求升级为主请求。如此循环,直至电梯空闲且调度器请求队列为空且输入结束时结束电梯线程。
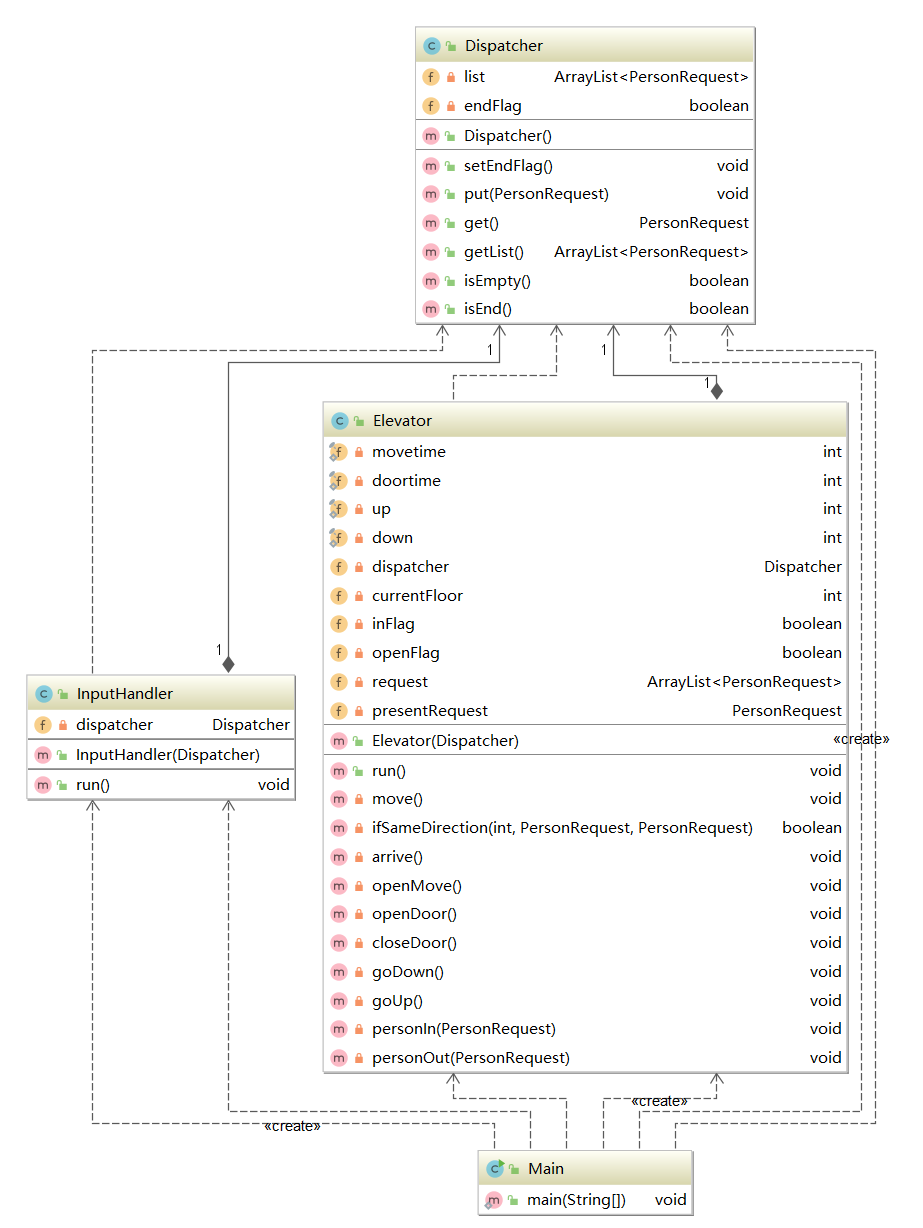
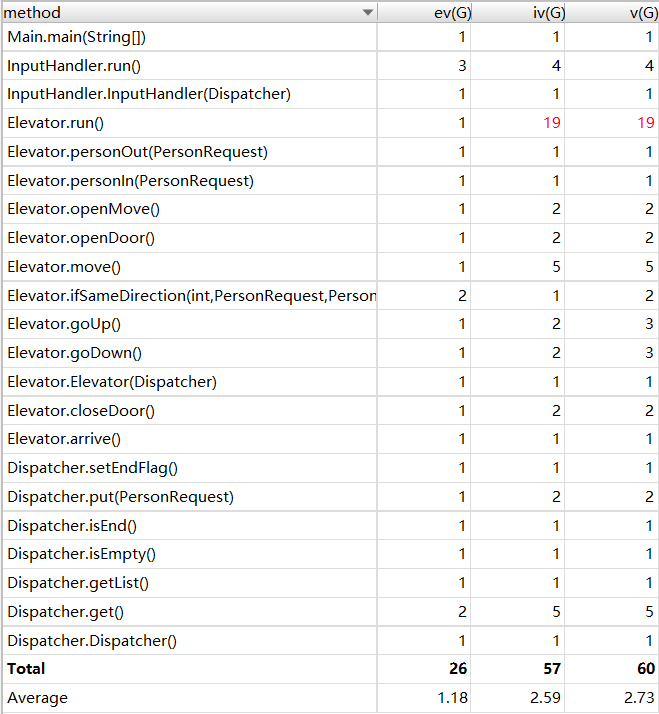
第三次作业:多部捎带电梯
采用了一种基本没有优化的方法。调度器内部为每个电梯设置一个请求队列,再设置一个用于保存“需换乘请求”的队列。每当输入线程取得一条新的指令,就对其进行分析,分配给某部电梯的请求队列或者“需换乘请求”的队列(所有需换乘请求都只需要换乘一次)。而如果某部电梯空闲,它就会从它的请求队列中或者从“需换乘请求”队列中取得。针对需换乘请求,由于乘客id的唯一性,将所有需换乘请求的id存入一个队列,若此请求的前半段被执行完成(该person走出电梯),则将该id从队列中删除,电梯也不能取得一个id在此队列中的请求。
不过为了便于编写,我的程序还是过于“硬编码”,将电梯的停靠楼层信息全部直接保存在了调度器中,而且调度器中的各种判断是基于对电梯的直接if-else选择的。而且只能处理换乘一次的情况。
关于共享资源
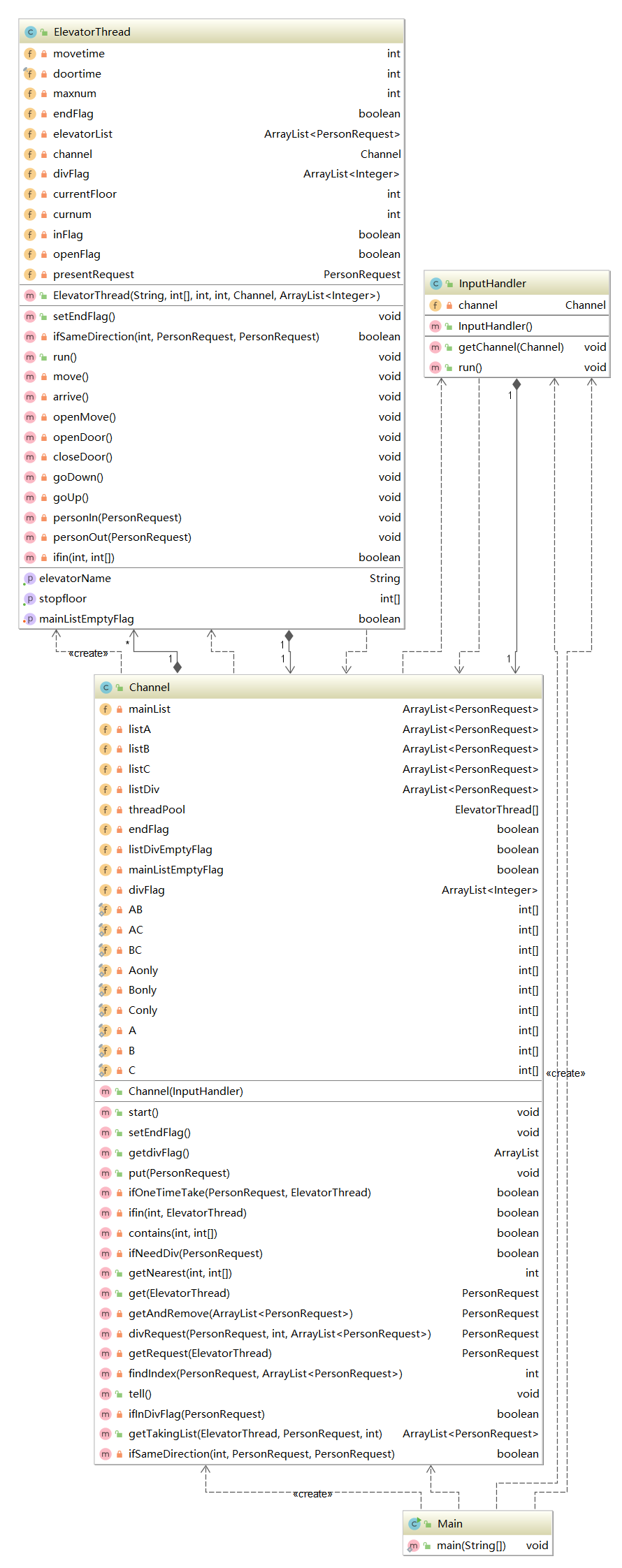
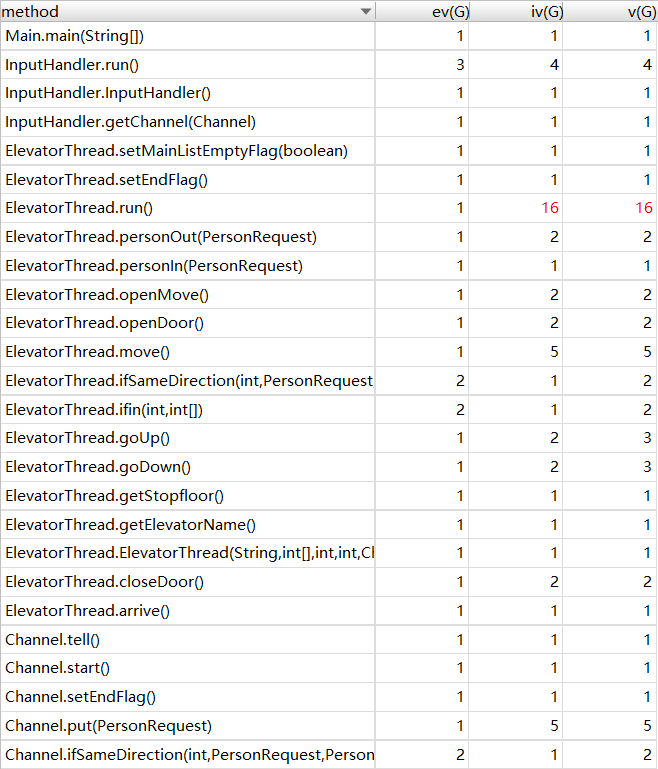
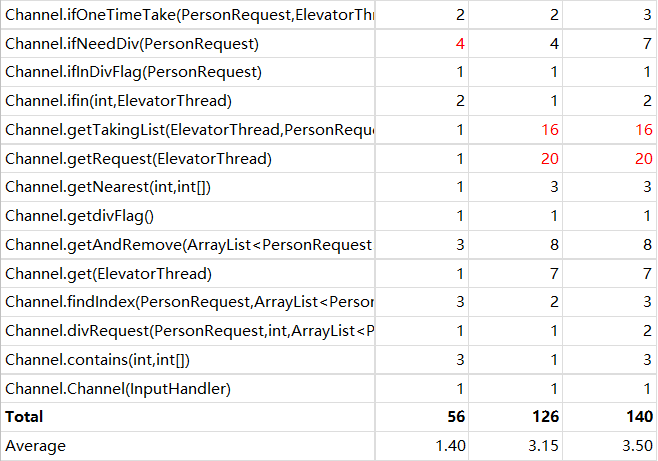
在本单元的作业中,显然共享资源是调度器中的请求队列,由输入线程和电梯线程共享,调度器中的所有方法都是针对这个队列的,因此我选择对调度器类暴力synchronized。
关于同步锁
在第一次作业中,采用暴力轮询的方式,若电梯为空闲状态则反复向调度器请求一个新的请求。
在第二次作业和第三次作业中,为了减少CPU时间,使用wait()和notifyAll()结合的方式,若电梯为空闲状态则向调度器请求一个新的请求,若此时发现调度器的请求队列为空则进入wait()。同时,每次InputHandler中取得一个新的请求,则将其放入调度器的请求队列中,并notifyAll()。
在第三次作业中还出现了一个问题:基于以上的调度方法,每当有乘客出电梯时就应该判断这个人是否为需换乘id,如果是,则要将此人的id从divFlag队列中删除,并且notifyAll(),因为要执行它的后半段行为的电梯可能正因为没有可执行的请求而wait()等待着。这就涉及如何开锁了,因为只有电梯能知道personOut的对象,但是并不能在电梯的方法中notifyAll()。这个地方我并不清楚应该如何正确解决,我采用的方法还是让电梯通过方法通知调度器,在调度器中notifyAll()。
存在的bug
第一次作业中没有发现bug。
第二次作业中我的电梯主要在两方面存在bug,一方面是电梯是否能够正确运行,另一方面则是多线程是否能够正确同步。
印象最深的一个bug是在其他所有测试样例都没有问题的情况下被别人hack出的一个错误,测试样例如下:
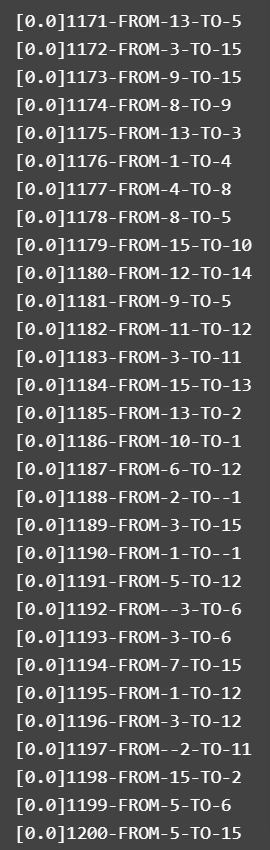
可以看到这个测试样例的测试数据量非常大,请求的情况也非常复杂,也因此才暴露出了我的程序中一处判断条件不完善的问题。
要实现运行的正确性,首先,基于上文中已经说明的基本实现逻辑,一定要保证考虑到各种可能的情况。譬如,在电梯线程中有一个保存电梯正在执行请求的队列,其中的捎带请求都是在到达各层后对该层已有请求的判断后加入的,因此可以保证这些请求的乘客一定进入了电梯;但是这个队列中最初的主请求是从调度器中的请求队列中直接取来的,不能保证这个电梯在到达主请求的toFloor时该请求的乘客是否一定进入了电梯。因此,这里就需要加入更多的判断条件来保证正确性。但与此同时,run方法的一次循环行为中会存在过多的判断条件、不能很好地体现面向对象的思想。其次,则是在每一步的执行时是否判断队列是否为空(也许可以在操作队列前都进行暴力判断一下)。其实我认为程序的正确性不只和是否考虑周密相关,更和根本的逻辑架构相关,一个清晰严密的架构会大大降低出错的可能性,我在我的程序中为了方便,没有单设主请求变量,而是直接将电梯内部的请求队列的首个元素作为主请求,其后的元素作为捎带请求,这种架构其实有不少潜在的问题。
在我的程序中,线程的同步问题中最大的bug来自程序不能平稳结束。在最初的程序中,如果输入结束,程序就会锁在wait()中无法释放。不知为何,这个问题没有影响到第二次作业的评测,但是在第三次作业的评测中则会显示全部超时,我这才回过头来修改关于输入结束的相关逻辑。最终的解决方法是将输入为null时只置endflag,改为输入为null时置endflag且将null作为最后一条请求传给电梯、电梯满足某些条件时停止循环运行。(在第三次作业中多部电梯能否先后平稳结束非常重要)
心得体会
这次是我第一次接触多线程编程,对于多线程的认识也在一次次不断的发现错误和解决错误的过程中不断加深。特别是在解决线程平稳停止的过程中真正理解了wait()和notifyAll()的作用。不过为了方便编程我也使用了很多比较投机取巧的暴力方法,因而没有实践更多的知识,比如对象锁的实现和共享资源的灵活处理。而且就我的程序结构来说目前并没有发现很多线程安全的问题,因而也没有获得更多这方面的经验。
关于设计原则,我深刻地认识到了这一点:一个好的设计架构可能在前期耗费大量的精力,但是会在扩展性方面很有优势。为了按时完成任务我选择了速度而非设计架构,我想在以后的编码过程中应当多注意这方面。

















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









