 轨迹优化与策略搜索
轨迹优化与策略搜索







 本文探讨了模型与现实不匹配及梯度爆炸等问题,并讨论了动力学系统的复杂性及其对反向传播的影响。文章还研究了如何将轨迹优化方法应用于策略优化中,特别是在涉及相机观测和关节速度的情况下。
本文探讨了模型与现实不匹配及梯度爆炸等问题,并讨论了动力学系统的复杂性及其对反向传播的影响。文章还研究了如何将轨迹优化方法应用于策略优化中,特别是在涉及相机观测和关节速度的情况下。



There are some problems: mismatch of model and reality; gradient explosion
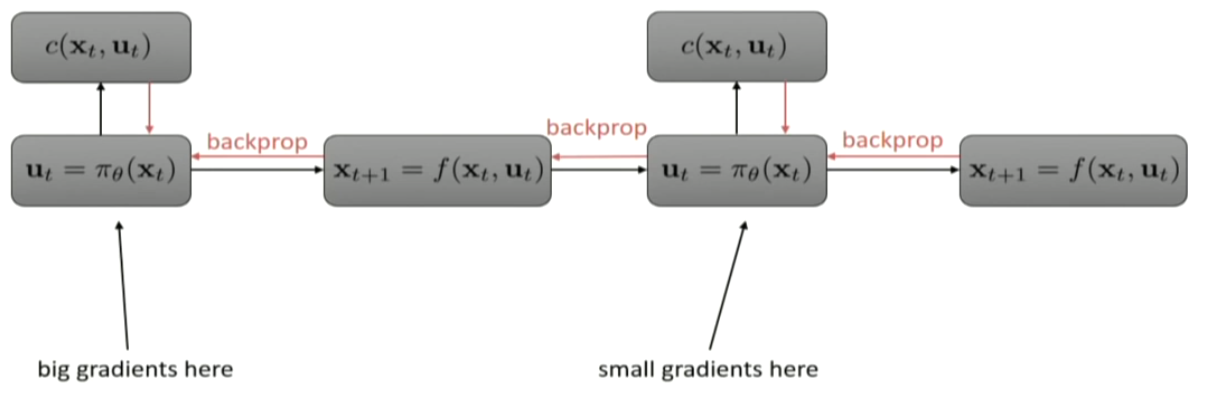
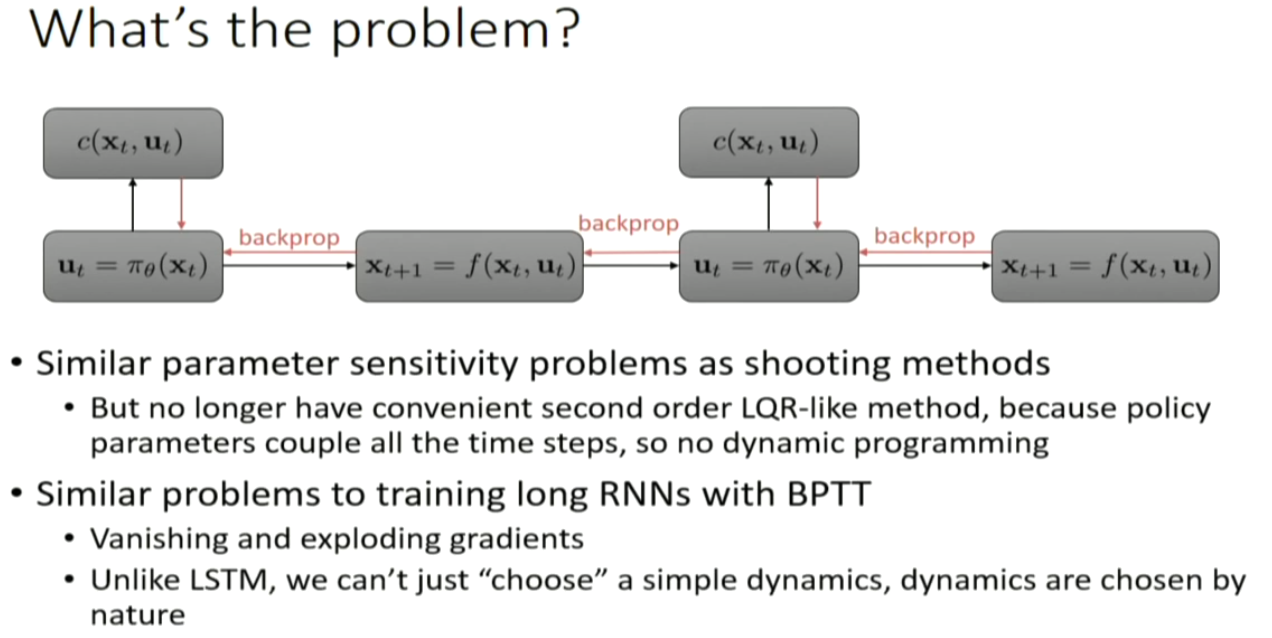
so, the dynamics can be quite messy, and backpropogating can be quite problematic.
sudden change in velocity and so on. schochastic system. gradient descent can be tough.
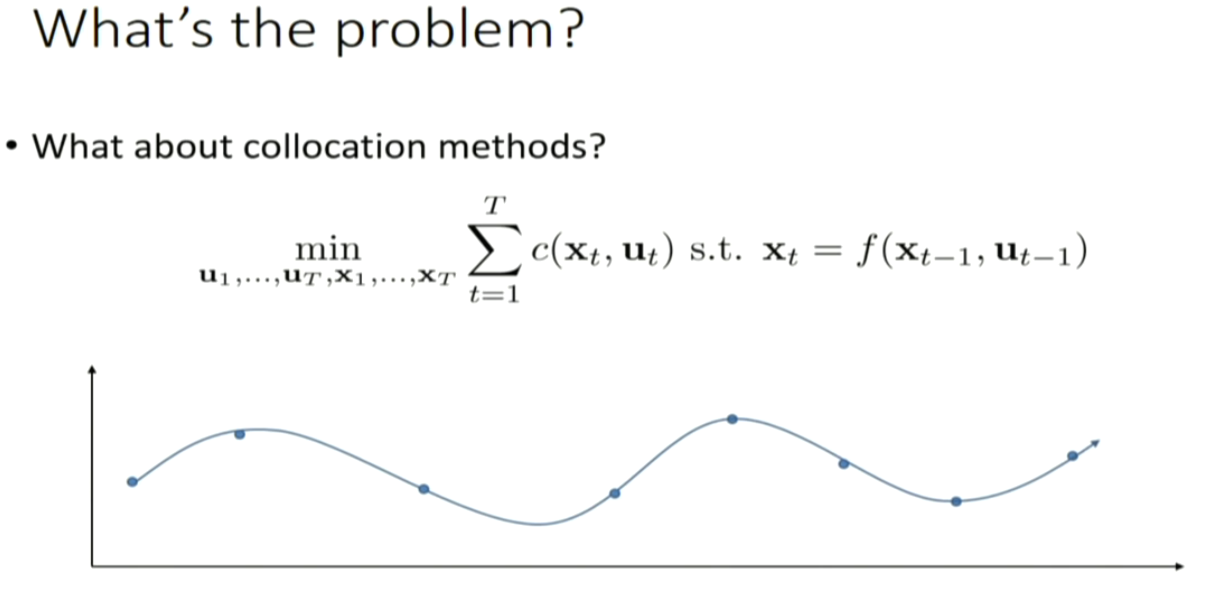
can we apply this trajectory optimization method to optimize policy?

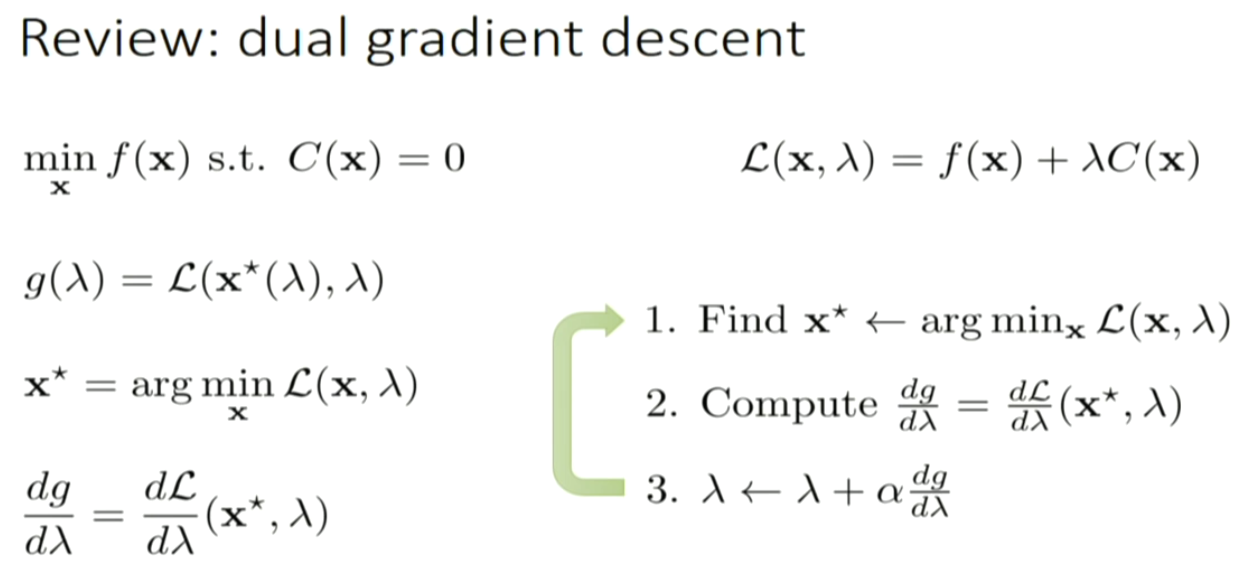




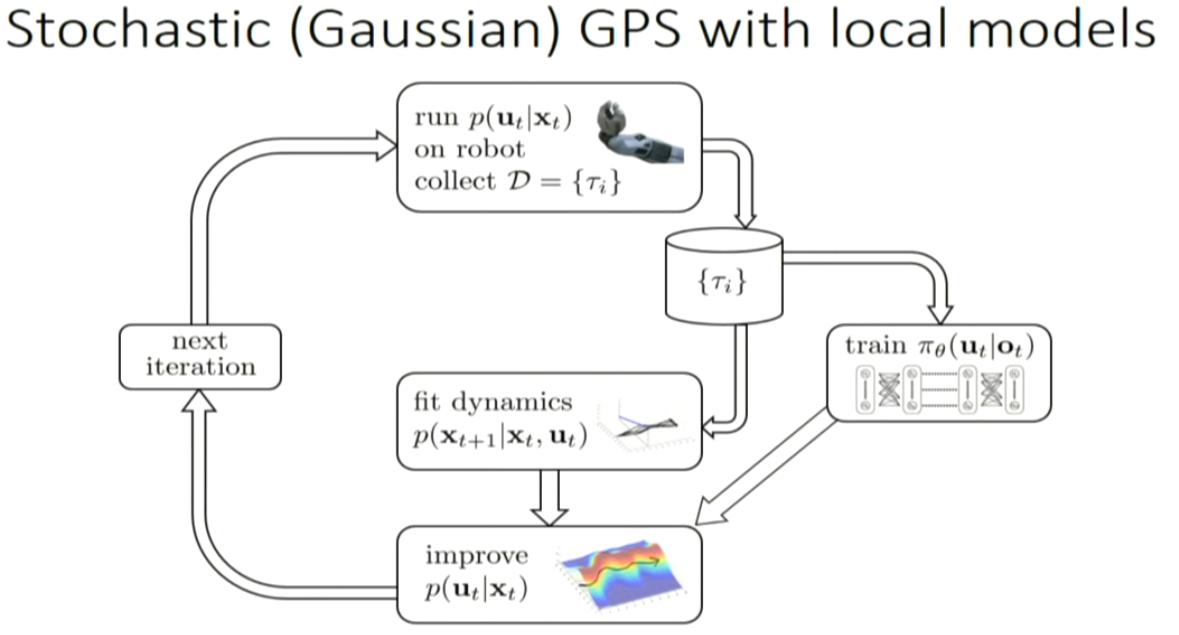
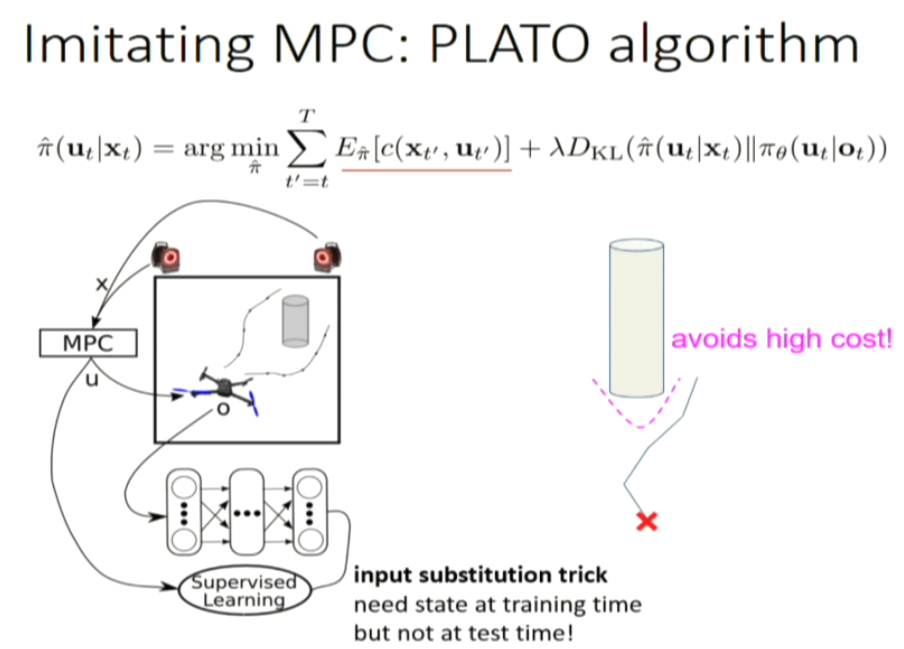
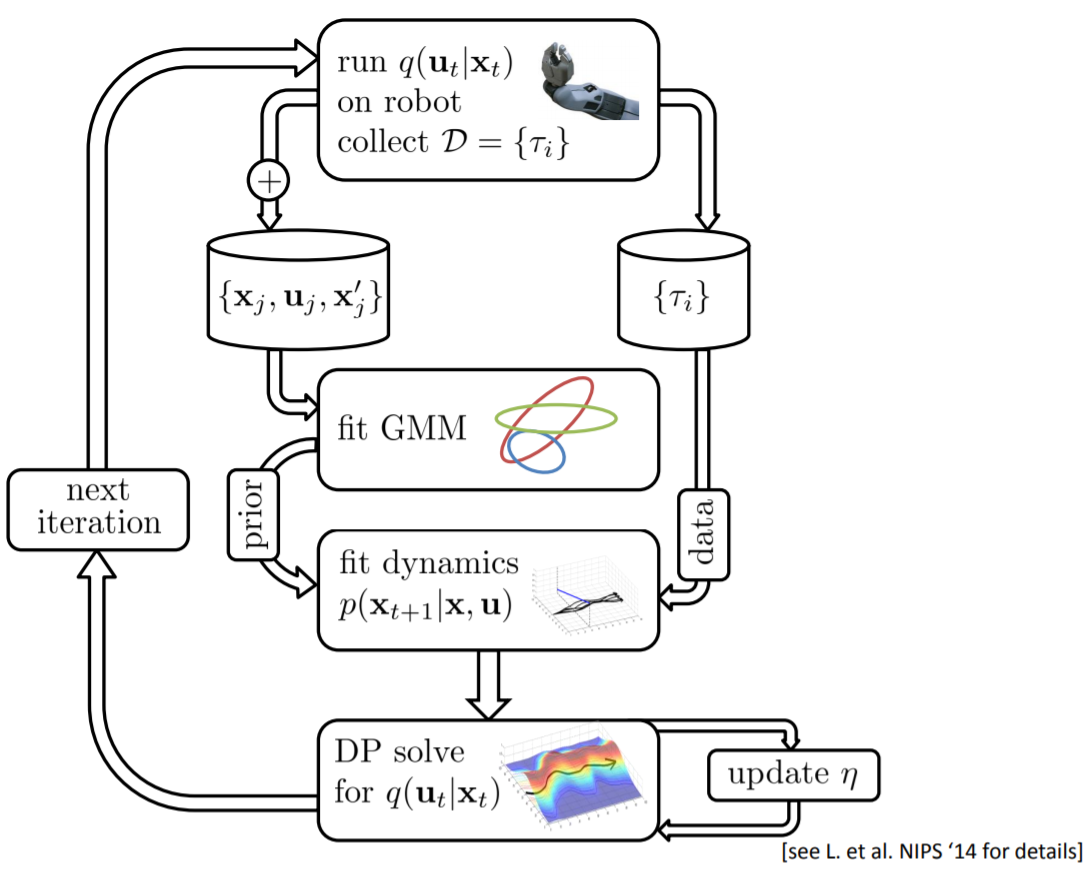
GPS: guided policy search
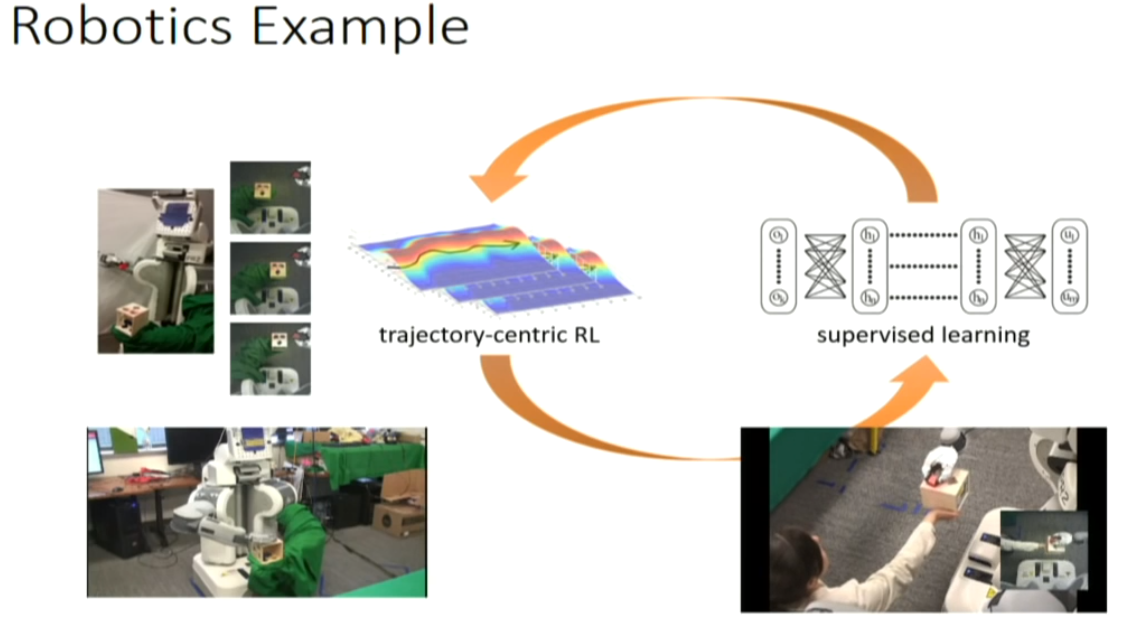
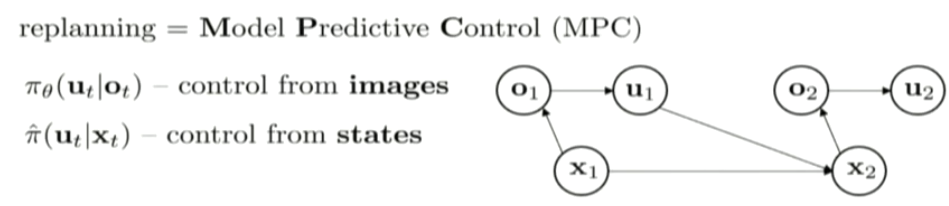
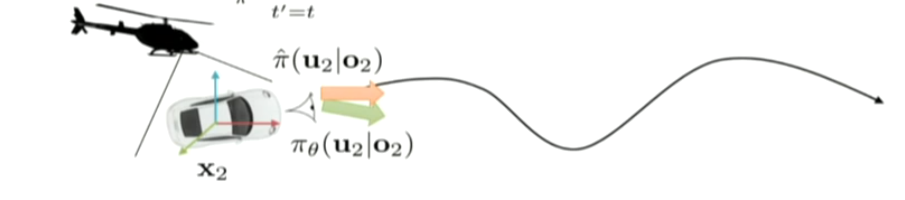
in this case, ot is from the camera and the joint velocity















https://katefvision.github.io/katefSlides/imitate_controlers_katef.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









